Download as PDF, PPTX







![15 | © Copyright 11/17/23 Zilliz
15 | © Copyright 11/17/23 Zilliz
Semantic Similarity
Image from Sutor et al
Woman = [0.3, 0.4]
Queen = [0.3, 0.9]
King = [0.5, 0.7]
Woman = [0.3, 0.4]
Queen = [0.3, 0.9]
King = [0.5, 0.7]
Man = [0.5, 0.2]
Queen - Woman + Man = King
Queen = [0.3, 0.9]
- Woman = [0.3, 0.4]
[0.0, 0.5]
+ Man = [0.5, 0.2]
King = [0.5, 0.7]
Man = [0.5, 0.2]](https://image.slidesharecdn.com/rageval-240718172751-b7780082/85/Retrieval-Augmented-Generation-Evaluation-with-Ragas-15-320.jpg)
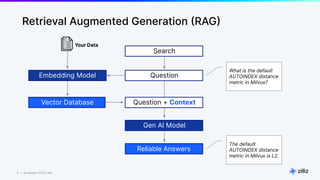
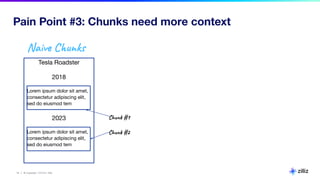
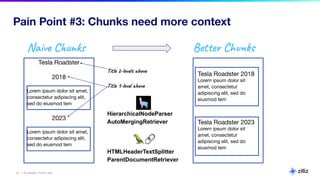
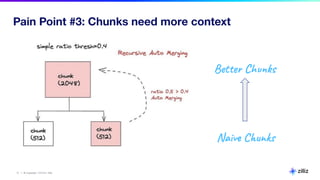

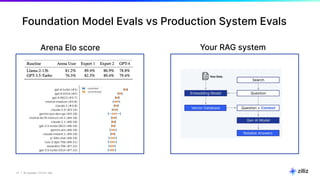

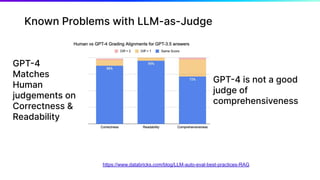
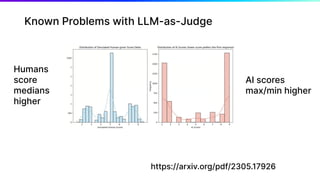
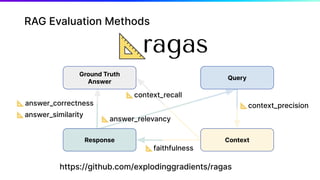



The document discusses various aspects of generative AI, including AI hallucinations and Retrieval Augmented Generation (RAG) techniques. It outlines challenges in data retrieval and evaluation methods for AI performance, highlighting the importance of context in processing unstructured data. Additionally, it presents insights into vector databases and the implications of using large language models (LLMs) for assessing AI-generated content.























































































