Today : 지도학습 (supervised learning)
Regression problem (response is quantitative)
▶ 성인의 자아 효능감과 사회적 자본이 (지각된) 건강 수준에 미치는 영향?
▶ y = 건강 수준, x = (자아 효능감, 사회적 자본)
▶ y is quantitative
▶ Might use a linear regression.
▶ 사진을 몇장 올리면 좋아요를 가장 많이 받을까?
▶ y = 좋아요, x = 사진 수
▶ y is quantitative
▶ Might use a nonlinear regression.
3 / 27
5.
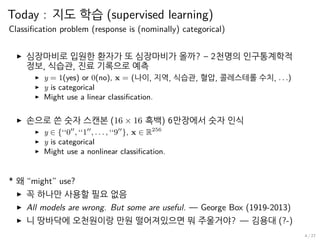
Today : 지도학습 (supervised learning)
Classification problem (response is (nominally) categorical)
▶ 심장마비로 입원한 환자가 또 심장마비가 올까? – 2천명의 인구통계학적
정보, 식습관, 진료 기록으로 예측
▶ y = 1(yes) or 0(no), x = (나이, 지역, 식습관, 혈압, 콜레스테롤 수치, . . .)
▶ y is categorical
▶ Might use a linear classification.
▶ 손으로 쓴 숫자 스캔본 (16 × 16 흑백) 6만장에서 숫자 인식
▶ y ∈ {‘‘0′′
, ‘‘1′′
, . . . , ‘‘9′′
}, x ∈ R256
▶ y is categorical
▶ Might use a nonlinear classification.
* 왜 “might” use?
▶ 꼭 하나만 사용할 필요 없음
▶ All models are wrong. But some are useful. — George Box (1919-2013)
▶ 니 땅바닥에 오천원이랑 만원 떨어져있으면 뭐 주울거야? — 김용대 (?-)
4 / 27
6.
Today’s storyline
회귀(Regression), 분류(classification)는손실함수를 적당히 정하면 다변수함수를
최소화하는 문제로 바뀐다.
▶ 표기법 (Notation)
▶ 모형 (Model)
▶ 손실함수 (Loss function)
▶ 최소화 (Minimization)
다음의 느낌적인 느낌을 논함. 자세한 안내는 전공과목 들으세요.
▶ 회귀/분류 방법론
▶ Linear regression ∋ 1. multiple linear regression
▶ Nonlinear regression ∋ 2. spline smoothing
▶ Linear classification ∋ 3. softmax classification (logistic regression)
▶ Nonlinear classification ∋ 4. (deep) feed-forward neural network
▶ 다변수함수 최적화 방법론
Not covered today
▶ 비-지도 학습 (unsupervised learning) — 차원 축소, 분포 추정, 군집 발견
▶ 강화 학습 (reinforcement learning) — 자동 제어, 알파고
5 / 27
7.
Setting repeated
모형
▶ Responsevariable : y ∈ R
▶ Quantitative or categorical
▶ Predictor variable : x = (x1, x2, . . . , xp)T
∈ Rp
▶ 모형 : y = f(x), y = f(x) + ϵ, or P(y | x) = f(x)
f is unknown – data-driven estimation
▶ Observed data : (x1, y1), (x2, y2), . . . , (xn, yn) (n data points)
▶ Assume f ∈ F (linear function, smooth function, ..)
▶ Define loss function : L(y, f(x)) — 여기서의 f는 위의 f와 같기도/다르기도
▶ Problem to be solved : ideally minimize E
[
L (y, f(x))
]
. In practice,
minimize
f∈F
1
n
n∑
i=1
L (yi, f(xi))
6 / 27
8.
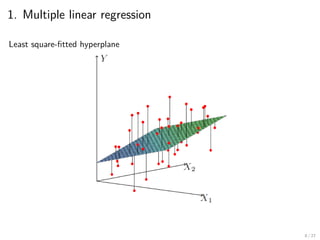
1. Multiple linearregression
Linear regression
▶ x ∈ Rp
, y ∈ R, y is quantitative (키, 몸무게, 점수, ...)
▶ 선형 모형
y = xT
β or y = xT
β + ϵ (β ∈ Rp
)
(intercept included in x without loss of generality)
▶ Given data (x1, y1), (x2, y2), . . . , (xn, yn),
▶ 최소제곱법 (least square method) :
minimize
β∈Rp
1
n
n∑
i=1
(yi − xT
i β)2
Remark.
▶ 손실함수로 L(y, t) = (y − t)2
사용. Mean trend 추적.
