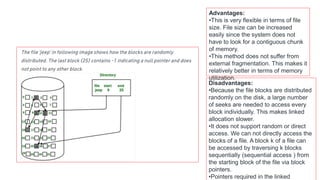
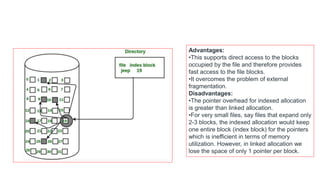
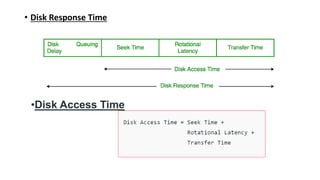
The document discusses various file allocation methods and disk scheduling algorithms. There are three main file allocation methods - contiguous allocation, linked allocation, and indexed allocation. Contiguous allocation suffers from fragmentation but allows fast sequential access. Linked allocation does not have external fragmentation but is slower. Indexed allocation supports direct access but has higher overhead. For disk scheduling, algorithms like FCFS, SSTF, SCAN, CSCAN, and LOOK aim to minimize seek time, rotational latency, and response time by scheduling requests in different orders.










































![Disk Management Presentation of Group V [Operating System (Lab)].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/diskmanagementpresentationofgroupvoperatingsystemlab-230125231922-907c5b35-thumbnail.jpg?width=640&height=640&fit=bounds)





















