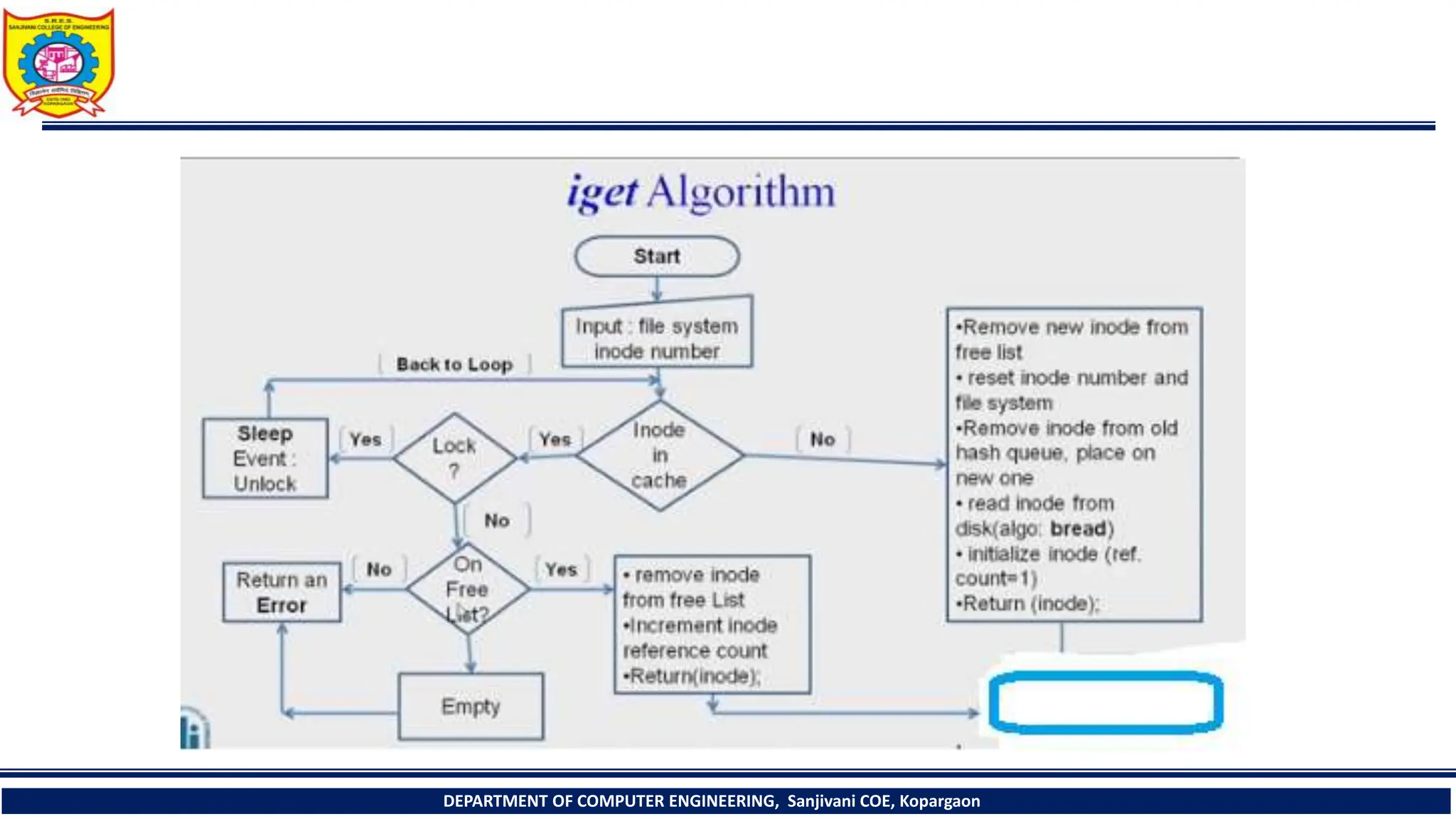
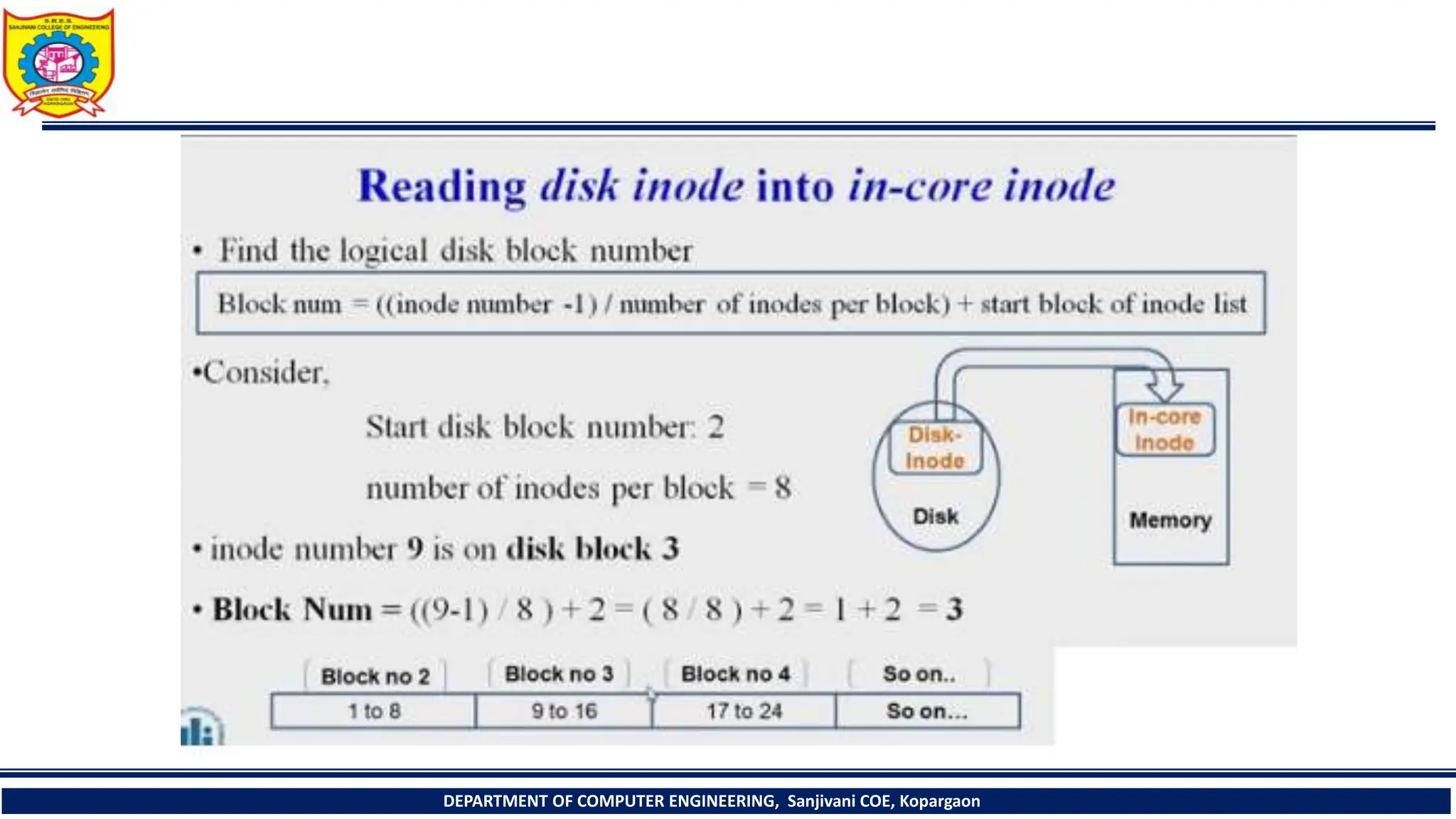
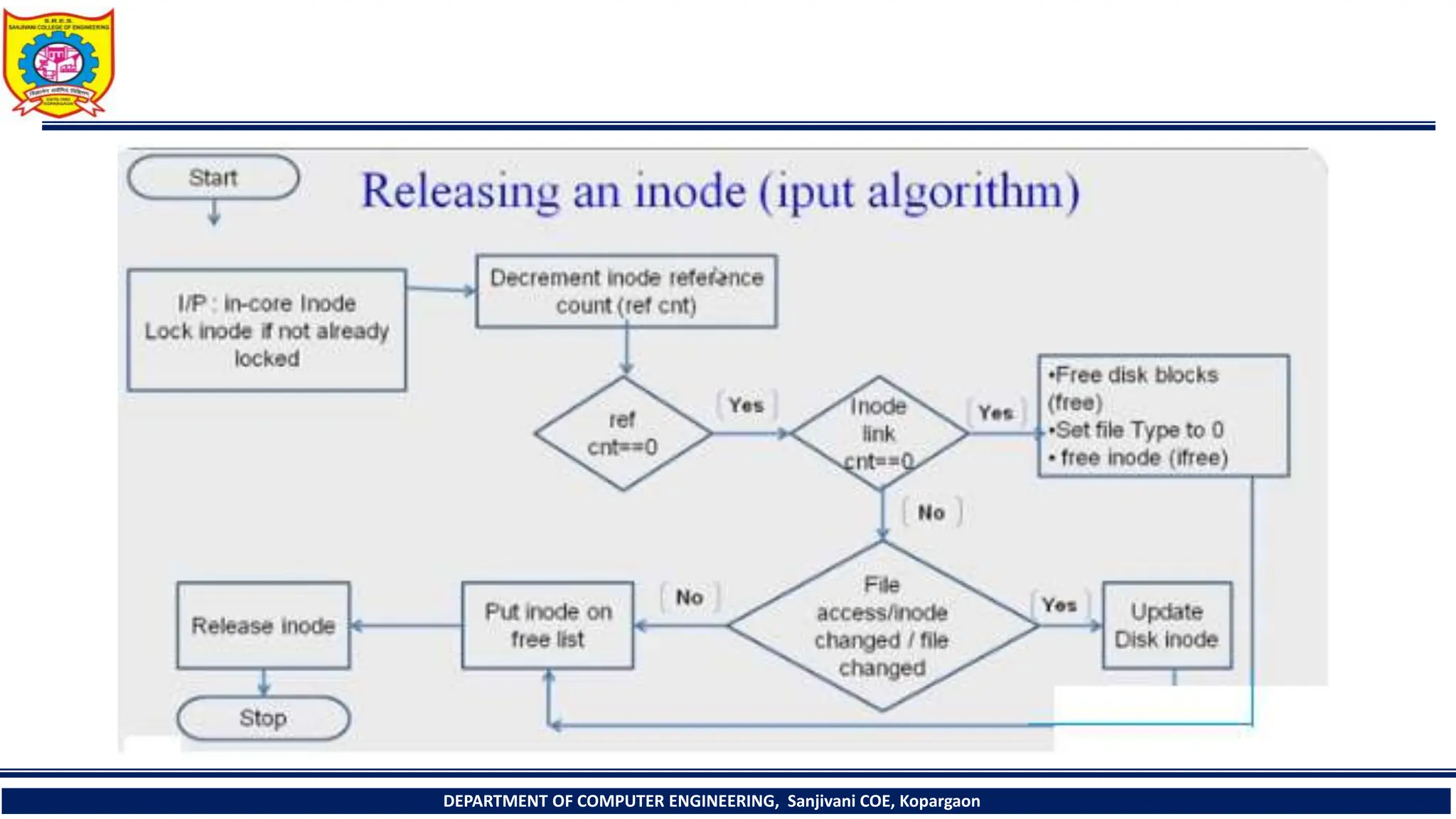
