Download as PDF, PPTX











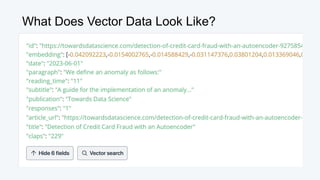
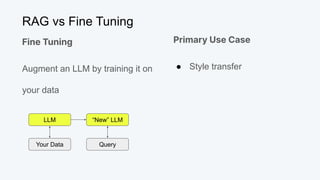
![Semantic Similarity
Image from Sutor et al
Woman = [0.3, 0.4]
Queen = [0.3, 0.9]
King = [0.5, 0.7]
Woman = [0.3, 0.4]
Queen = [0.3, 0.9]
King = [0.5, 0.7]
Man = [0.5, 0.2]
Queen - Woman + Man = King
Queen = [0.3, 0.9]
- Woman = [0.3, 0.4]
[0.0, 0.5]
+ Man = [0.5, 0.2]
King = [0.5, 0.7]
Man = [0.5, 0.2]](https://image.slidesharecdn.com/beyondragvectordatabases-240422205449-15eb19b2/85/Beyond-Retrieval-Augmented-Generation-RAG-Vector-Databases-13-320.jpg)

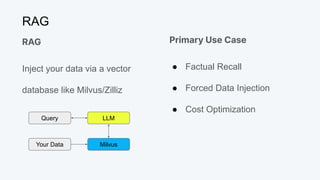
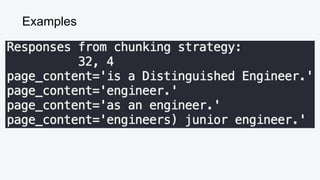
![Vector Similarity Metric: L2 (Euclidean)
Queen = [0.3, 0.9]
King = [0.5, 0.7]
d(Queen, King) = √(0.3-0.5)2
+ (0.9-0.7)2
= √(0.2)2
+ (0.2)2
= √0.04 + 0.04
= √0.08 ≅ 0.28](https://image.slidesharecdn.com/beyondragvectordatabases-240422205449-15eb19b2/85/Beyond-Retrieval-Augmented-Generation-RAG-Vector-Databases-15-320.jpg)
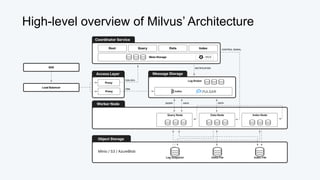
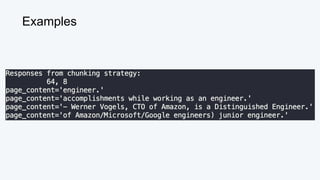
![Vector Similarity Metric: Inner Product (IP)
Queen = [0.3, 0.9]
King = [0.5, 0.7]
Queen · King = (0.3*0.5) + (0.9*0.7)
= 0.15 + 0.63 = 0.78](https://image.slidesharecdn.com/beyondragvectordatabases-240422205449-15eb19b2/85/Beyond-Retrieval-Augmented-Generation-RAG-Vector-Databases-16-320.jpg)
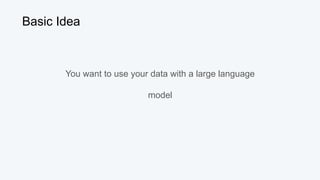
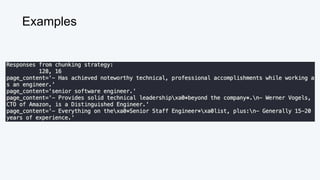
![Queen = [0.3, 0.9]
King = [0.5, 0.7]
Vector Similarity Metric: Cosine
𝚹
cos(Queen, King) = (0.3*0.5)+(0.9*0.7)
√0.32
+0.92
* √0.52
+0.72
= 0.15+0.63 _
√0.9 * √0.74
= 0.78 _
√0.666
≅ 0.03](https://image.slidesharecdn.com/beyondragvectordatabases-240422205449-15eb19b2/85/Beyond-Retrieval-Augmented-Generation-RAG-Vector-Databases-17-320.jpg)


































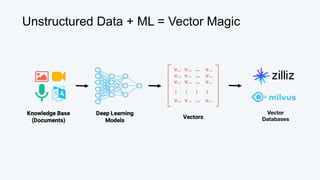
The document discusses the significance and workings of vector databases, highlighting their ability to analyze vast amounts of unstructured data, which constitutes 80% of global data by 2025. It explains various vector similarity metrics, provides examples of use cases such as semantic search and recommendation systems, and outlines the architecture and advantages of using Milvus/Zilliz for large-scale data management. Vector databases are promoted as a solution for efficient storage, indexing, and querying of vector embeddings from unstructured data.



















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



