Download as PDF, PPTX





![18 | © Copyright 2024 Zilliz
18
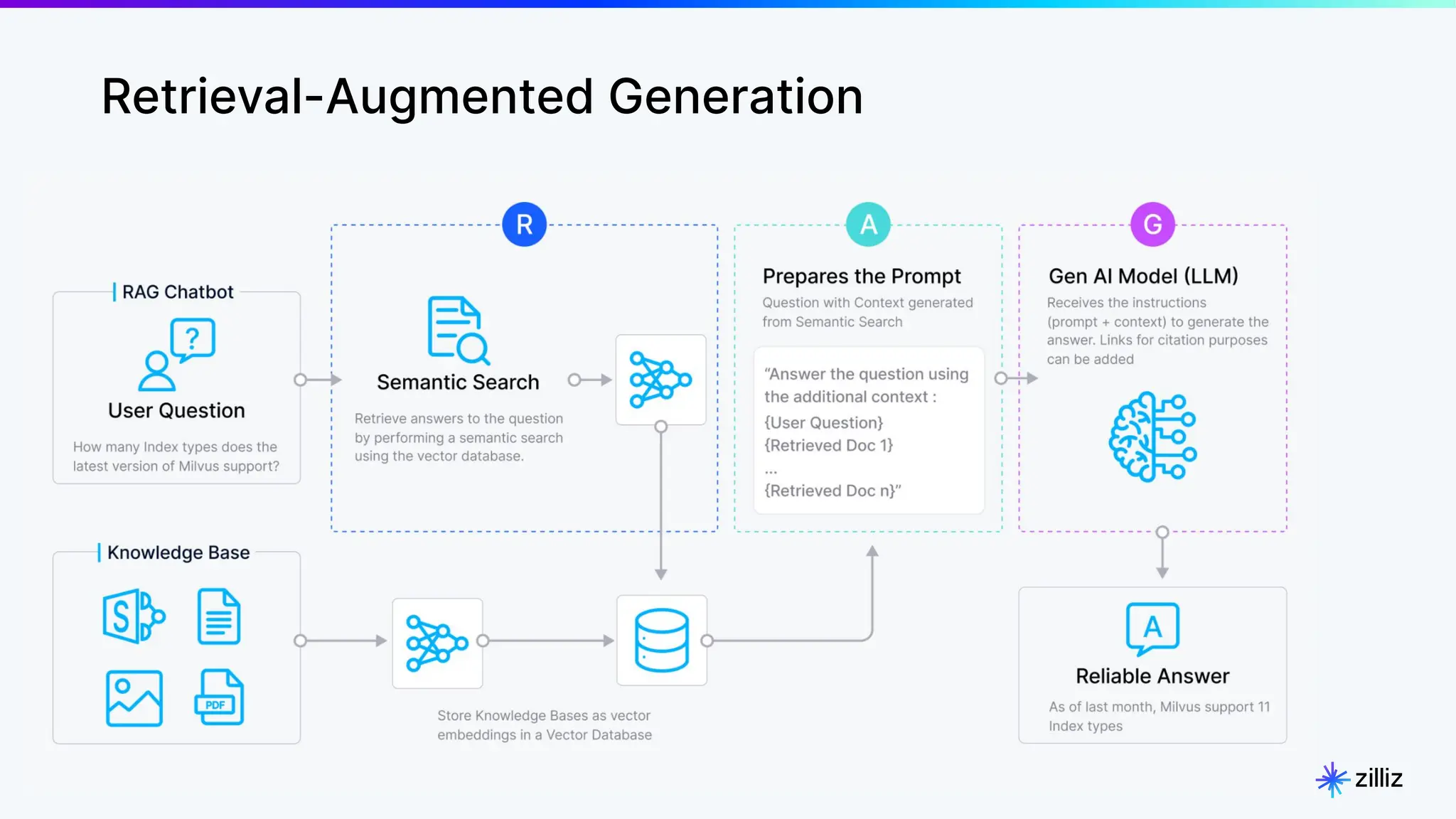
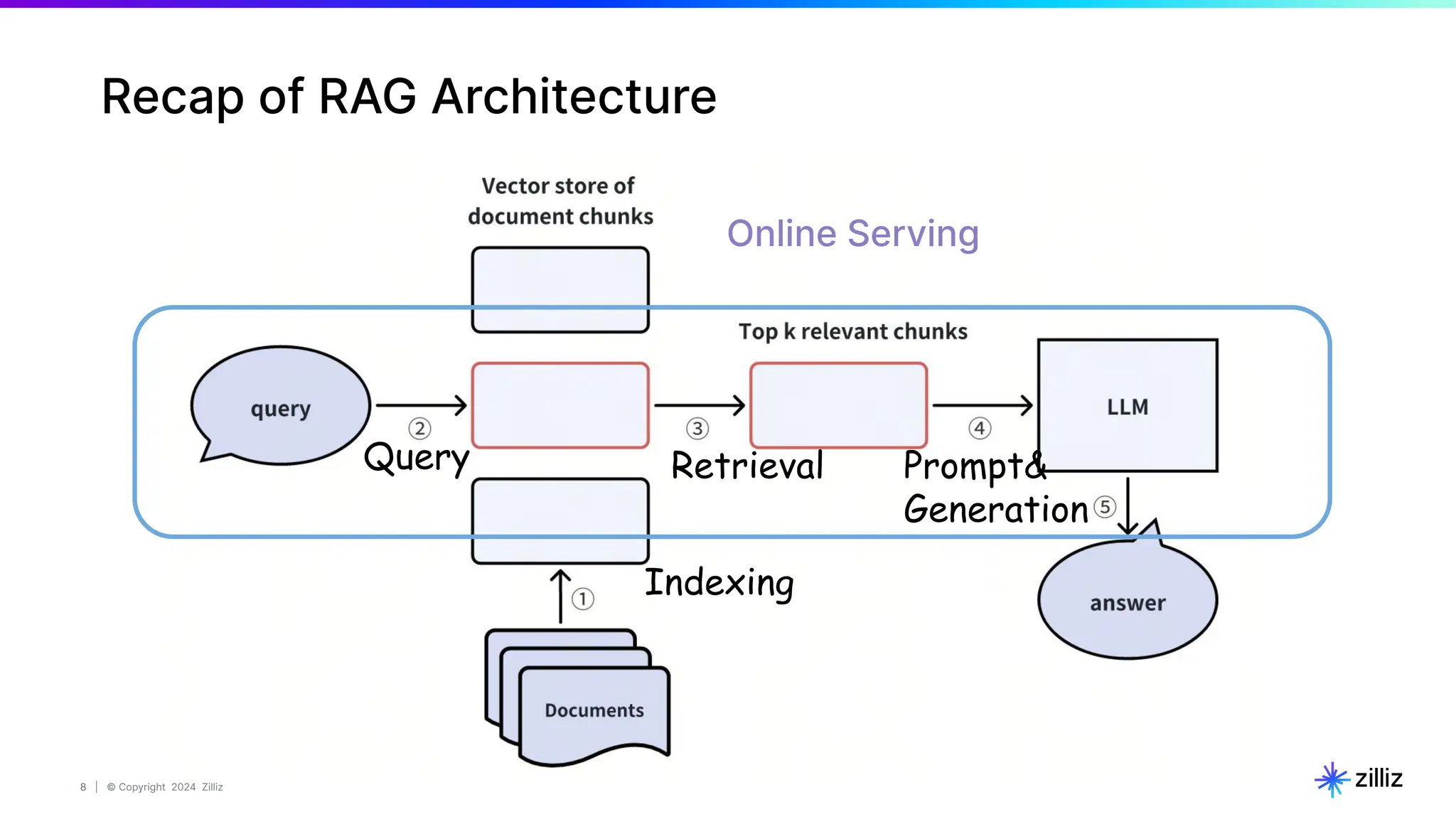
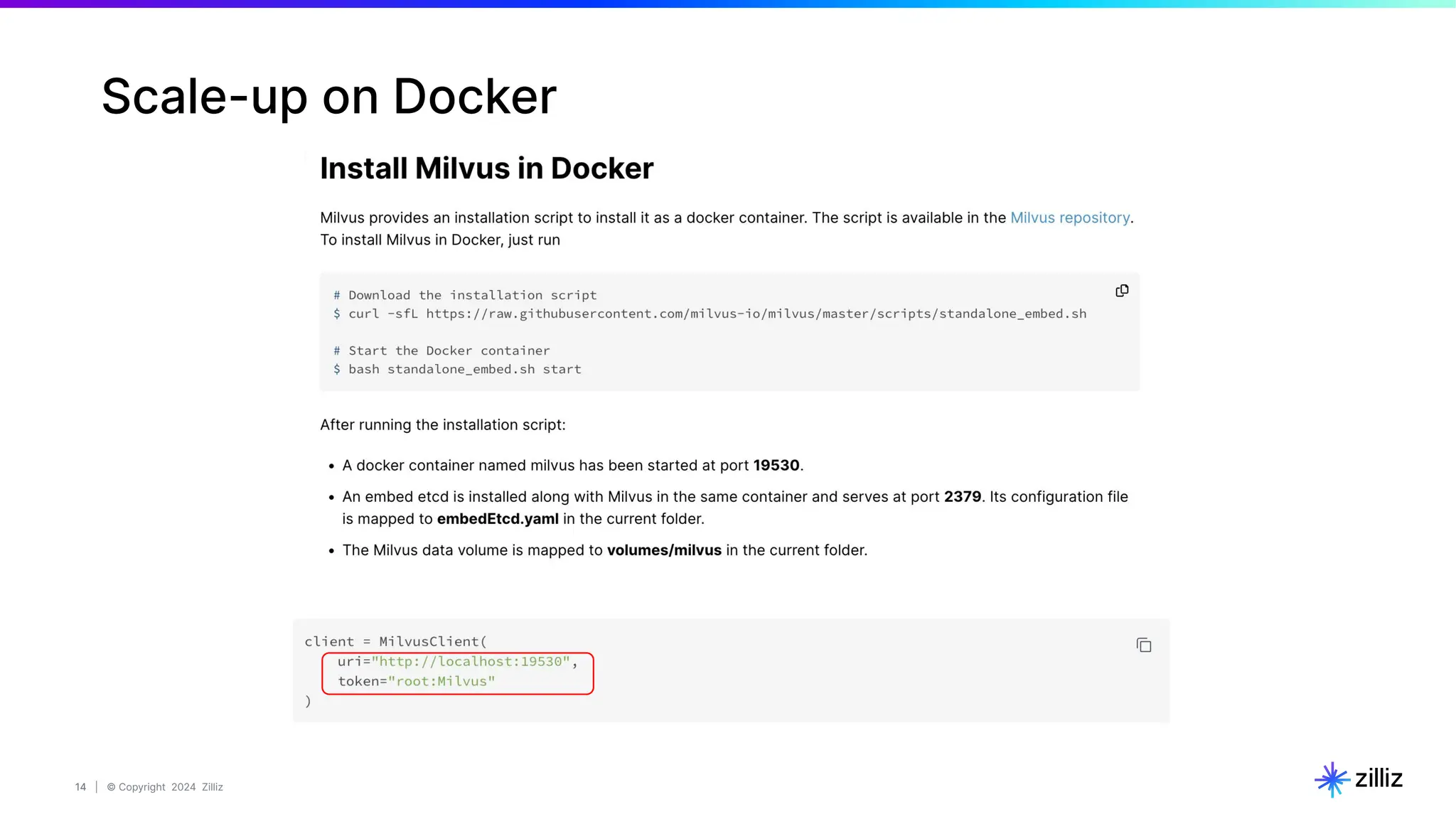
Create a Milvus Collection
# STEP 1. Connect to milvus
connection = connections.connect(
alias="default",
host='localhost', # or '0.0.0.0' or 'localhost'
port='19530'
)
# STEP 2. Create a new collection and build index
EMBEDDING_DIM = 256
MAX_LENGTH = 65535
# Step 2.1 Define the data schema for the new Collection.
fields = [
# Use auto generated id as primary key
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="text_vector", dtype=DataType.FLOAT_VECTOR, dim=EMBEDDING_DIM),
FieldSchema(name="image_vector", dtype=DataType.FLOAT_VECTOR, dim=EMBEDDING_DIM),
FieldSchema(name="chunk", dtype=DataType.VARCHAR, max_length=MAX_LENGTH),
FieldSchema(name="image_filepath", dtype=DataType.VARCHAR, max_length=MAX_LENGTH),
]
schema = CollectionSchema(fields, "")
# Step 2.2 create collection
col = Collection(“Demo_multimodal”, schema)
