Chapter 8: MemoryManagement
Background
Swapping
Contiguous Memory Allocation
Segmentation
Paging
Structure of the Page Table
Example: The Intel 32 and 64-bit Architectures
Example: ARM Architecture
3.
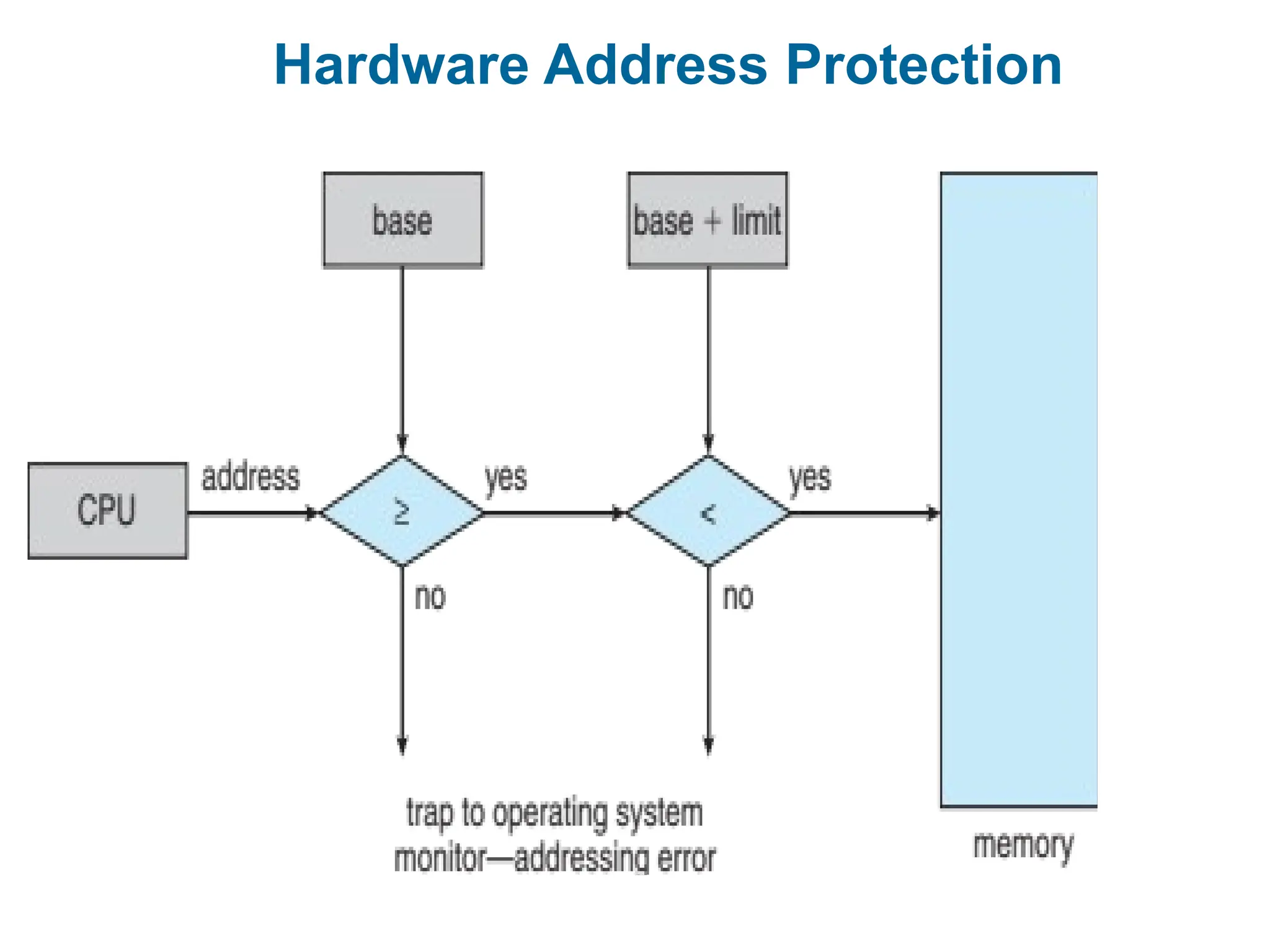
Base and LimitRegisters
A pair of base and limit registers define the logical address space
CPU must check every memory access generated in user mode to
be sure it is between base and limit for that user
Binding of Instructionsand Data to Memory
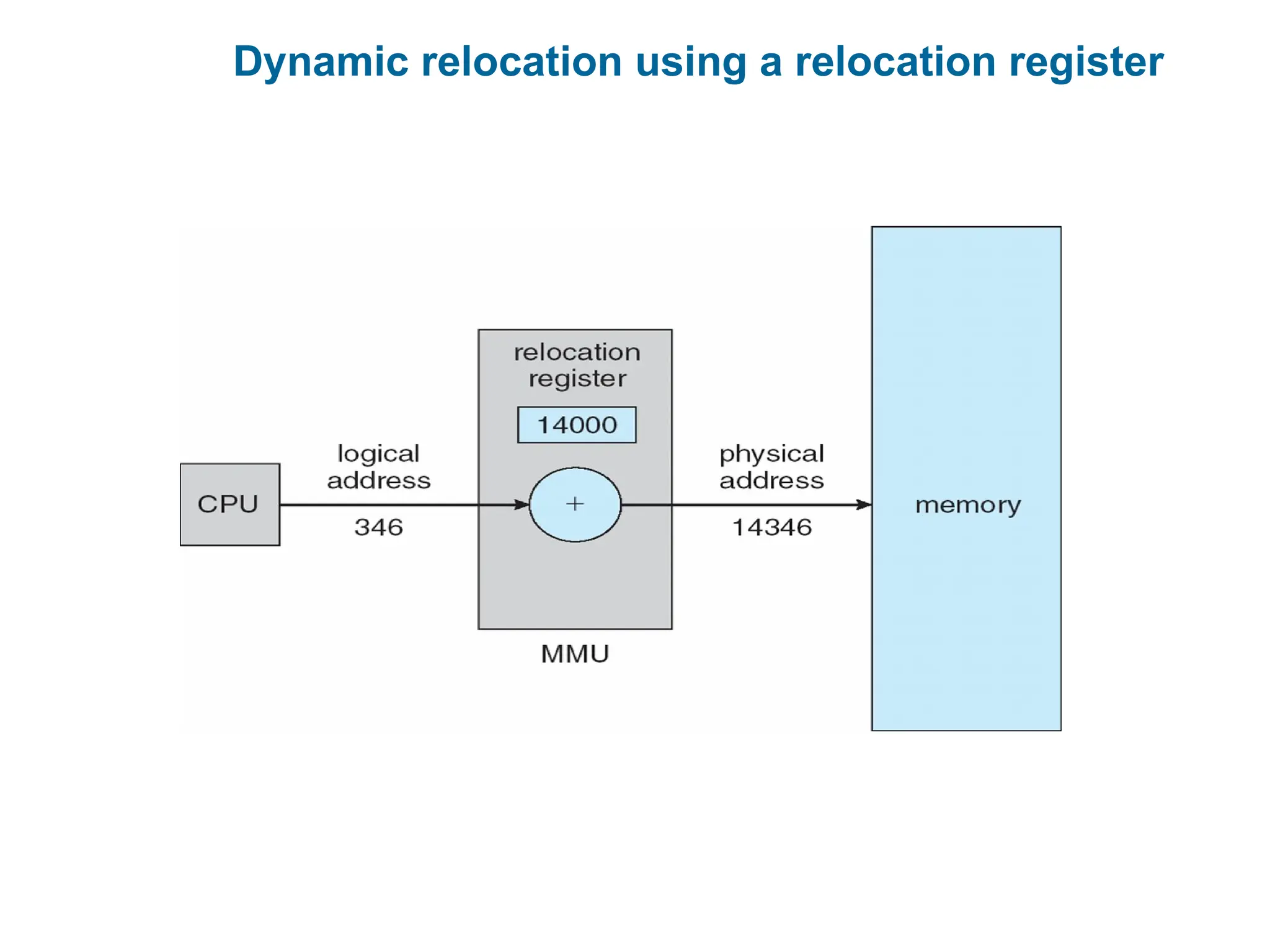
Address binding of instructions and data to memory addresses can
happen at three different stages
Compile time: If memory location known a priori, absolute code
can be generated; must recompile code if starting location changes
Load time: Must generate relocatable code if memory location is
not known at compile time
Execution time: Binding delayed until run time if the process can
be moved during its execution from one memory segment to another
6.