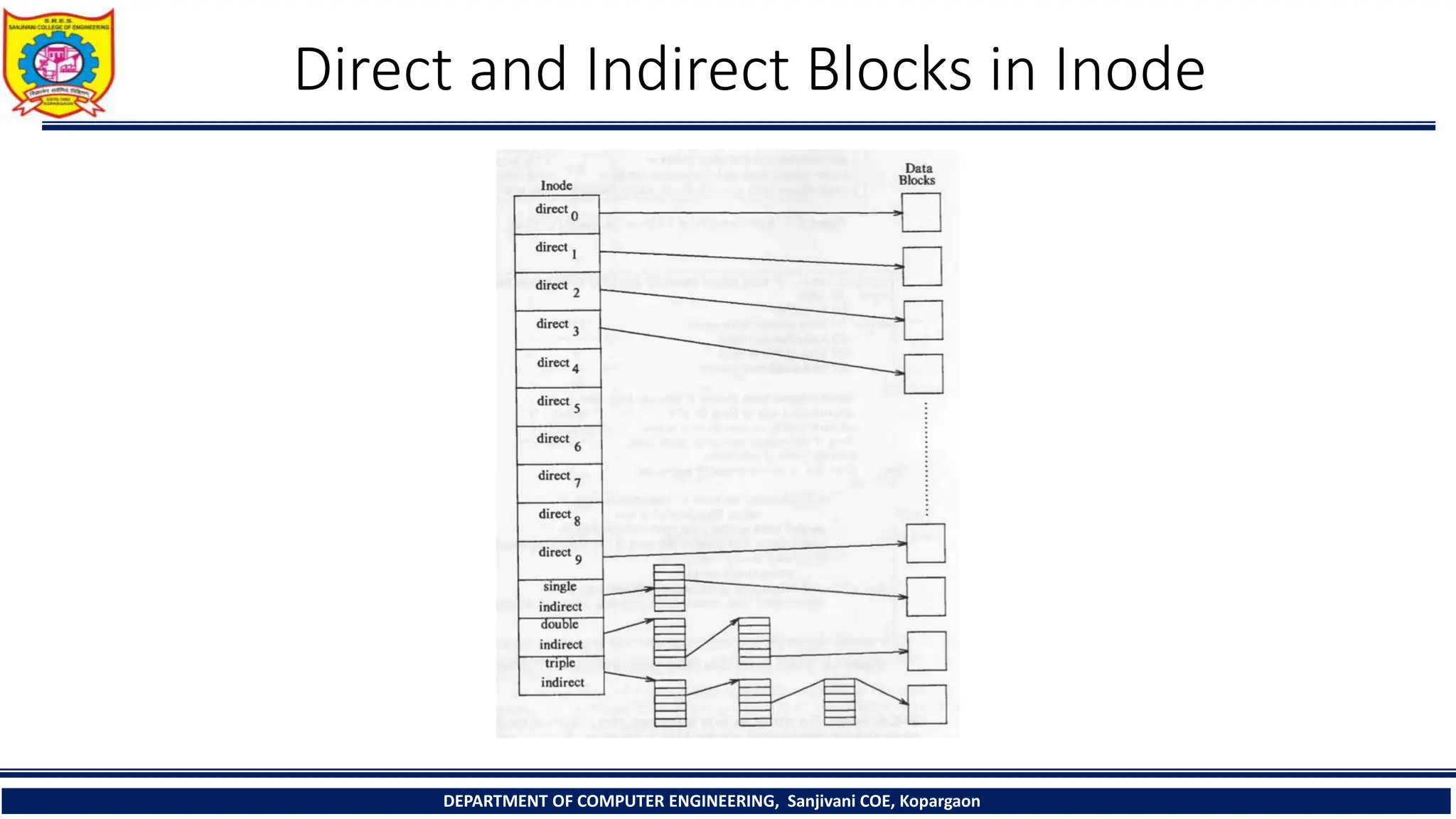
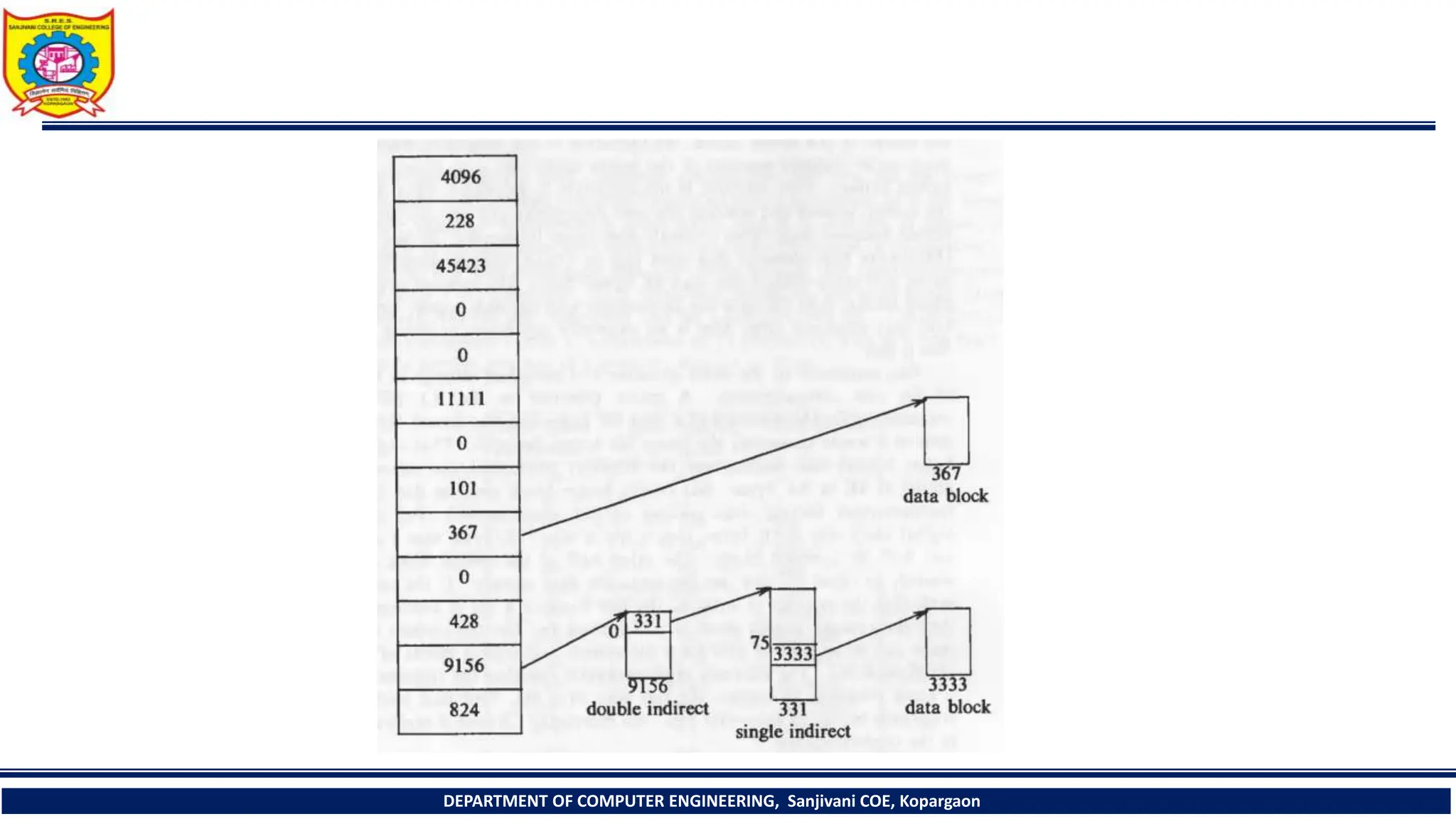
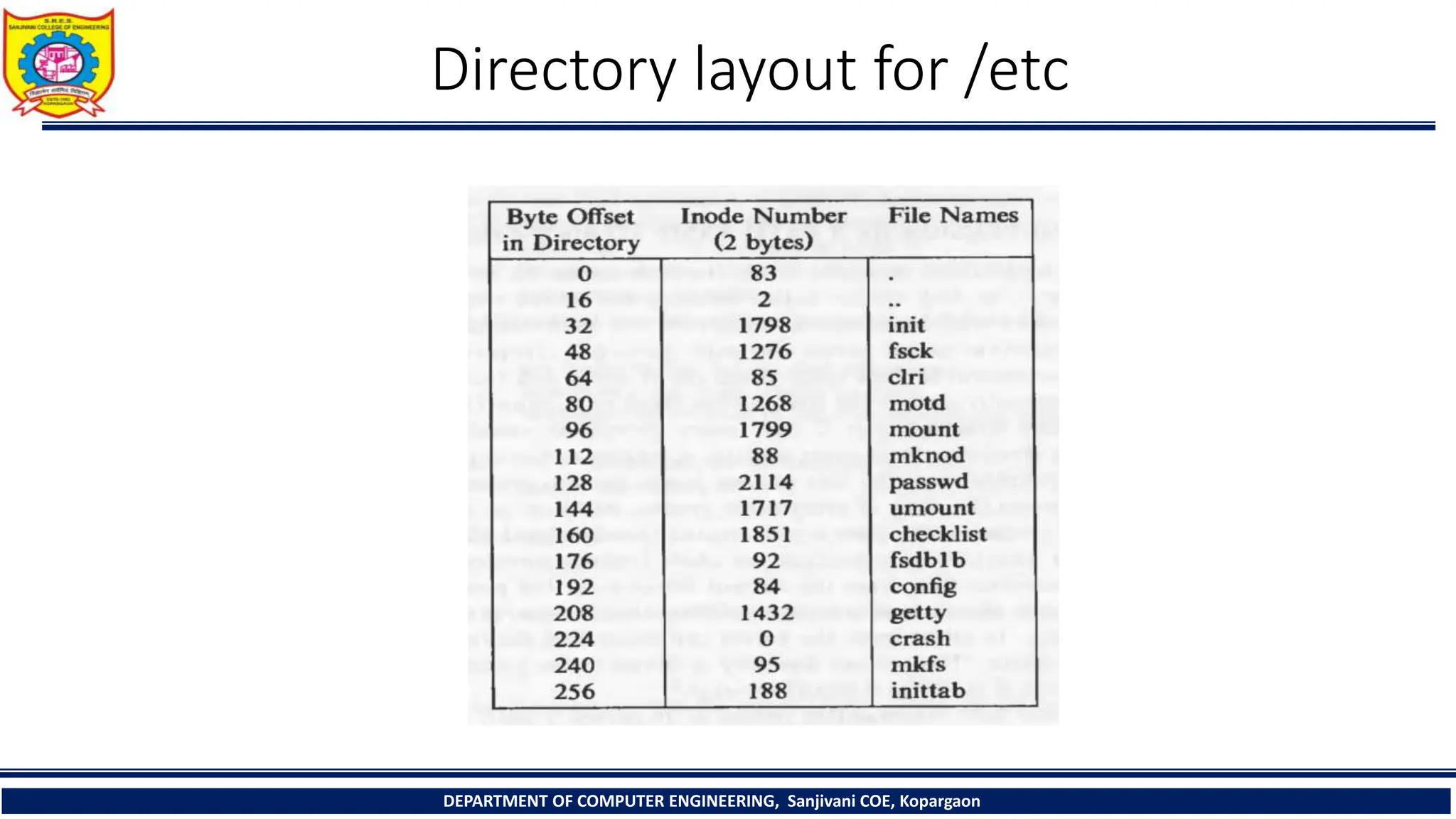