7 / 27
1. Multiple linearregression
Remark. 최소화하려는 함수는 β 의 함수
minimize
β∈Rp
1
n
n∑
i=1
(yi − xT
i β)2
최소화 방법
▶ In matrix form :
minimize
β∈Rp
1
n
[
βT
XT
Xβ − 2yT
Xβ + yT
y
]
▶ β 의 이차 형식(binary form)으로 쓸 수 있음
▶ (이차식이므로 당연히?) β 에 대한 볼록함수 (convex function)
▶ n > p이면 해가 유일하게 존재 : ˆβ = (XT
X)−1
XT
y
Not covered here
▶ 다른 손실함수
▶ 데이터에 선형모형이 적합한지 알아보는 방법 (모형 평가, model assessment)
▶ 유의미한 (βj ̸= 0인) 변수 찾아내기 (변수/모형 선택, model selection)
▶ n < p일 때의 추론 (고차원 회귀분석, high-dimensional regression)
▶ 상관관계 → 인과관계 (인과 추론, causal inference)
9 / 27
11.
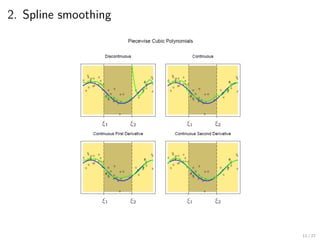
2. Spline smoothing
Recall.닫힌 구간 위의 연속함수는 다항함수(혹은 삼각함수)로 근사할 수 있다.
▶ Assume the feature is one-dimensional.
▶ Given data : {(xi, yi)}n
i=1, y quantitative
▶ Consider a function space F :=
{∑K
k=1 βkϕk(·) : β1, . . . , βK ∈ R
}
▶ Examples of basis {ϕk(·)}
▶ Trigonometric functions : {sin kx, cos kx}K
k=1
▶ Piecewise polynomials (Cubic splines here)
{
1, t, t2
, (t − ξ1)3
+ . . . , (t − ξK)3
+
}
(ξ1, . . . , ξK : 미리 정해진 점(knot))
10 / 27
2. Spline smoothing
▶가정 :
y = f(x) + ϵ , f ∈ F
⇐⇒ y =
K∑
k=1
βkϕk(x) + ϵ = ϕ(x)T
β + ϵ (β ∈ Rp
)
▶ 최소제곱법 (least square method) – 이후 계산은 선형회귀와 동일 :
minimize
β∈Rp
1
n
n∑
i=1
(yi − ϕ(xi)T
β)2
Not covered here
▶ 선형회귀에서의 고민은 기본
▶ Knot은 몇 개나 / 어떻게 선택하는가?
▶ Cubic spline 말고 다른 basis? (B-spline, wavelet, ...)
▶ Kernel smoothing
12 / 27
14.
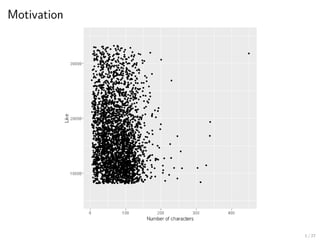
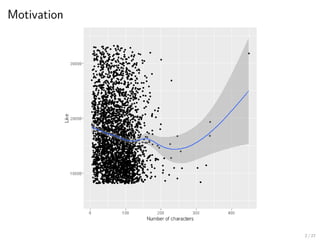
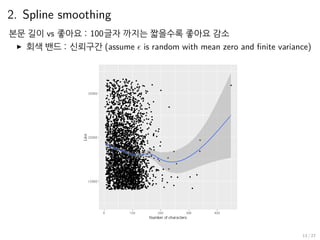
2. Spline smoothing
본문길이 vs 좋아요 : 100글자 까지는 짧을수록 좋아요 감소
▶ 회색 밴드 : 신뢰구간 (assume ϵ is random with mean zero and finite variance)
13 / 27
15.