Logical vs. PhysicalAddress Space
Logical address – generated by the CPU; also referred to as virtual
address
Physical address – address seen by the memory unit
Logical address space is the set of all logical addresses generated by a
program
Physical address space is the set of all physical addresses generated
by a program
Dynamic Linking
Staticlinking – system libraries and program code combined by
the loader into the binary program image
Dynamic linking –linking postponed until execution time
Small piece of code, stub, used to locate the appropriate
memory-resident library routine
Operating system checks if routine is in processes’ memory
address
If not in address space, add to address space
9.
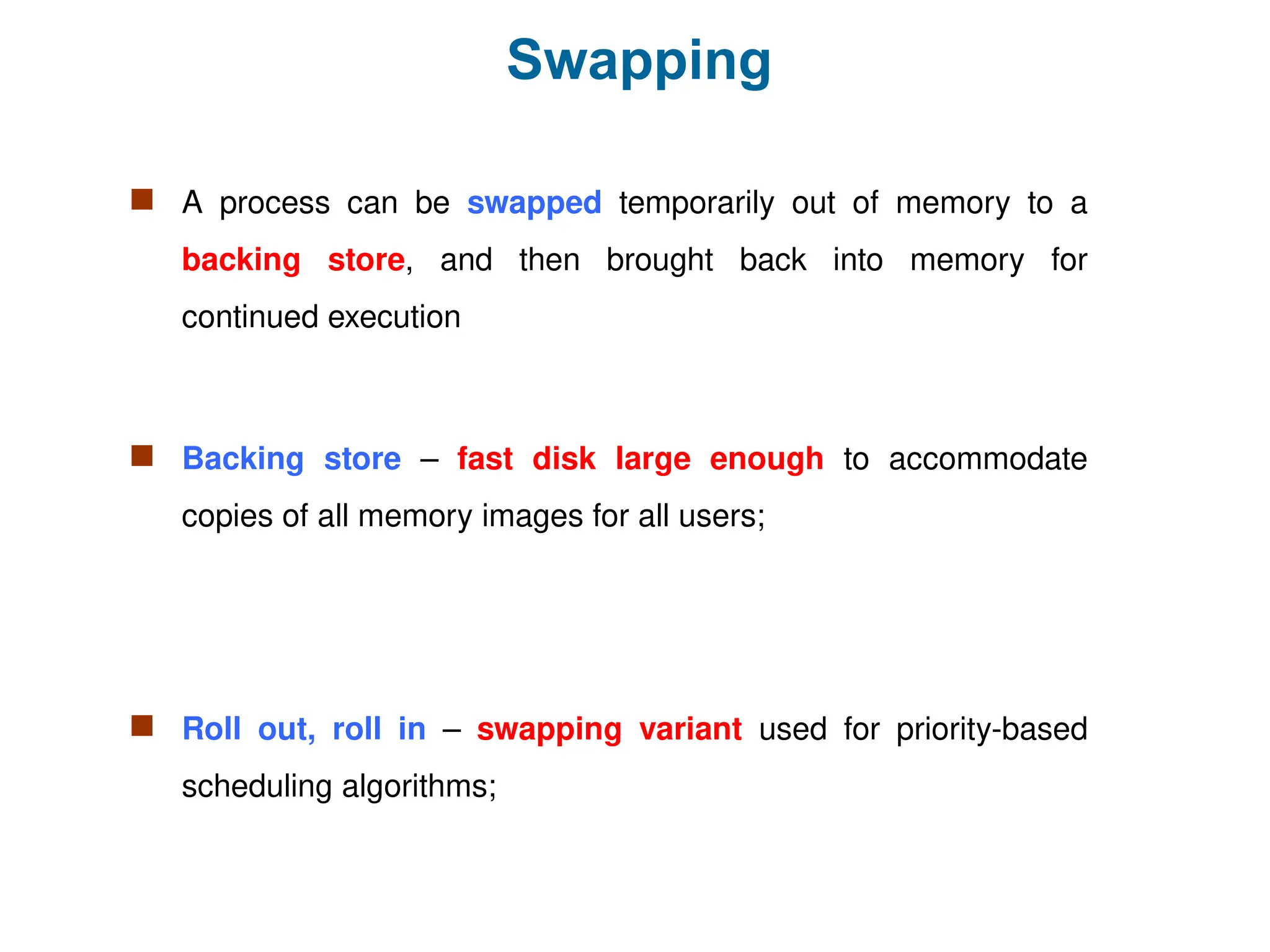
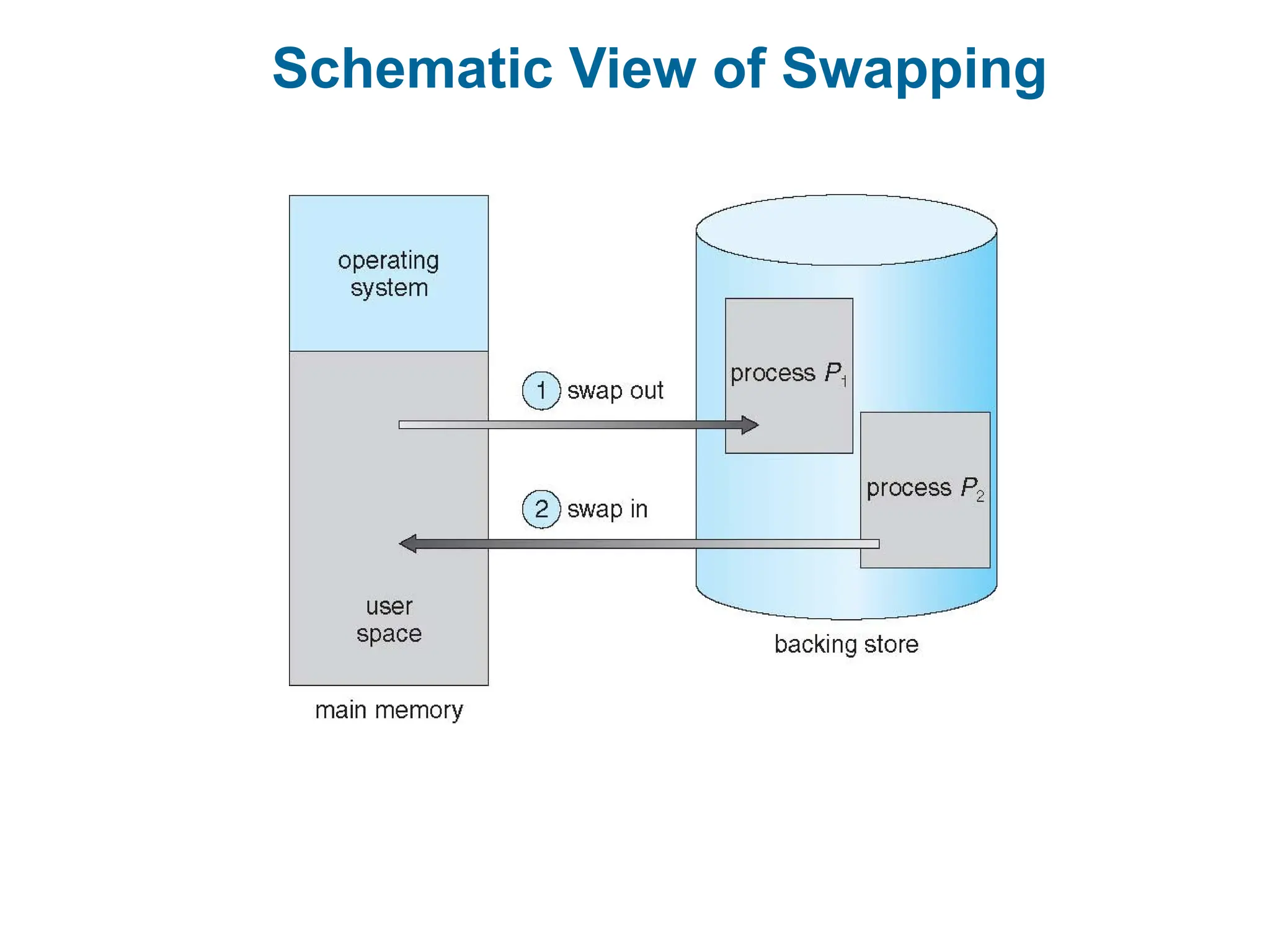
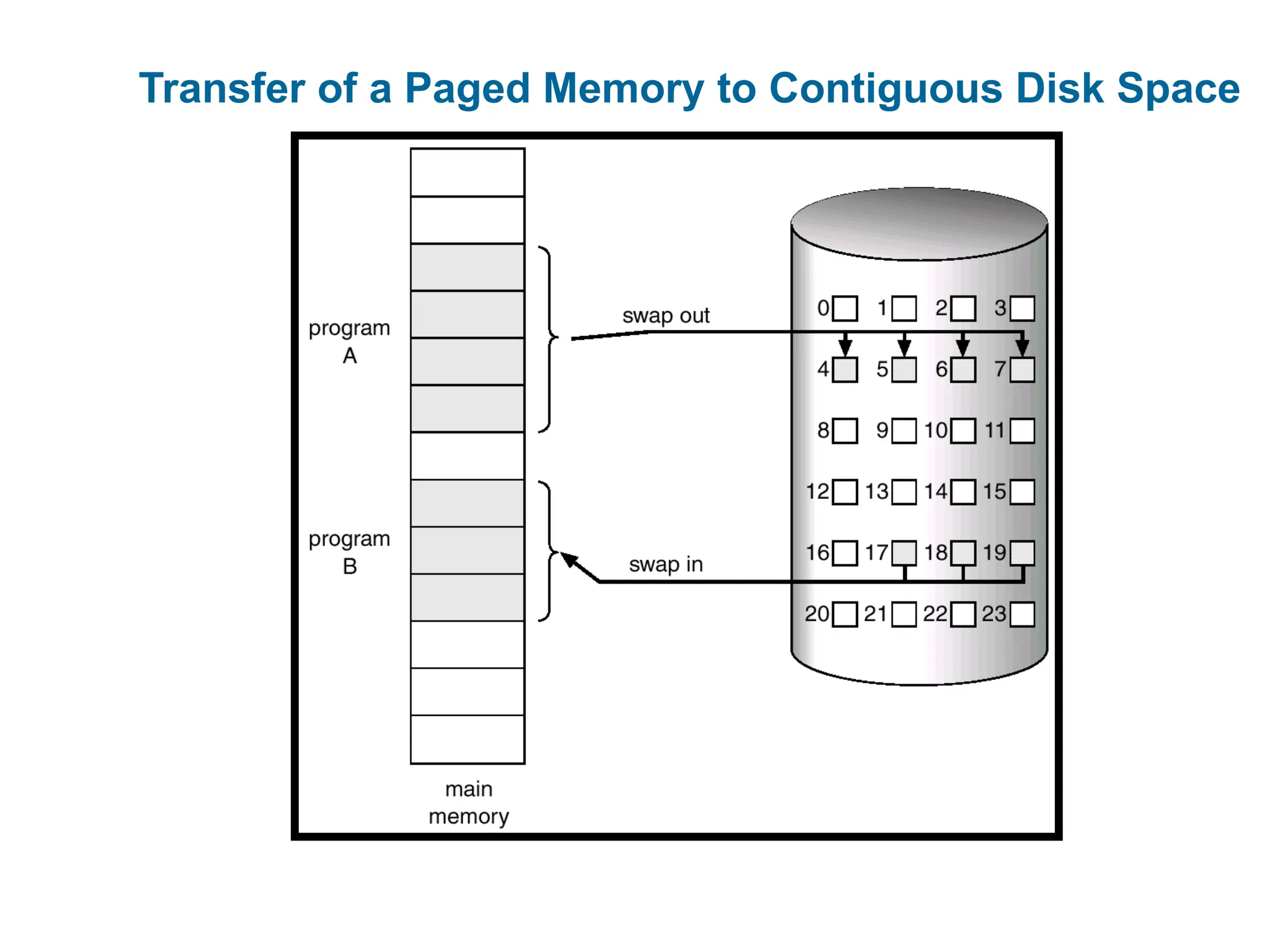
Swapping
A processcan be swapped temporarily out of memory to a
backing store, and then brought back into memory for
continued execution
Backing store – fast disk large enough to accommodate
copies of all memory images for all users;
Roll out, roll in – swapping variant used for priority-based
scheduling algorithms;
Contiguous Allocation
Mainmemory must support both OS and user processes
Contiguous allocation is one early method
Main memory usually into two partitions:
Resident operating system, usually held in low memory
User processes then held in high memory
Each process contained in single contiguous section of
memory
12.
Dynamic Storage-Allocation Problem
First-fit: Allocate the first hole that is big enough
Best-fit: Allocate the smallest hole that is big enough; must
search entire list, unless ordered by size
Produces the smallest leftover hole
Worst-fit: Allocate the largest hole; must also search entire list
Produces the largest leftover hole
How to satisfy a request of size n from a list of free holes?
First-fit and best-fit better than worst-fit in terms of speed and storage
utilization
14.
Fragmentation
External Fragmentation– total memory space exists to satisfy a request,
but it is not contiguous
Internal Fragmentation – allocated memory may be slightly larger than
requested memory; this size difference is memory internal to a partition, but
not being used
15.
