Download to read offline


















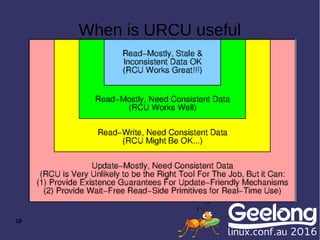



This document discusses the thread synchronization methods used in glusterd, focusing on the transition from single-threaded to multi-threaded design and the challenges associated with the 'big lock' approach. It introduces Read-Copy-Update (RCU) as a more efficient synchronization mechanism that allows concurrent reads and updates, avoiding the pitfalls of deadlocks and writer starvation. The document also explores various RCU flavors and APIs, highlighting their practical applications and benefits.
























































