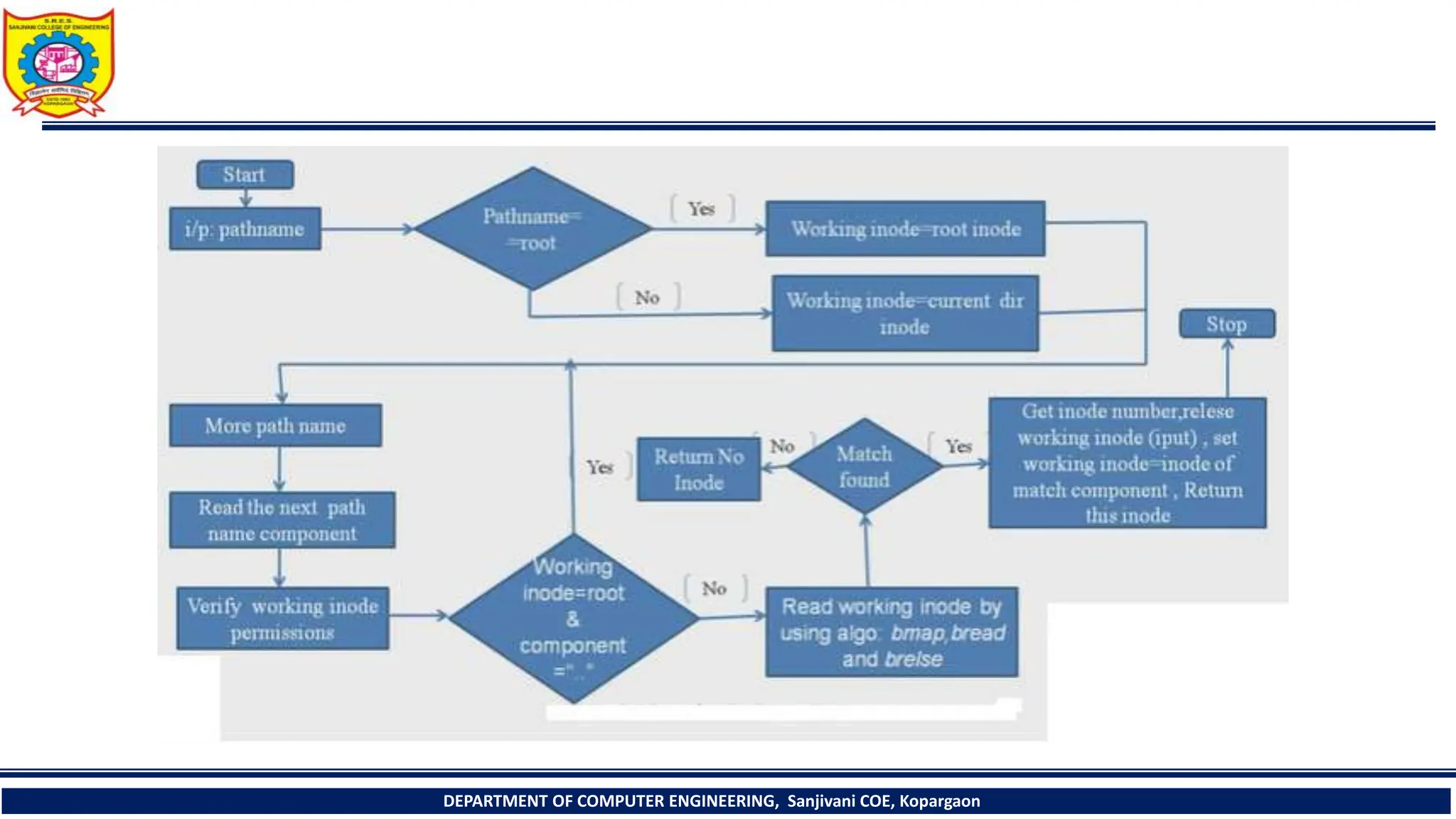
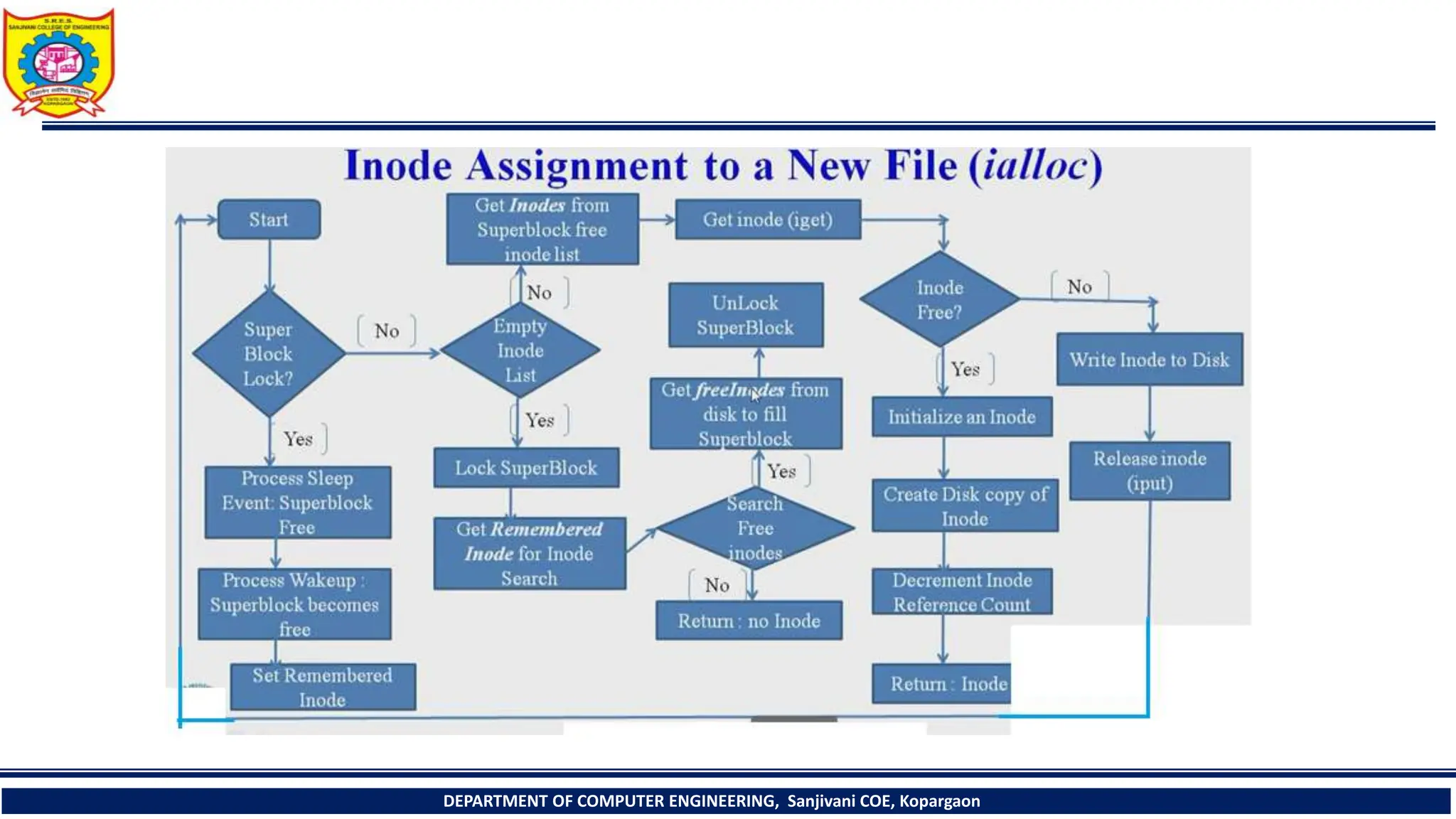
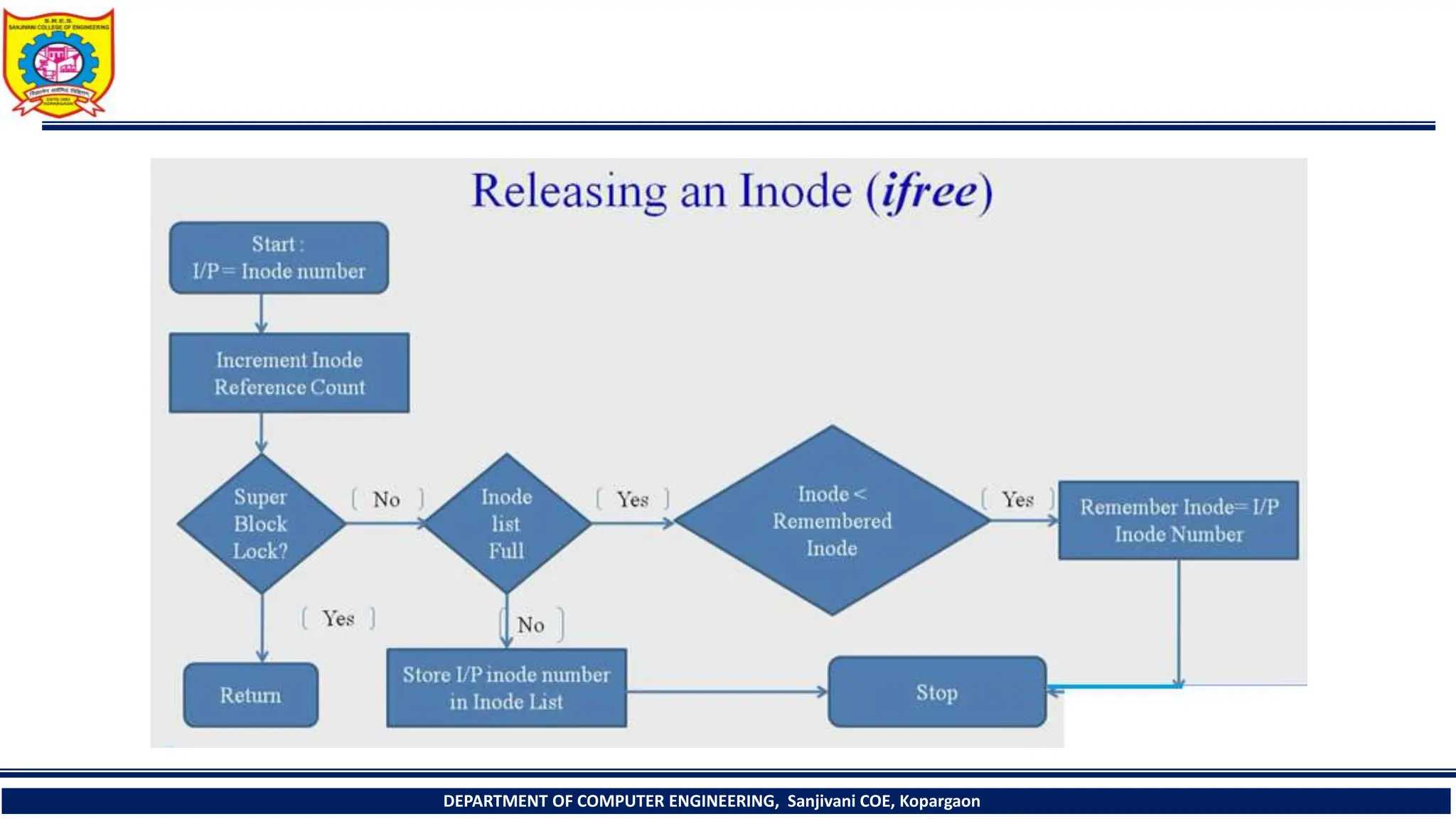