# Step 2.3 Build index for both vector columns .
image_index = {"metric_type": "COSINE"}
col.create_index("image_vector", image_index)
text_index = {"metric_type": "COSINE"}
col.create_index("text_vector", text_index)
col.load()](https://image.slidesharecdn.com/milvus0625meetup-240627184522-08110990/75/Multimodal-Retrieval-Augmented-Generation-RAG-with-Milvus-18-2048.jpg)
![19 | © Copyright 2024 Zilliz
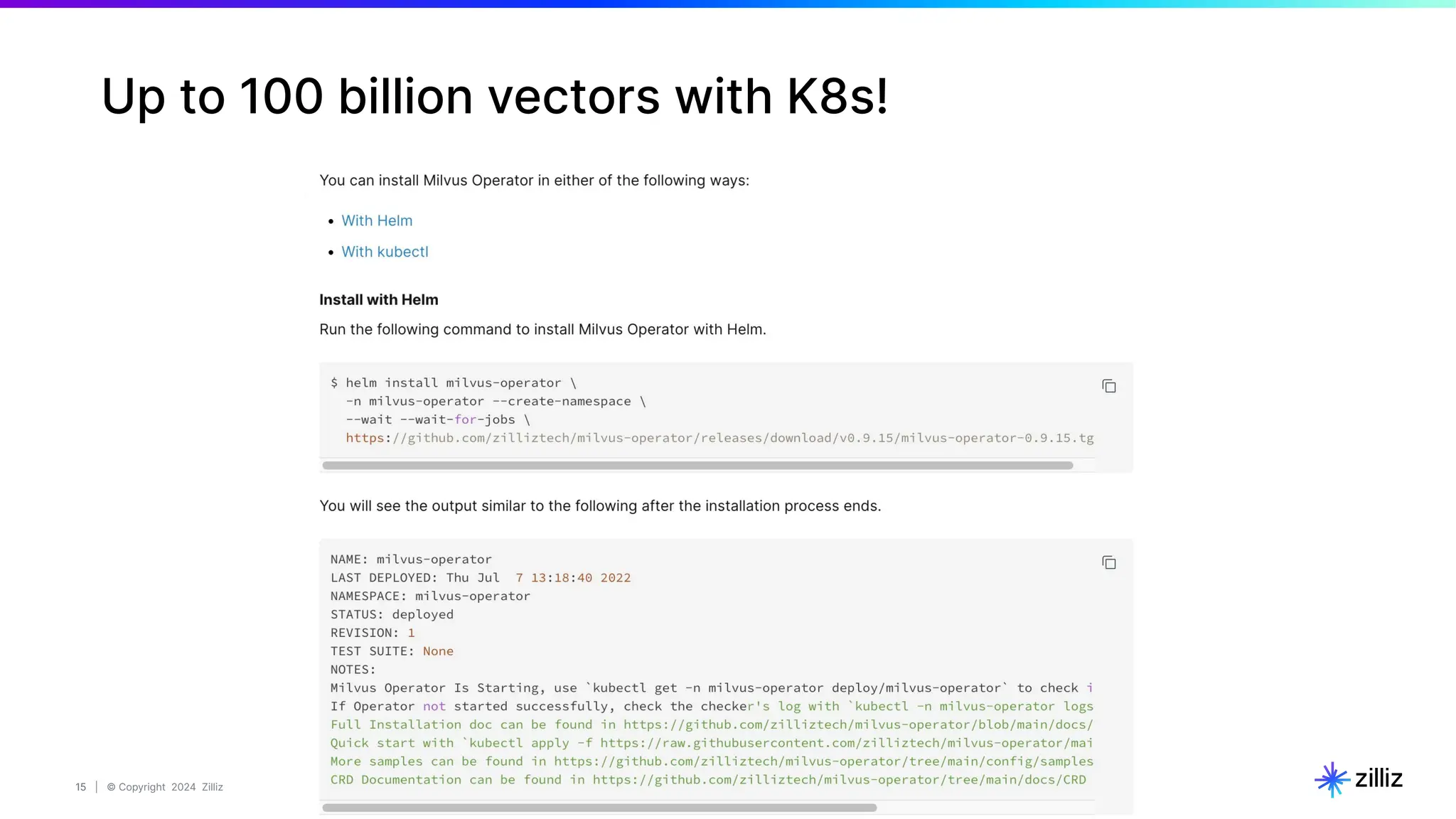
19
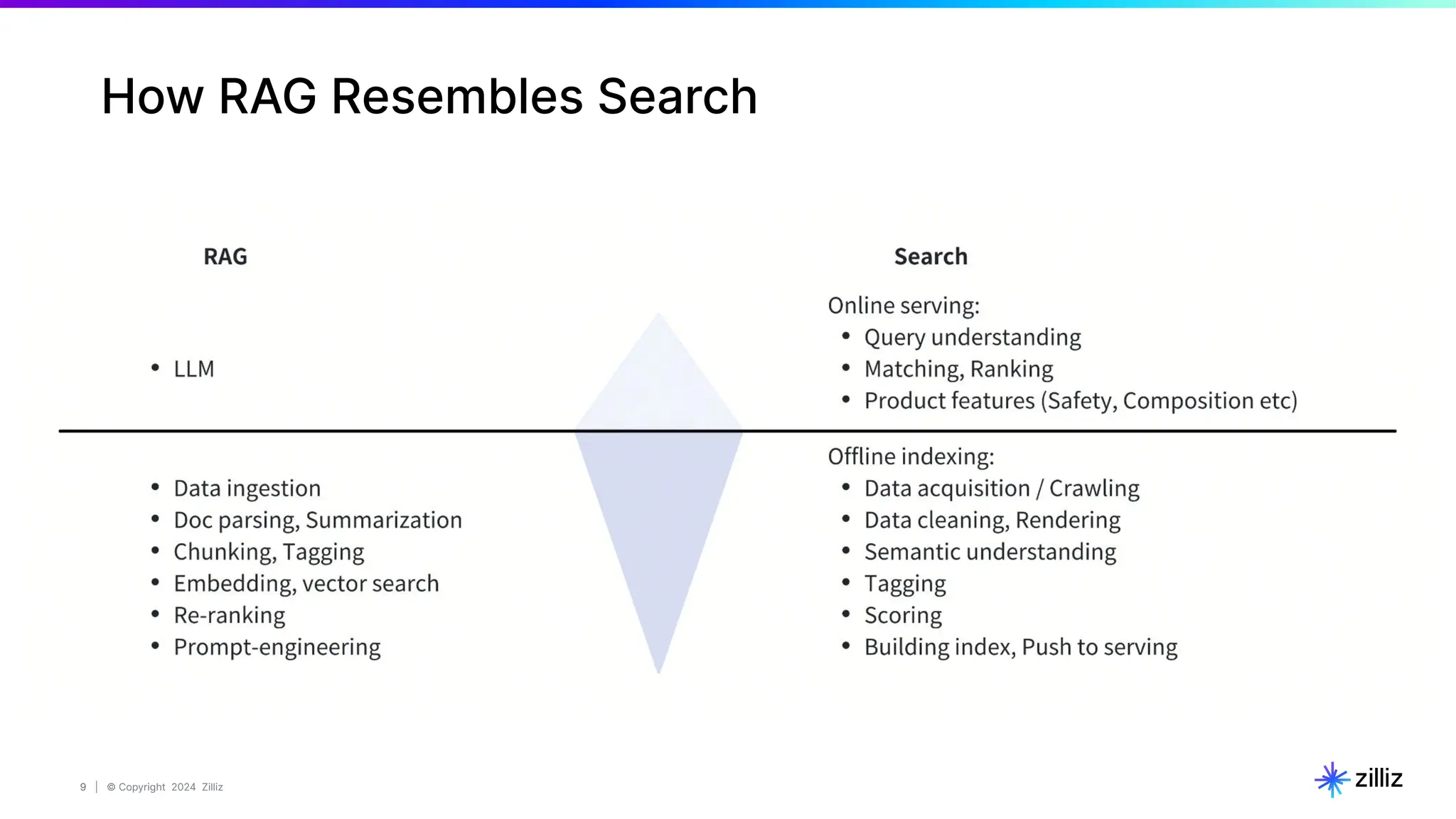
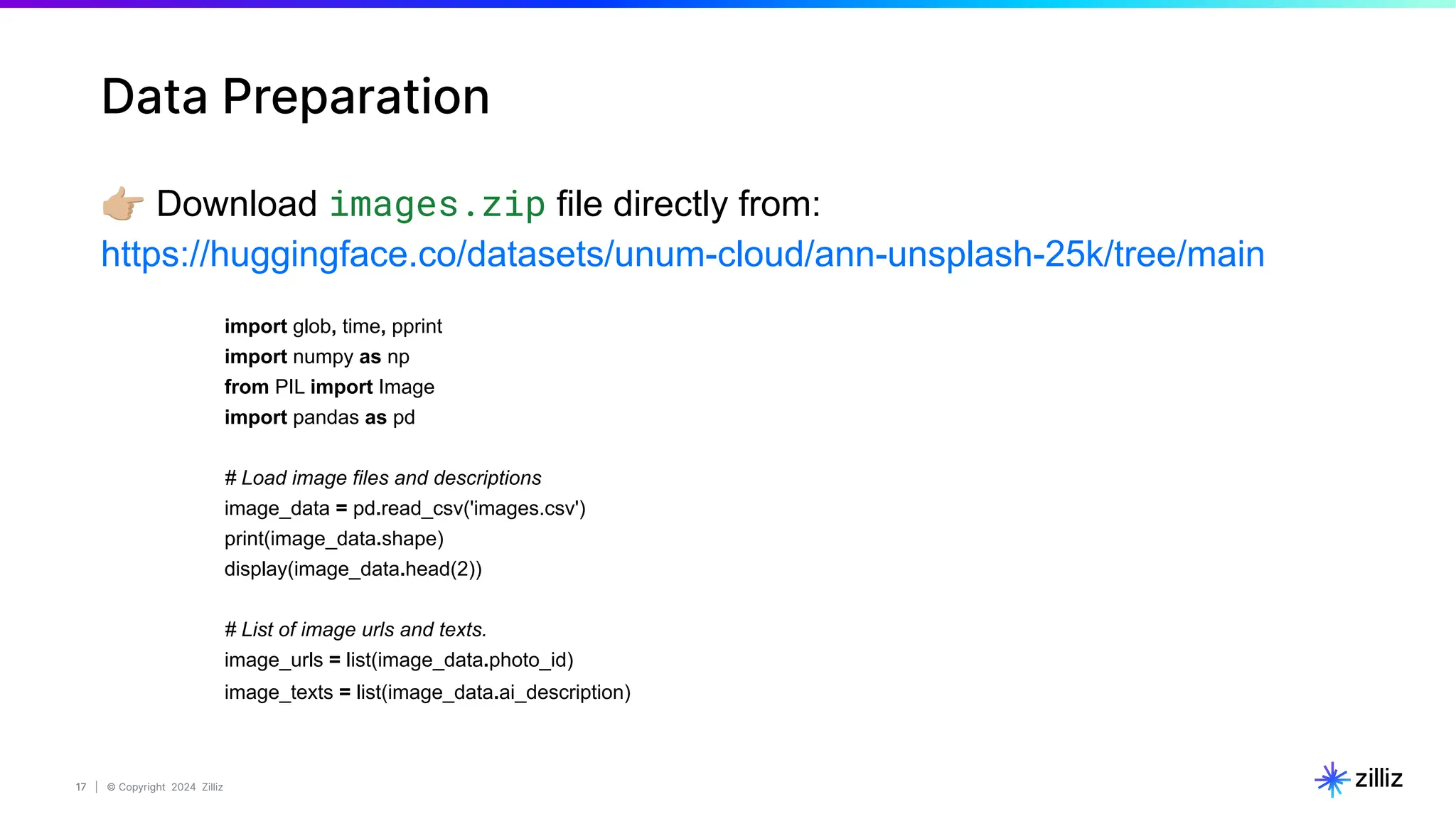
Data Vectorization & insertion
# STEP 4. Insert data into milvus OR zilliz.
# Prepare data batch.
chunk_dict_list = []
for chunk, img_url, img_embed, text_embed in zip(
batch_texts,
batch_urls,
image_embeddings, text_embeddings):
# Assemble embedding vector, original text chunk, metadata.
chunk_dict = {