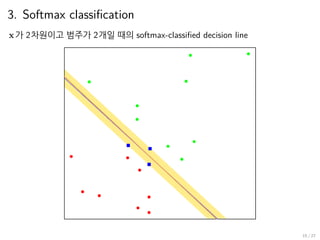
3. Softmax classification
▶a.k.a. logistic regression
▶ x ∈ Rp
, y ∈ R, y categorical (편의상 두 그룹 0, 1만)
▶ Given data {(xi, yi)}n
i=1
확률에 모델링 : P(yi = 1 | xi) =: pi, P(yi = 0 | xi) =: 1 − pi 라 하면 (0 < pi < 1)
log
pi
1 − pi
= xT
i β (β ∈ Rp
)
⇐⇒ pi =
exp(xT
i β)
1 + exp(xT
i β)
최대 가능도 방법 (maximum likelihood method) : ‘우리가 가진 데이터셋을 얻을
확률을 최대로 하는 parameter를 선택하자’
▶ Note : 각 yi 는 독립적으로 이항분포 B(1, pi) 따름 (given xi)
maximize
β∈Rp
n∏
i=1
pyi
(1 − p)1−yi
−n−1
log(·)
⇐⇒ minimize
β∈Rp
−
1
n
n∑
i=1
{
yi · xT
i β − log(1 + exp(xT
i β))
}
14 / 27
3. Softmax classification
minimize
β∈Rp
−
1
n
n∑
i=1
{
yi· xT
i β − log(1 + exp(xT
i β))
}
손실함수 : L(y, t) = −yt + log(1 + exp(t))
함수 최소화
▶ 명시적 해 존재하지 않음
▶ But β 에 대해 볼록함수 : d2
dt2 log(1 + exp(1 + t)) > 0 )
▶ 해에 수렴함이 보장되는 알고리즘 다수 존재
Not covered here & remarks
▶ y가 여러 값을 취해도 쉽게 확장 가능
▶ 지금은 확률에 모델링 : P(y = 1 | x) = f(x)
▶ Maximum likelihood : 매우 보편적이고 광범위하게 쓰이는 방법. 사실 least
square (at regression)도 ϵ에 정규분포 가정 주면 maximum likelihood와 동치
▶ y = f(x)로 직접 모델링하는 방법도 있음 (e.g. support vector machine)
▶ 다른 분류 방법들 : bagging, boosting, random forests..
16 / 27
18.
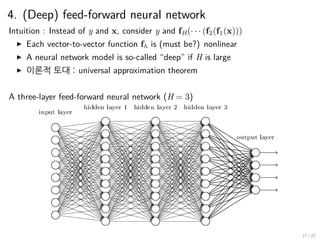
4. (Deep) feed-forwardneural network
Intuition : Instead of y and x, consider y and fH(· · · (f2(f1(x)))
▶ Each vector-to-vector function fh is (must be?) nonlinear
▶ A neural network model is so-called “deep” if H is large
▶ 이론적 토대 : universal approximation theorem
A three-layer feed-forward neural network (H = 3)
17 / 27
19.
4. (Deep) feed-forwardneural network
First H layers f1(·), f2(·), f3(·)
▶ Let x =: z(0)
, f1(z(0)
) =: z(1)
, · · · , f3(z(2)
) =: z(3)
,
▶ What does each z(h+1)
= fh+1(z(h)
) look like?
z(h+1)
:= (z
(h+1)
1 , z
(h+1)
2 , . . . , z(h+1)
ph+1
),
z
(h+1)
k = σ
(
α
(h+1)
k + (z(h)
)T
β
(h+1)
k
)
, k = 1, 2, . . . , ph+1
where σ(·) (활성함수, activation function) is known, nonlinear, and
monotone-increasing.
▶ e.g. σ(t) : 1/(1 + e−t
), tanh(t), t+ = max{t, 0}, etc.
▶ Thus, each fh is determined by {α
(h+1)
k , β
(h+1)
k }
ph+1
k=1 given data and activation
function — (1 + ph) · ph+1 parameters in total.
The last (output) layer
▶ y and z(H)
: use ordinary regression/classification scheme
18 / 27
20.
4. (Deep) feed-forwardneural network
손실함수 최소화 :
minimize
all involved parameters
1
n
n∑
i=1
L
(
yi, g(fH(· · · (f2(f1(xi)))))
)
▶ 손실함수 L(·, ·) : y가 quantitative냐 (the squared loss), categorical이냐 (the
negative Bernoulli likelihood loss)에 따라 선택
최소화 문제를 풀때
▶ Parameter들에 대한 볼록함수가 아님 – 극소점 다수 존재
▶ 손실함수만 낮으면 됐지
▶ non-convex 함수에서의 최적화 방법론 개발
▶ Parameter 개수가 많음 – 함수의 class가 커지나 과적합 우려, 계산량 급증
▶ 데이터를 많이 (n을 키운다)
▶ GPU로 분산계산
▶ Neural network 구조 활용한 꼼수 개발 (back-propagation, symbolic calculation,
batch normalization...)
19 / 27
21.
* Impact ofdeep neural networks
▶ Input data type 및 원하는 output에 따라 다양한 neural network 제안됨
▶ 특히 사진, 동영상, 소리, 문서
▶ Convolutional neural networks (CNN), Recurrent neural networks (RNN), ...
20 / 27
22.