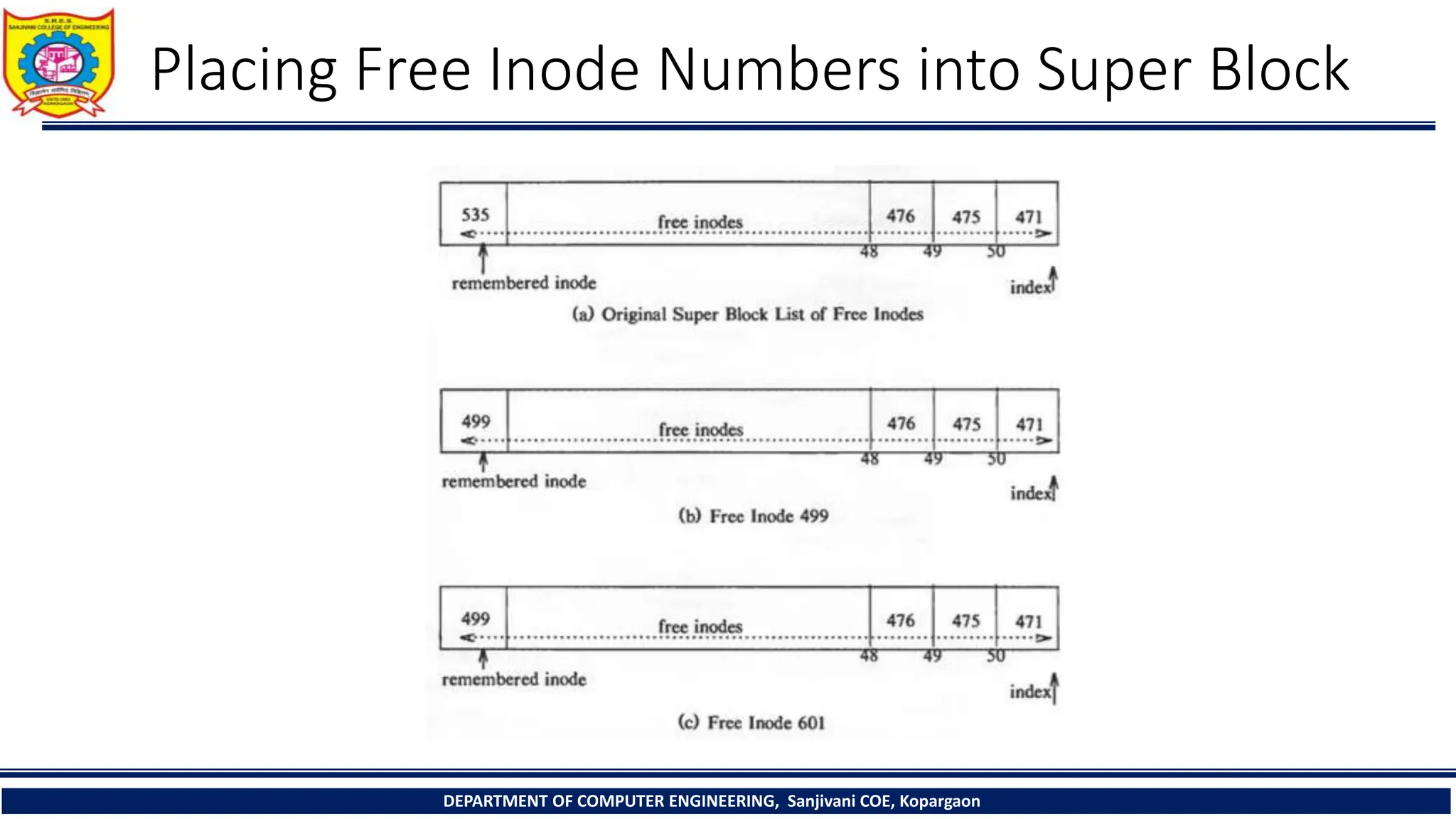
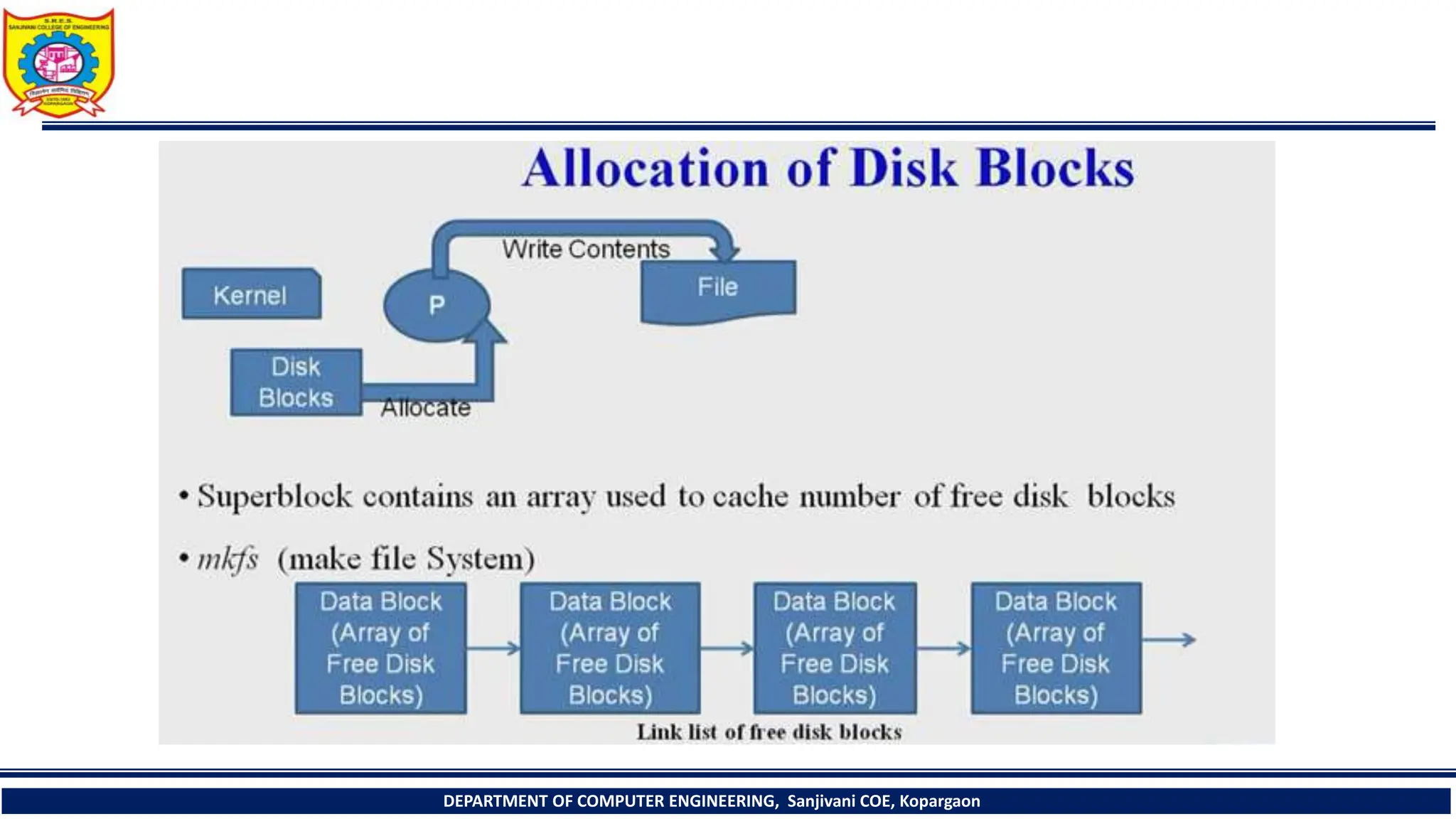
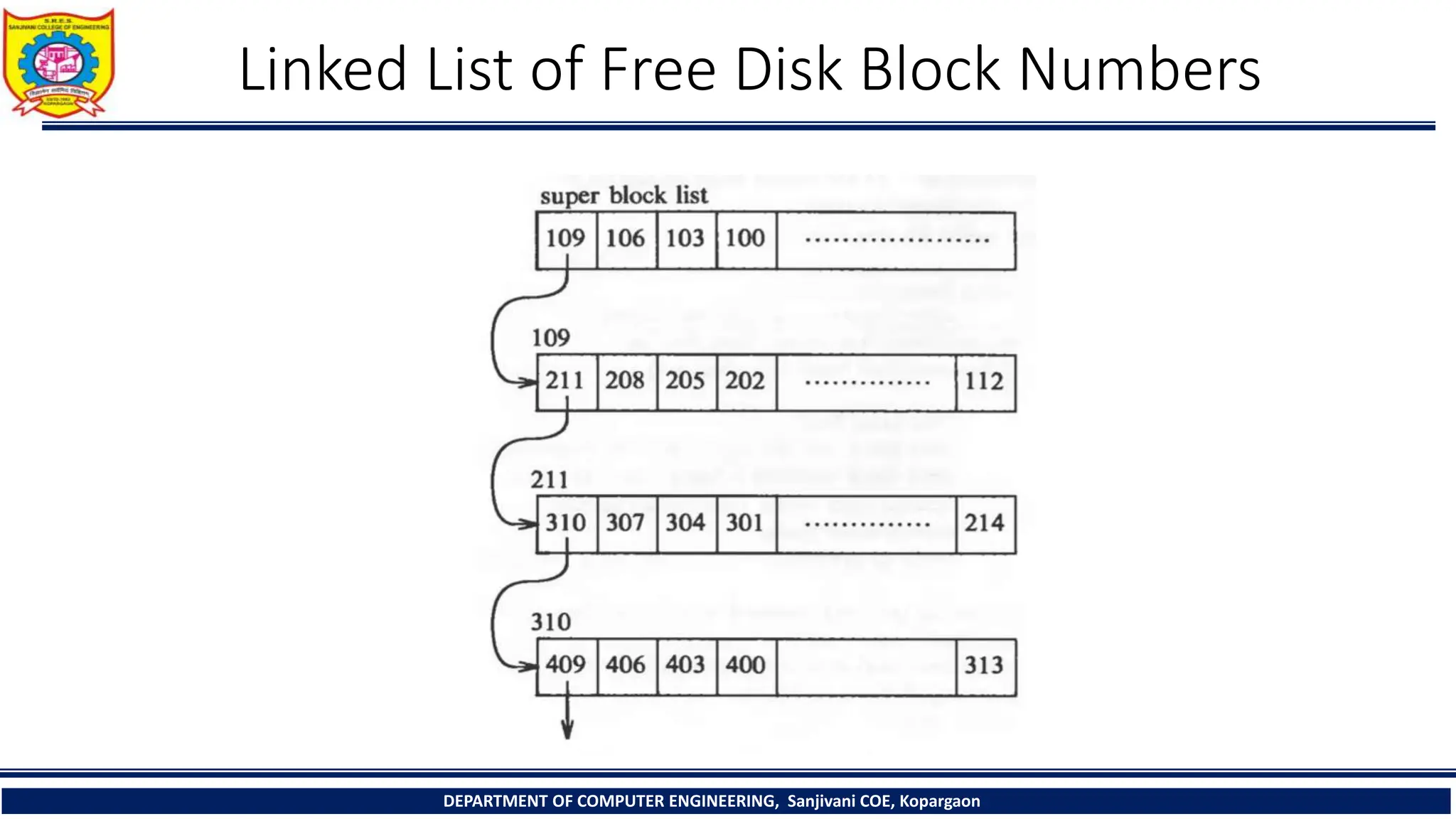