'chunk': chunk,
'image_filepath': img_url,
'text_vector': text_embed,
'image_vector': img_embed
}
chunk_dict_list.append(chunk_dict)
# Actually insert data batch.
# If the data size is large, try bulk_insert()
col.insert(data=chunk_dict_list)
# STEP 3. Data vectorization(i.e. embedding).
image_embeddings, text_embeddings = embedding_model(
batch_images=batch_images,
batch_texts=batch_texts)](https://image.slidesharecdn.com/milvus0625meetup-240627184522-08110990/75/Multimodal-Retrieval-Augmented-Generation-RAG-with-Milvus-19-2048.jpg)
![20 | © Copyright 2024 Zilliz
20
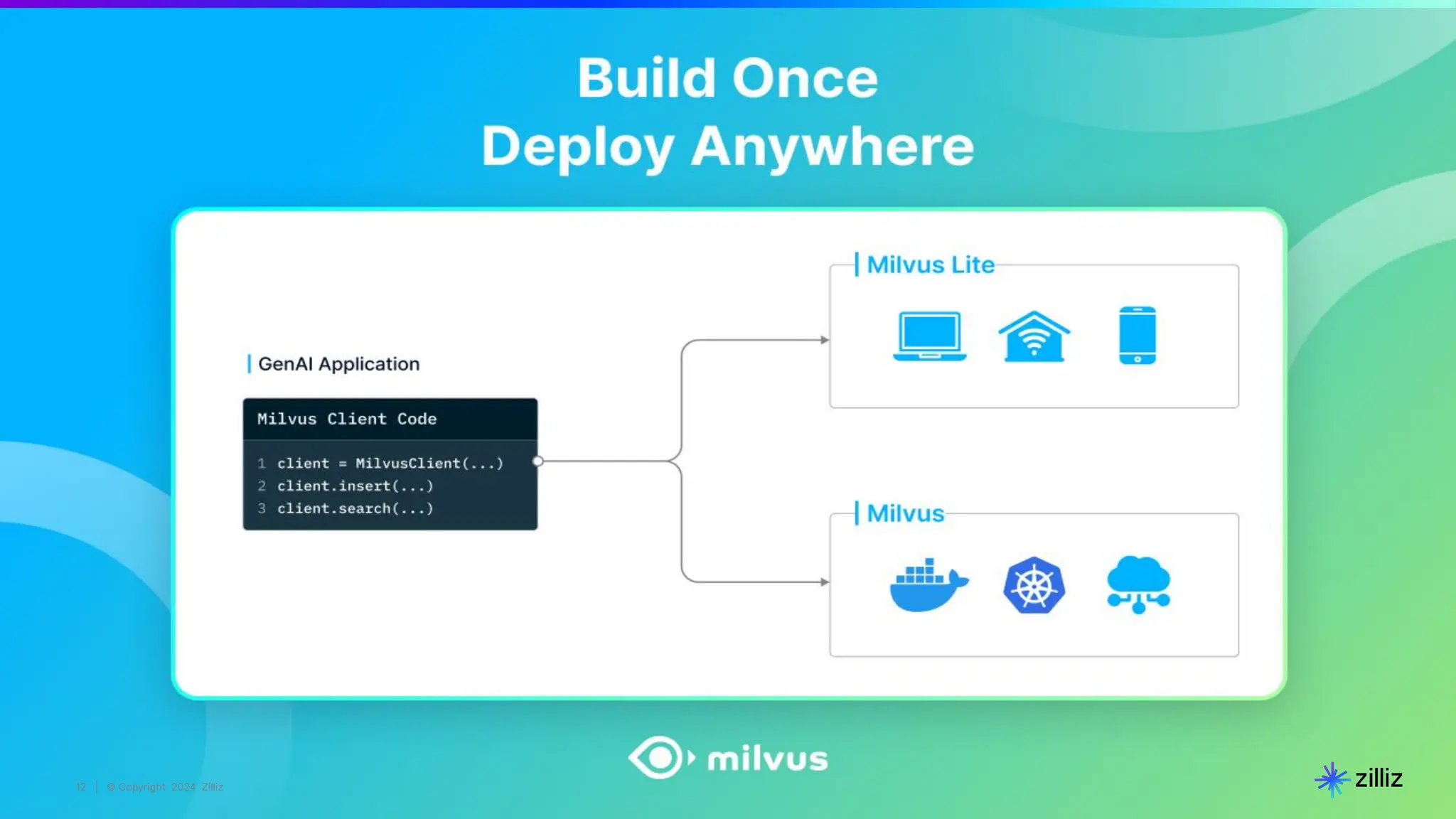
# STEP 4. hybrid_search() is the API for multimodal search
results = col.hybrid_search(
reqs=[image_req, text_req],
rerank=RRFRanker(),
limit=top_k,
output_fields=output_fields)