Summary of thefunction approximations
데이터가 주어지면 함수 최소화 문제로 바뀜 (θ : vector of all involved parameters)
minimize
θ
J(θ) ⇐⇒ minimize
θ
1
n
n∑
i=1
q(θ; yi, xi)
If J(θ) is convex in θ
▶ 전역 최적해 (global optimum) 존재
▶ 그라디언트 하강 (gradient descent) 방법으로 반복계산하면 유일해에 무조건
수렴
▶ Newton’s method, (ordinary) gradient descent, stochastic gradient descent
If J(θ) is non-convex in θ
▶ 전역 최적해 (global optimum)에 수렴 못하나 “꽤 괜찮은” 국소 최적해 (local
optimum)를 찾아야 함
▶ (Stochastic) gradient descent는 q(θ)의 많은 영역을 search하기에 적합하지
않으며 안장점에도 취약. SGD의 변형 방법론들 제안됨
21 / 27
23.
Optimization of convexJ(θ)
▶ Let θ ∈ Rp
.
Netwon’s method :
θnew
← θold
− [▽2
θJ(θold
)]−1
▽θ J(θold
)
▶ [▽2
θJ(θold
)]−1
에서 큰 메모리 필요, 역행렬 계산 오래걸림. 잘 안씀
(Ordinary) gradient descent :
θnew
← θold
− c · ▽θJ(θold
)
▶ c는 반복이 계속될수록 줄어들게 세팅. 유저가 지정
Stochastic gradient descent :
▶ Write J(θ) = 1
n
∑n
i=1 q(θ; yi, xi).
▶ 매 업데이트마다 (n개 관측치 중) m개만 고른다 (minibatch sampling).
WLOG, let {(x1, y1), . . . , (xm, ym)} be such a sample.
θnew
← θold
− c ·
1
m
m∑
i=1
▽θq(θold
; yi, xi)
22 / 27
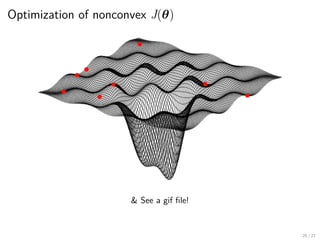
Optimization of non-convexJ(θ)
(Stochastic) gradient descent :
θnew
← θold
− c ·
1
m
m∑
i=1
▽θq(θold
; yi, xi)
▶ Note : 그라디언트는 본질적으로 국소적(local) 성질. Nonconvex function의
전체적 모양과 상관없음
Stochastic gradient descent with momentum :
▶ 국소점에 빠지지 않고 함수 surface의 넓은 범위를 탐색하는 방법?
▶ Gradient descent를 울퉁불퉁한 내리막길에서의 공굴리기로 생각.
그라디언트를 속도가 아닌 가속도로 해석
vnew
← a · vold
− c ·
1
m
m∑
i=1
▽θq(θold
; yi, xi)
θnew
← θold
+ v
▶ a는 보통 0.9. c를 미리 지정하지 않고 데이터에 의존하는 방식도 있음
(AdaGrad, RMSProp, Adam 등)
24 / 27
So what?
회귀(Regression), 분류(classification)는손실함수를 적당히 정하면 다변수함수를
최소화하는 문제로 바뀌는데 풀기 쉽지 않다. — 끝?
회귀/분류에서 파생되는 무궁무진한 스토리 (아는 것만 씀)
▶ 인간/동식물에 실험하면 (심리학, 교육학, 농학, 의학) : 척도의 측정오차 문제, 실험
재현 가능성 문제, 실험 설계 최적화 문제
▶ 역사적으로 관찰된 자료를 쓰면 (경제학, 경영학) : 시계열 자료의 예측, 관찰자료 문제
▶ 센서로 자동입력되는 자료를 쓰면 (컴퓨터과학, 산업공학) : 가장 효율적인 저장 방법,
실현가능한 시간 안에 계산, 예측력 최대화, 유저 인터페이스 디자인
관련된 기저 이론
▶ 수학(계산과학) 및 컴퓨터과학 : 함수 최소화 알고리즘의 수렴성, 소요시간(복잡성),
컴퓨팅 과정에서의 오차
▶ 통계학 : 새로운 자료 형태에 맞춘 새 모형, 모형간 관계 규명, 모형의 유의성, 최적성,
선택, 한계, 수반되는 오차 — 몇년 전에는 이론이 더 활발하였으나 최근에는 응용/
방법론/계산이 대세
▶ 어느 학과나 계산 라이브러리 (on C/Fortran/Python/R...)의 개발도 중요하고 활발
26 / 27
28.