Non-Contiguous Allocation
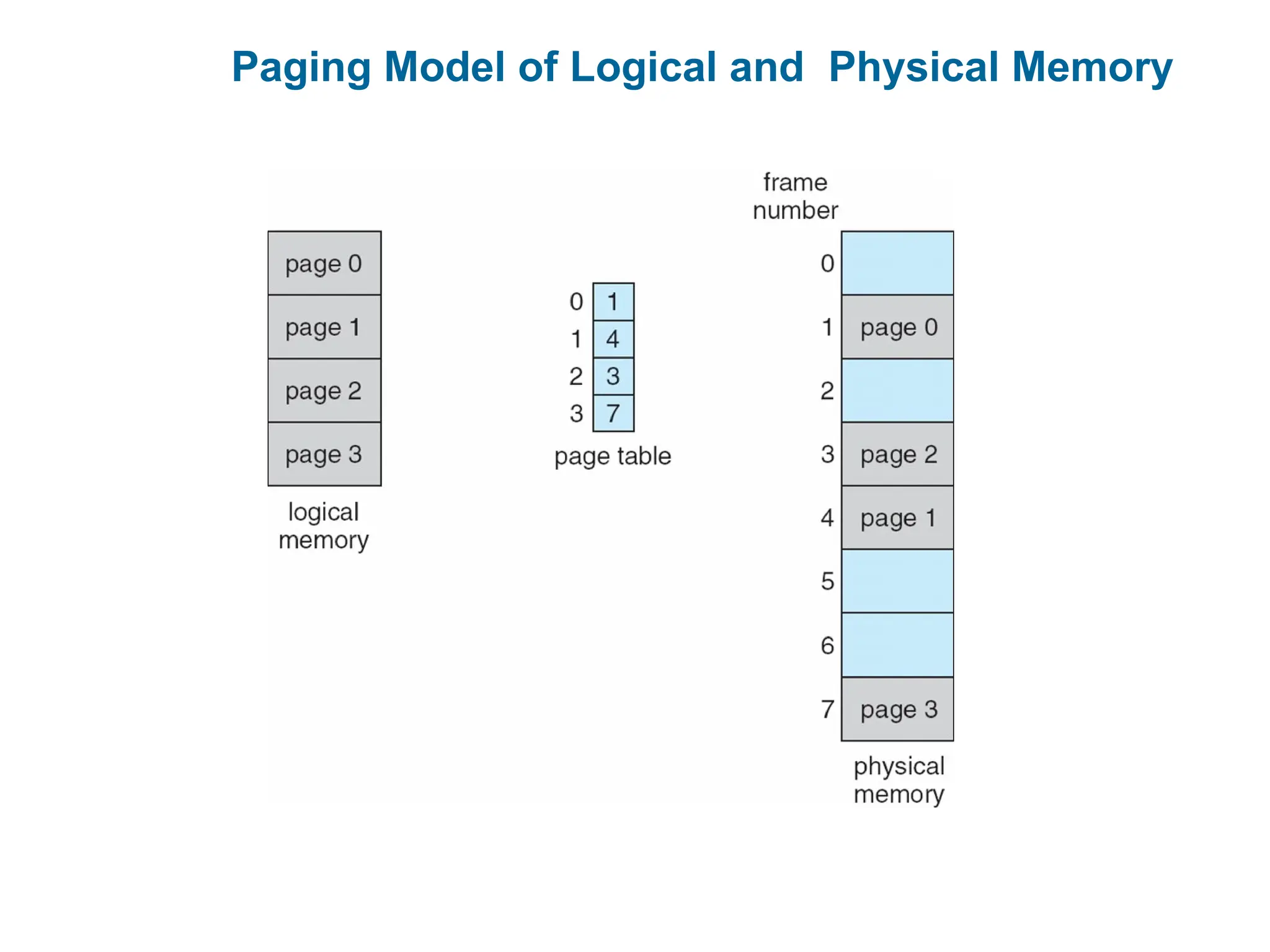
Paging
Physicaladdress space of a process can be noncontiguous; process is allocated
physical memory whenever the latter is available
Avoids external fragmentation
Divide physical memory into fixed-sized blocks called frames
Size is power of 2, between 512 bytes and 16 Mbytes
Divide logical memory into blocks of same size called pages
To run a program of size N pages, need to find N free frames and load program
Set up a page table to translate logical to physical addresses
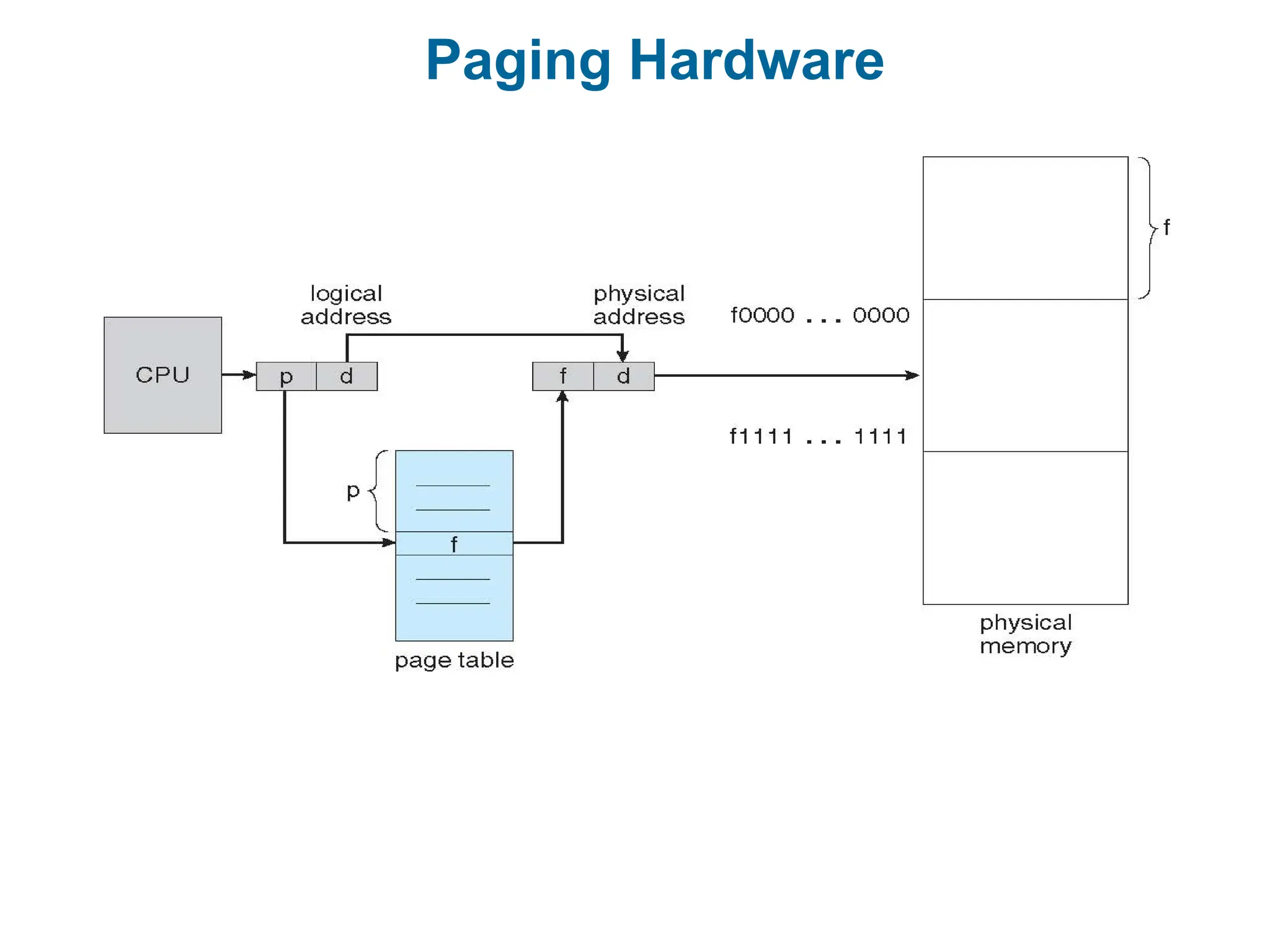
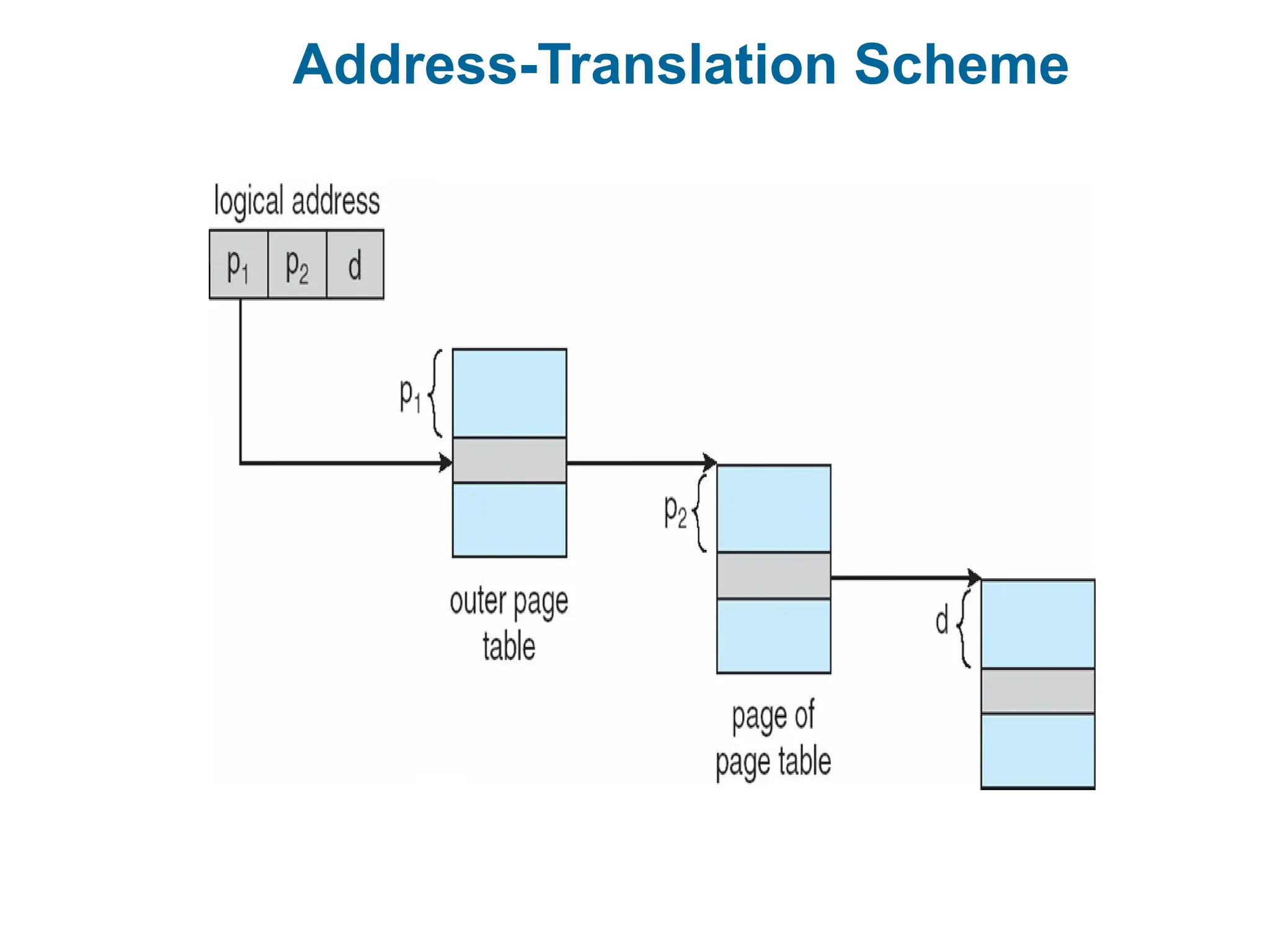
Address Translation Scheme
Address generated by CPU is divided into:
Page number (p) – used as an index into a page table which contains
base address of each page in physical memory