Final step: Search](https://image.slidesharecdn.com/milvus0625meetup-240627184522-08110990/75/Multimodal-Retrieval-Augmented-Generation-RAG-with-Milvus-20-2048.jpg)
![21 | © Copyright 2024 Zilliz
21
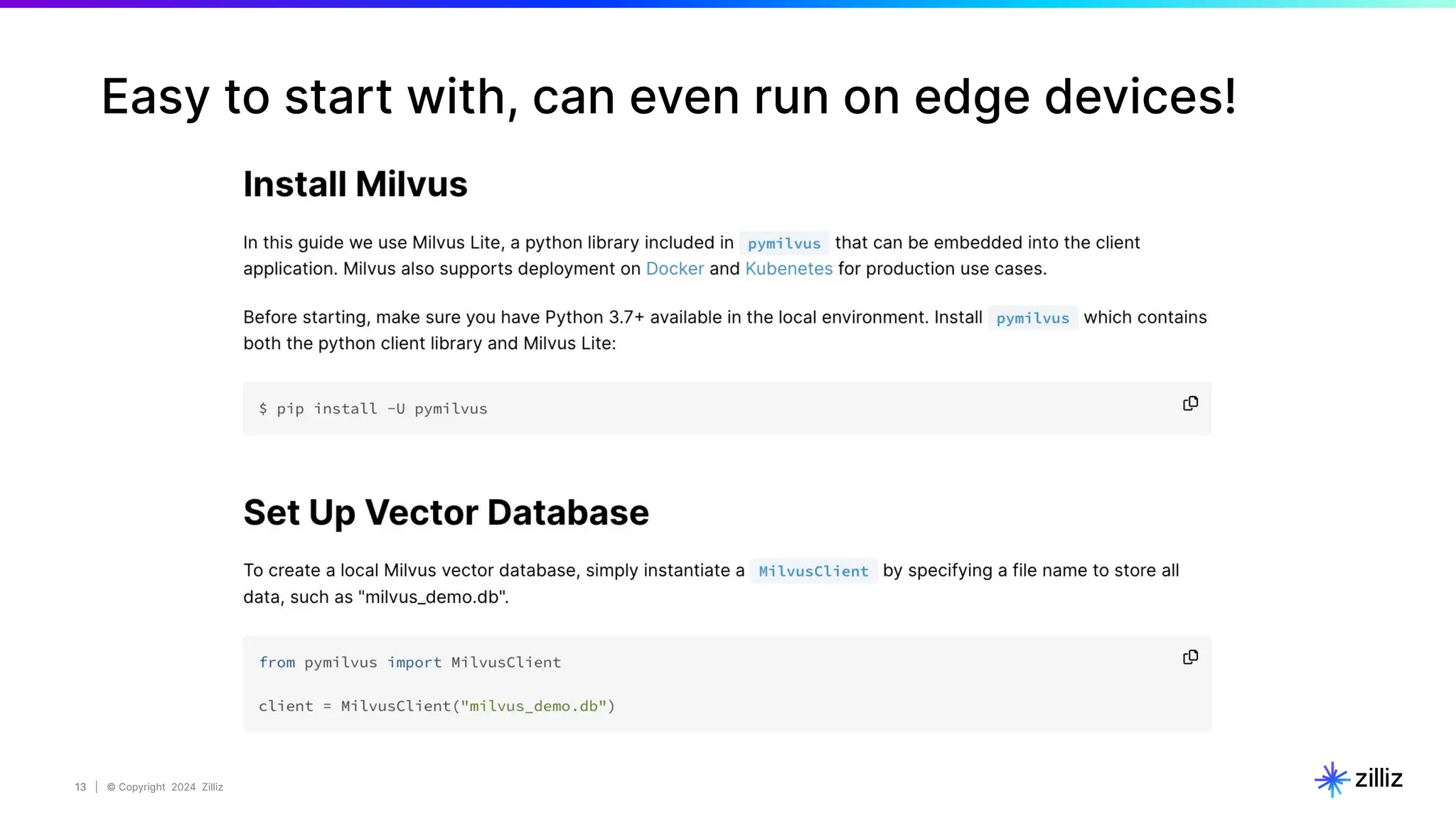
[Multimodal] search with text-only query
Query = "feuilles brunes pendant la journée"
(i.e. "brown leaves during daytime")](https://image.slidesharecdn.com/milvus0625meetup-240627184522-08110990/75/Multimodal-Retrieval-Augmented-Generation-RAG-with-Milvus-21-2048.jpg)
![22 | © Copyright 2024 Zilliz
22
[Multimodal] search with image-only query
[Query is an image]](https://image.slidesharecdn.com/milvus0625meetup-240627184522-08110990/75/Multimodal-Retrieval-Augmented-Generation-RAG-with-Milvus-22-2048.jpg)
![23 | © Copyright 2024 Zilliz
23
[Multimodal] search with text + image query