From SNUME
관련 대학원전공
▶ 계산과학, 통계학, 산업공학, 컴퓨터과학, 컴퓨터공학
▶ 학과마다 이론 위주 / 실제 프로젝트 위주 교수님이 다름. 둘다 경험할 수 있는 환경이
이상적
학부때 공부하면 좋은 것?
▶ 선형대수, 해석개론, 위상수학, (실)해석학
▶ 타과 학부 과목들
▶ 컴퓨터공학과 : 컴퓨터 프로그래밍 기초 (C), 자료구조, ...
▶ 통계학과 : 전산통계 (R/Python), (확률의 개념 및 응용,) 수리통계,
데이터마이닝, ...
▶ 수리과학부 : 수치해석개론, 실변수함수론 or 대학원 실해석학, ...
▶ 전공 외 분야에 대한 폭넓은 관심
데이터 사이언티스트가 뭐고 전망은 밝은가요?
▶ 컴퓨터 프로그래머(90’s-00’s) → 퀀트(00’s) → 데이터 사이언티스트(10’s)...?
▶ 수리적 감각 + 컴퓨팅 + 의사소통의 조화가 요구되는 비슷한 직종은 수요 꾸준
▶ 평생직장보다는 평생직업. 공부 네버엔딩. 교육 외의 방법으로 사회에 기여하고 싶다면
수학+교육 전공자로서 도전해볼만한 진로
27 / 27




![Setting repeated
모형
▶ Response variable : y ∈ R
▶ Quantitative or categorical
▶ Predictor variable : x = (x1, x2, . . . , xp)T
∈ Rp
▶ 모형 : y = f(x), y = f(x) + ϵ, or P(y | x) = f(x)
f is unknown – data-driven estimation
▶ Observed data : (x1, y1), (x2, y2), . . . , (xn, yn) (n data points)
▶ Assume f ∈ F (linear function, smooth function, ..)
▶ Define loss function : L(y, f(x)) — 여기서의 f는 위의 f와 같기도/다르기도
▶ Problem to be solved : ideally minimize E
[
L (y, f(x))
]
. In practice,
minimize
f∈F
1
n
n∑
i=1
L (yi, f(xi))
6 / 27](https://image.slidesharecdn.com/20161004snume-170911211919/85/slide-7-320.jpg)

![1. Multiple linear regression
Remark. 최소화하려는 함수는 β 의 함수
minimize
β∈Rp
1
n
n∑
i=1
(yi − xT
i β)2
최소화 방법
▶ In matrix form :
minimize
β∈Rp
1
n
[
βT
XT
Xβ − 2yT
Xβ + yT
y
]
▶ β 의 이차 형식(binary form)으로 쓸 수 있음
▶ (이차식이므로 당연히?) β 에 대한 볼록함수 (convex function)
▶ n > p이면 해가 유일하게 존재 : ˆβ = (XT
X)−1
XT
y
Not covered here
▶ 다른 손실함수
▶ 데이터에 선형모형이 적합한지 알아보는 방법 (모형 평가, model assessment)
▶ 유의미한 (βj ̸= 0인) 변수 찾아내기 (변수/모형 선택, model selection)
▶ n < p일 때의 추론 (고차원 회귀분석, high-dimensional regression)
▶ 상관관계 → 인과관계 (인과 추론, causal inference)
9 / 27](https://image.slidesharecdn.com/20161004snume-170911211919/85/slide-10-320.jpg)








![Optimization of convex J(θ)
▶ Let θ ∈ Rp
.
Netwon’s method :
θnew
← θold
− [▽2
θJ(θold
)]−1
▽θ J(θold
)
▶ [▽2
θJ(θold
)]−1
에서 큰 메모리 필요, 역행렬 계산 오래걸림. 잘 안씀
(Ordinary) gradient descent :
θnew
← θold
− c · ▽θJ(θold
)
▶ c는 반복이 계속될수록 줄어들게 세팅. 유저가 지정
Stochastic gradient descent :
▶ Write J(θ) = 1
n
∑n
i=1 q(θ; yi, xi).
▶ 매 업데이트마다 (n개 관측치 중) m개만 고른다 (minibatch sampling).
WLOG, let {(x1, y1), . . . , (xm, ym)} be such a sample.
θnew
← θold
− c ·
1
m
m∑
i=1
▽θq(θold
; yi, xi)
22 / 27](https://image.slidesharecdn.com/20161004snume-170911211919/85/slide-23-320.jpg)













































![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)




![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)

