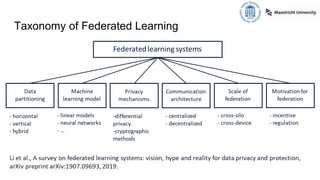
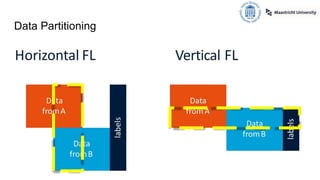
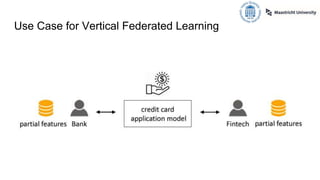
The document presents an overview of vertical federated learning (VFL), which involves multiple clients collaborating to solve machine learning problems while keeping their data local. It details the steps in VFL, including secure data alignment, model training, and evaluation, while also discussing various existing VFL algorithms and challenges such as communication overhead and model fairness. Additionally, it highlights incentive allocation mechanisms for participating clients and emphasizes the need for efficient methods to address open challenges in VFL.























































![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)



















