Query = text + image
1. "silhouette d'une personne assise sur une
roche au couche du soleil"
(i.e. "silhouette of person sitting on rock formation
during golden hour")
2. Image below
Result](https://image.slidesharecdn.com/milvus0625meetup-240627184522-08110990/75/Multimodal-Retrieval-Augmented-Generation-RAG-with-Milvus-23-2048.jpg)

![26 | © Copyright 2024 Zilliz
26 | © Copyright 9/25/23 Zilliz
26
curl --request POST
--url “${MILVUS_HOST}:${MILVUS_PORT}/v2/vectordb/entities/advanced_search”
--header “Authorization: Bearer ${TOKEN}”
--header “accept: application/json”
--header “content-type: application/json”
-d
{
"collectionName": "book",
"search": {
"search_by": {
"field": "book_intro_vector",
"data": [1, 2, ...],
},
"search_by": {
"field": "book_cover_vector",
"data": [2, 3, ...],
},
},
"rerank": {
"strategy": "rrf",
},
"limit": 10,
}
Retrieve Params
Re-rank Params](https://image.slidesharecdn.com/milvus0625meetup-240627184522-08110990/75/Multimodal-Retrieval-Augmented-Generation-RAG-with-Milvus-26-2048.jpg)

The document discusses Retrieval-Augmented Generation (RAG) with Milvus, focusing on multimodal retrieval that combines text and images for search queries. It outlines the architecture, indexing, data preparation, vectorization, and search procedures for implementing RAG using Milvus, including integration with Docker and Kubernetes for scalability. Additionally, it provides sample code for connecting to a Milvus instance, creating collections, and executing hybrid searches with various query formats.










































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












