Download to read offline

![Probabilistic Classification Data
[UCI Machine Learning Repository]
Samples
Input Output
Neural Nets
HMMs
Naive Bayesian](https://image.slidesharecdn.com/visualizingprobabilisticclassificationdatainweka-191128115625/85/Visualizing-probabilistic-classification-data-in-weka-4-320.jpg)





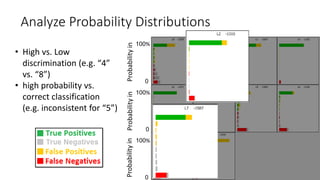
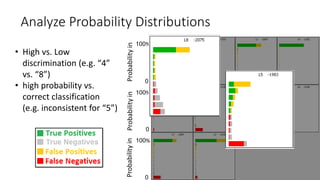

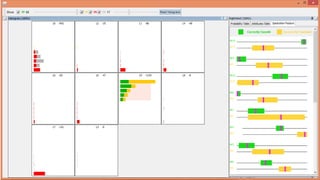




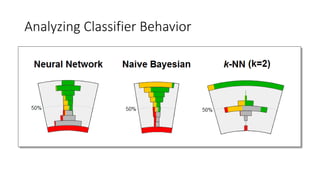













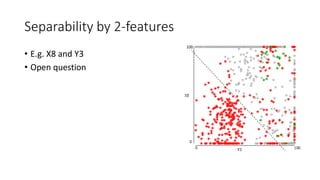





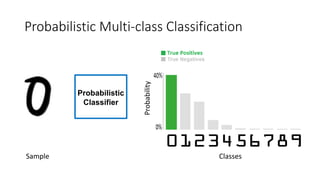
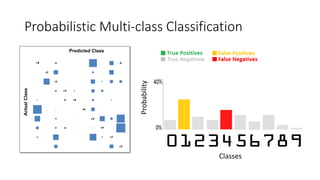
This document discusses the design, implementation, and testing of a visual inspection tool for probabilistic classification data in Weka, supervised by Dr. Bilal Alsallakh. It highlights the tool's capability to analyze classifier behavior, improve classification performance, and guide future improvements through interactive exploration of classification results. The implementation is designed to be modular, facilitating integration with other data mining frameworks.
















![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)





