Page offset (d) – combined with base address to define the physical
memory address that is sent to the memory unit
For given logical address space 2m
and page size 2n
page number page offset
p d
m -n n
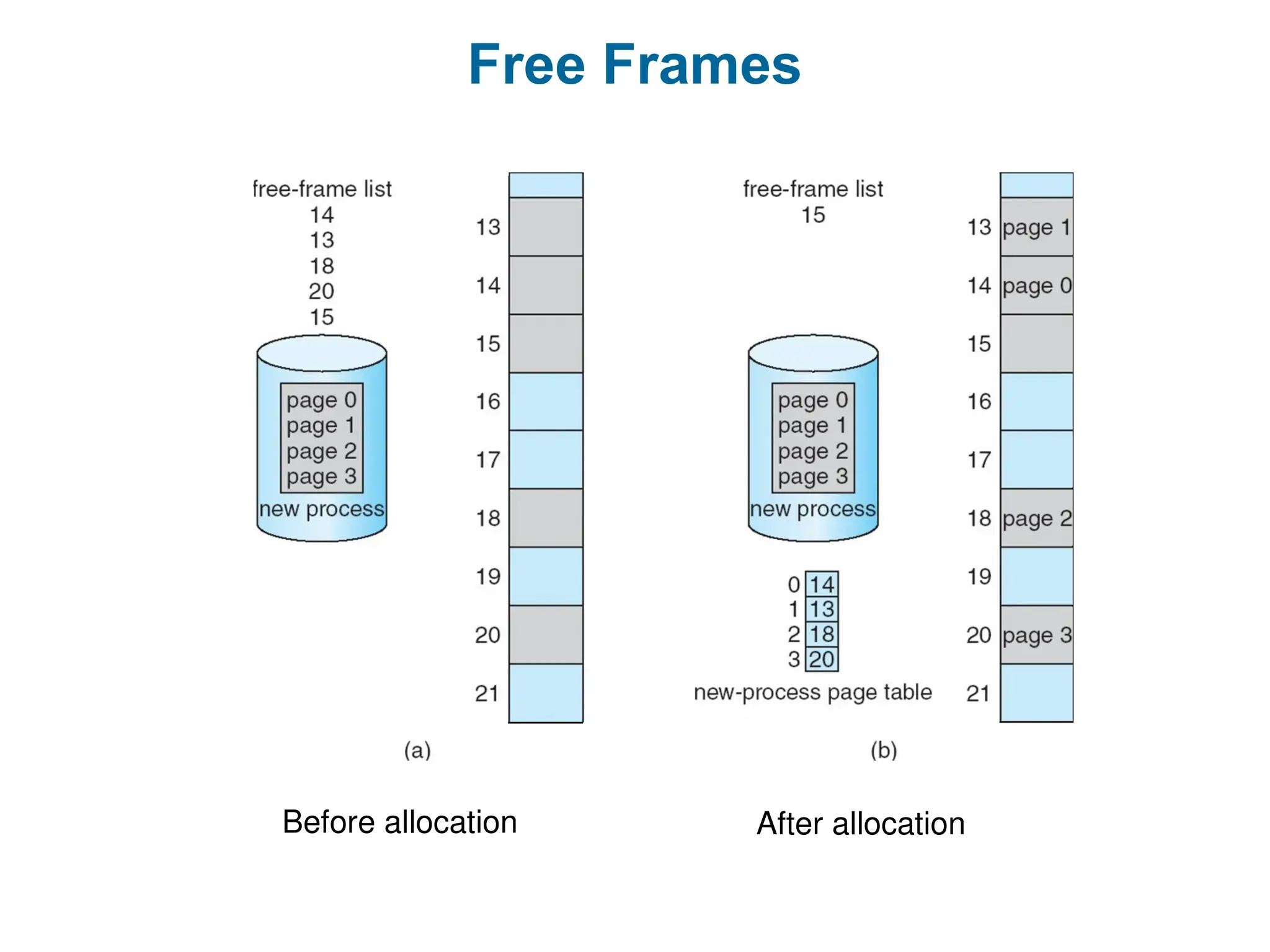
Implementation of PageTable
Register method
Page table is kept in main memory
Page-table base register (PTBR) points to the page table
Page-table length register (PTLR) indicates size of the page table
In this scheme every data/instruction access requires two memory accesses
One for the page table and one for the data / instruction
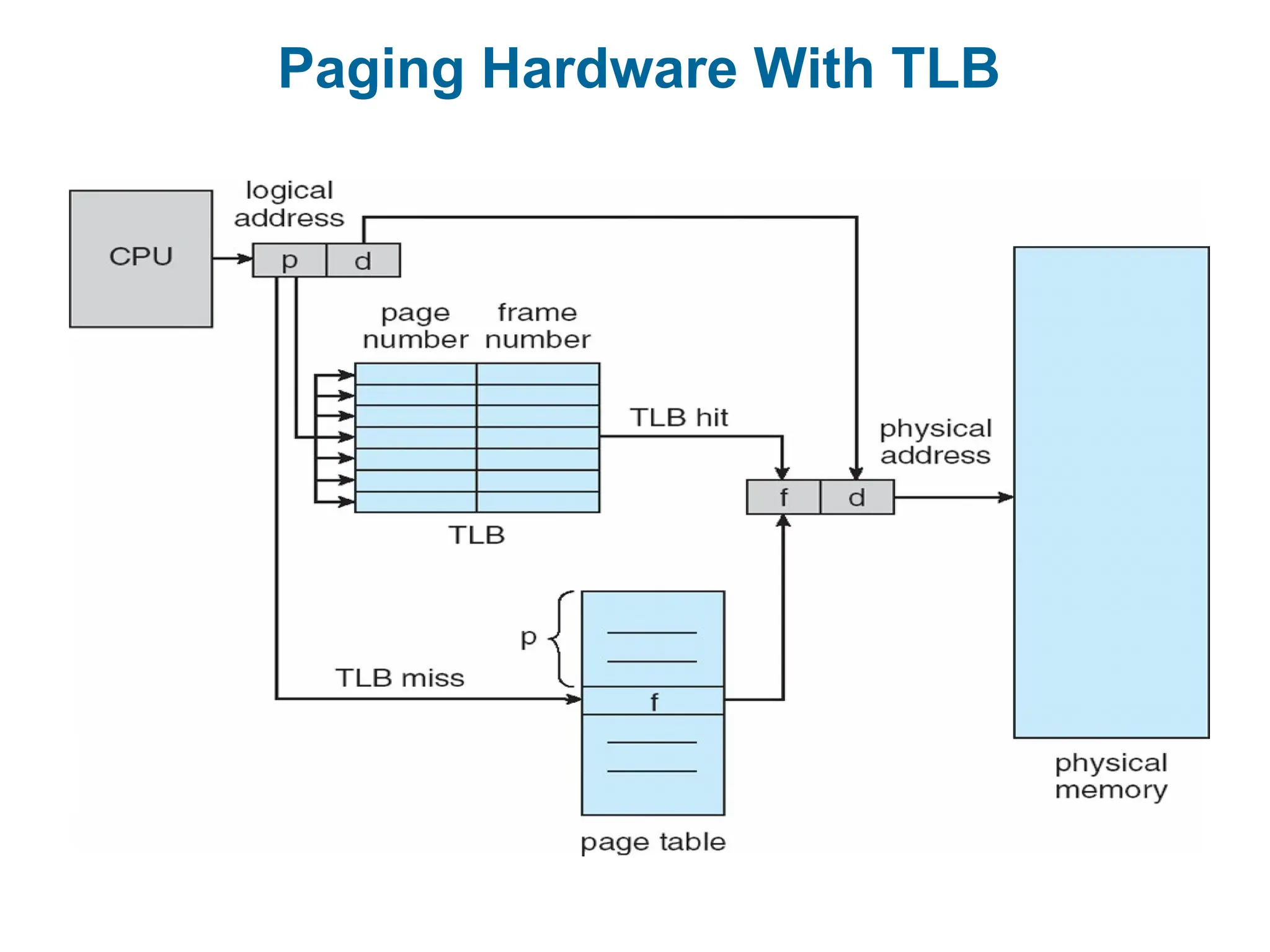
The two memory access problem can be solved by the use of a special fast-
lookup hardware cache called associative memory or translation look-
aside buffers (TLBs)
22.
Implementation of PageTable (Cont.)