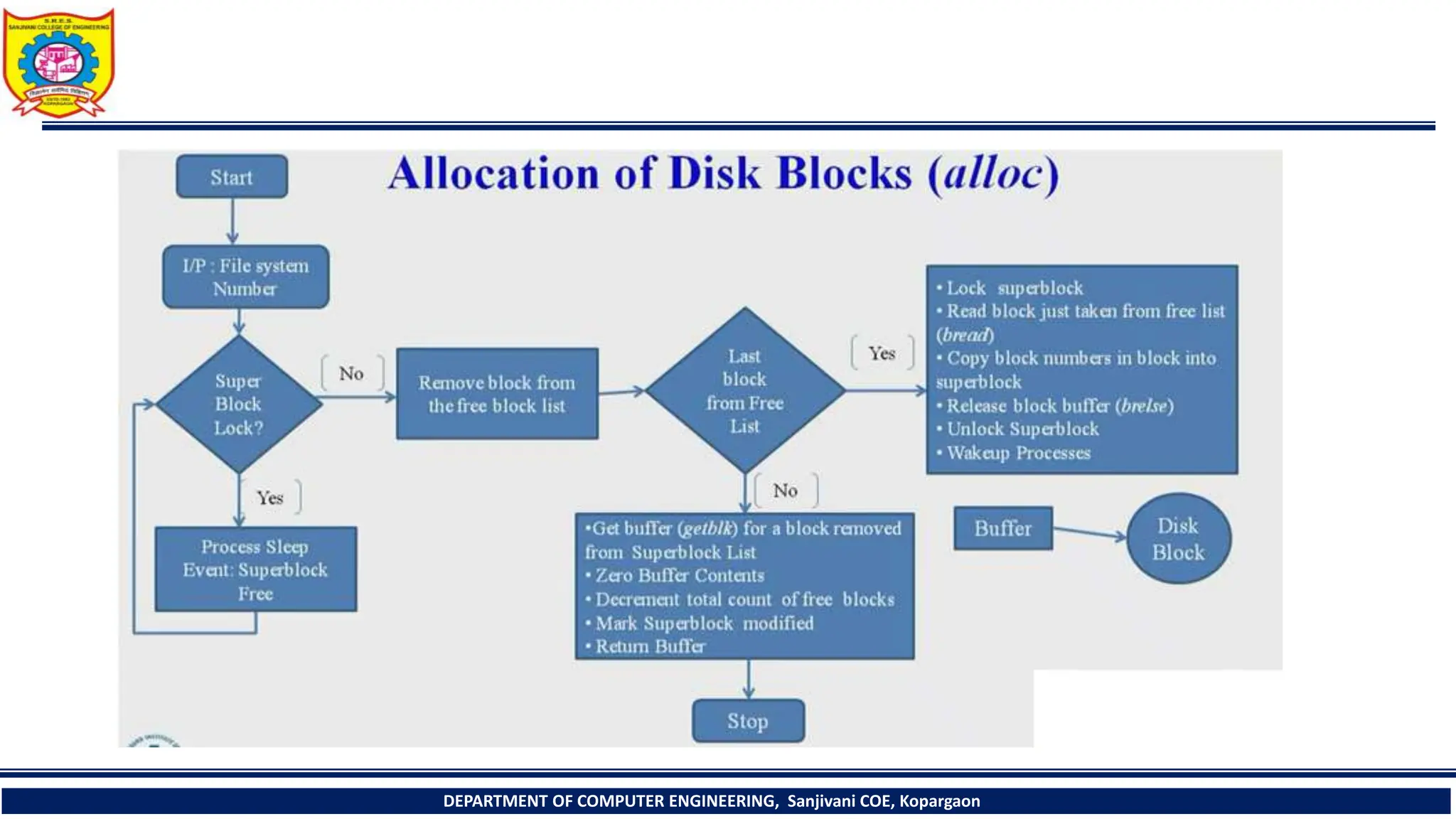
The document provides a comprehensive overview of file systems, focusing on internal file representation, inodes, and related algorithms in Unix systems. It covers topics such as inode structure, file types, access permissions, and directory organization, along with specific algorithms for inode allocation and disk block management. The document also includes a case study on open-source automation using Red Hat Ansible.