Some TLBs store address-space identifiers (ASIDs) in each TLB
entry – uniquely identifies each process to provide address-
space protection for that process
Otherwise need to flush at every context switch
TLBs typically small (64 to 1,024 entries)
On a TLB miss, value is loaded into the TLB for faster access next
time
Replacement policies must be considered
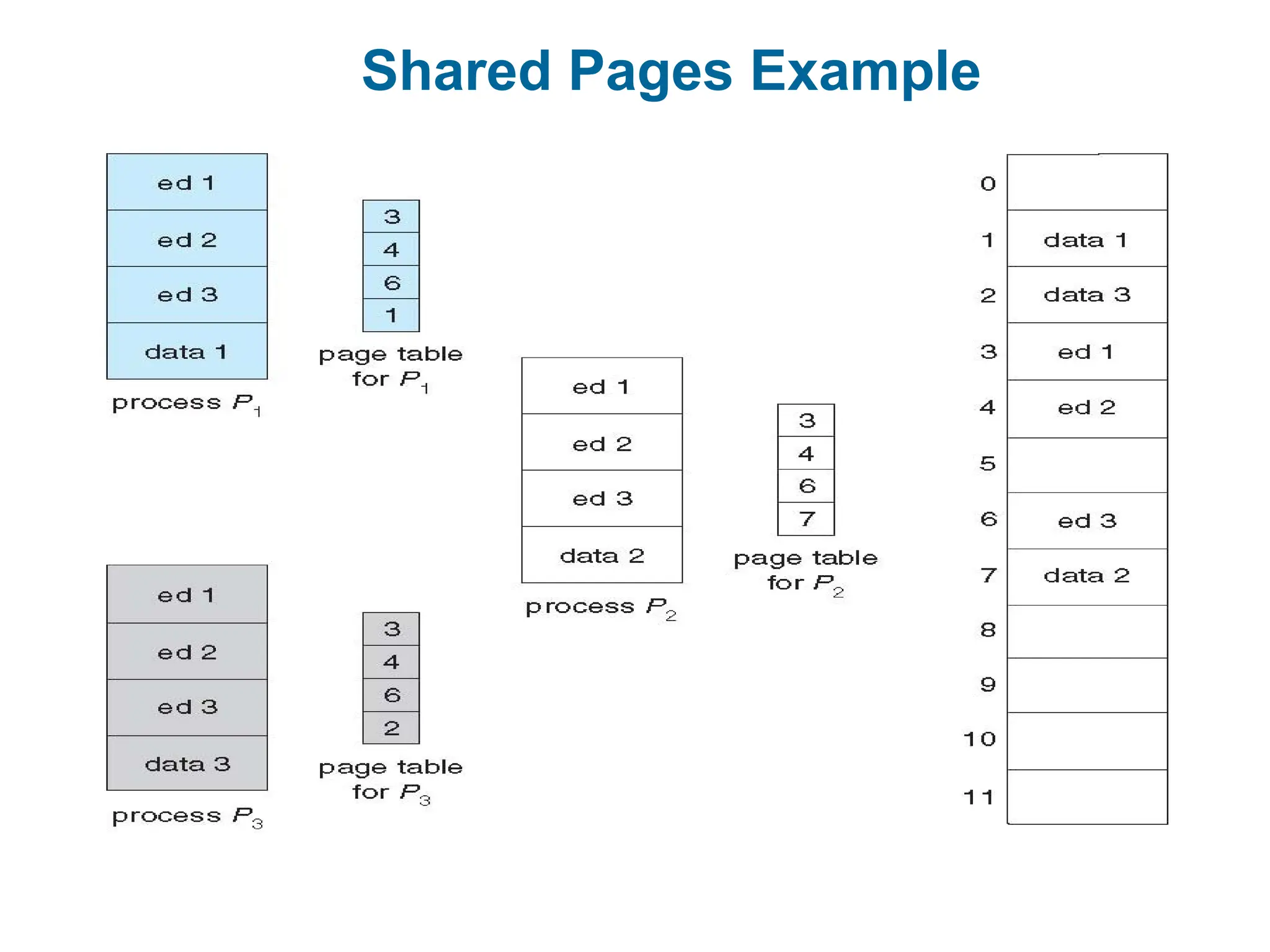
Shared Pages
Sharedcode
One copy of read-only (reentrant) code shared among
processes (i.e., text editors, compilers, window systems)
Similar to multiple threads sharing the same process space
Also useful for interprocess communication if sharing of read-
write pages is allowed
Private code and data
Each process keeps a separate copy of the code and data
The pages for the private code and data can appear anywhere in
the logical address space
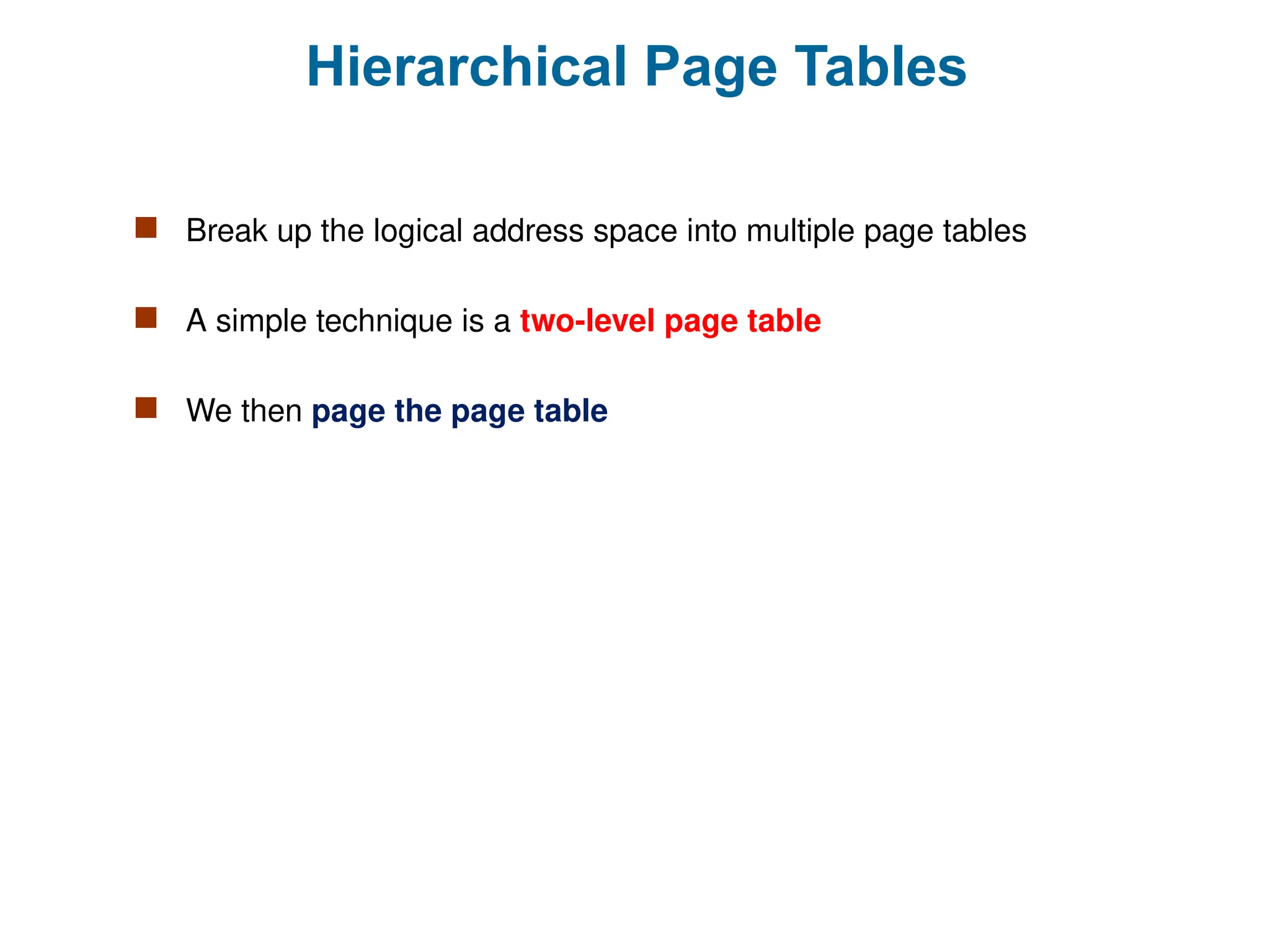
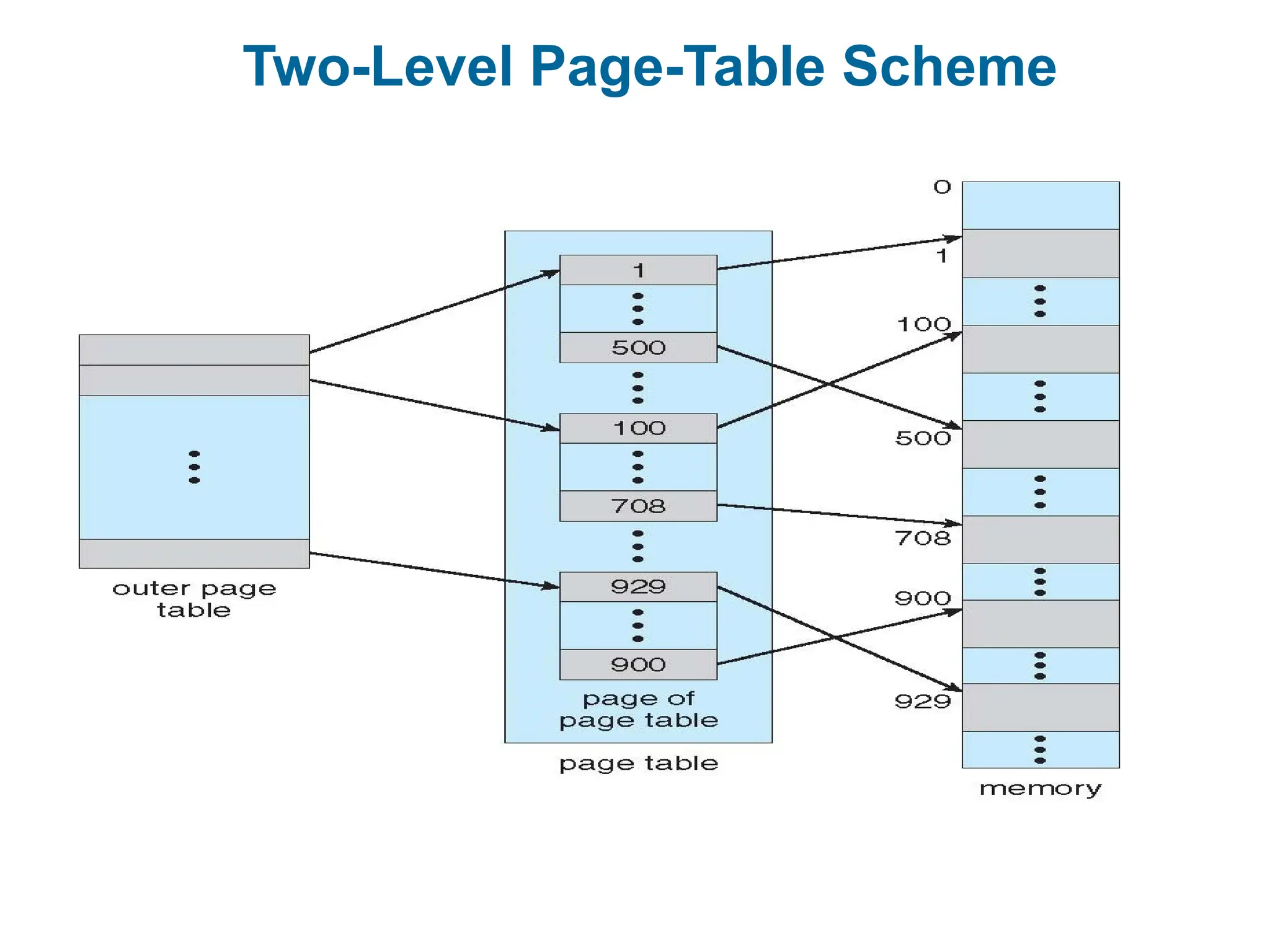
Hierarchical Page Tables
Break up the logical address space into multiple page tables
A simple technique is a two-level page table
We then page the page table
Two-Level Paging Example
A logical address (on 32-bit machine with 1K page size) is divided into:
a page number consisting of 22 bits
a page offset consisting of 10 bits
Since the page table is paged, the page number is further divided into:
a 12-bit page number
a 10-bit page offset
Thus, a logical address is as follows:
where p1 is an index into the outer page table, and p2 is the displacement
within the page of the inner page table
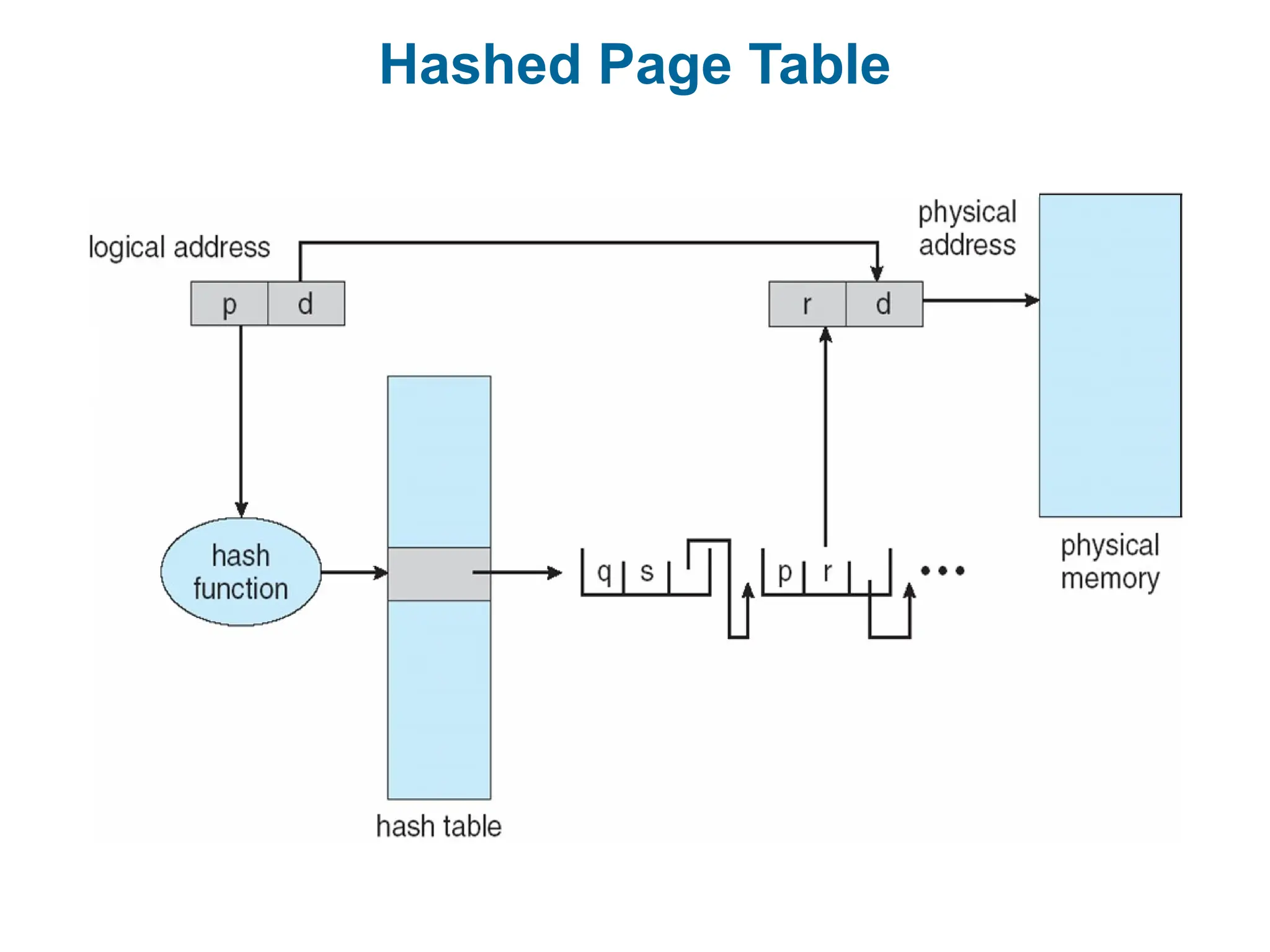
Hashed Page Tables
The virtual page number is hashed into a page table
This page table contains a chain of elements hashing to the same
location
Each element contains (1) the virtual page number (2) the value of
the mapped page frame (3) a pointer to the next element
Virtual page numbers are compared in this chain searching for a
match
If a match is found, the corresponding physical frame is extracted
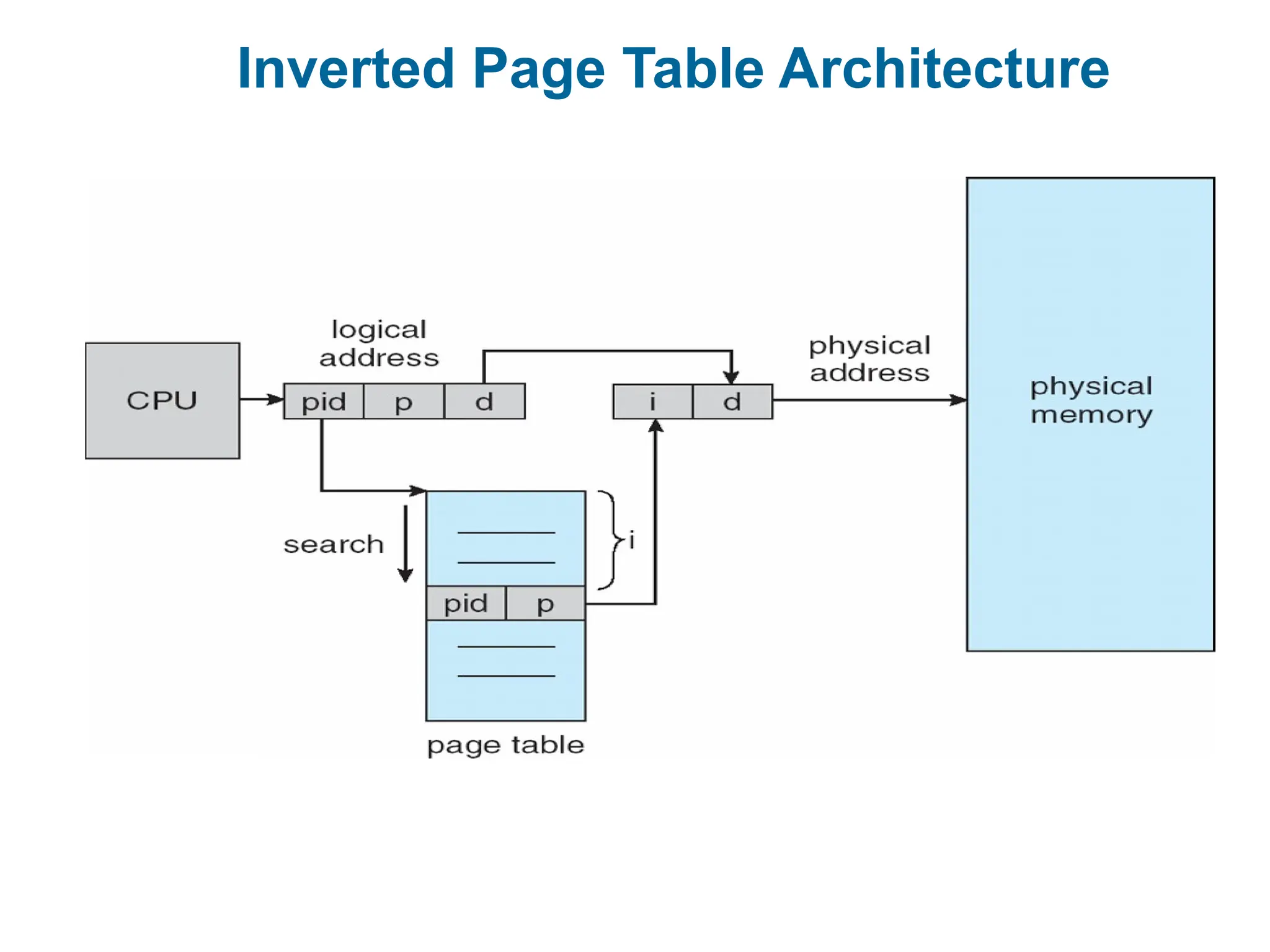
Inverted Page Table
Rather than each process having a page table and keeping track of all possible logical
pages, track all physical pages
One entry for each real page of memory
Entry consists of the virtual address of the page stored in that real memory location, with
information about the process that owns that page
Decreases memory needed to store each page table, but increases time needed to
search the table when a page reference occurs
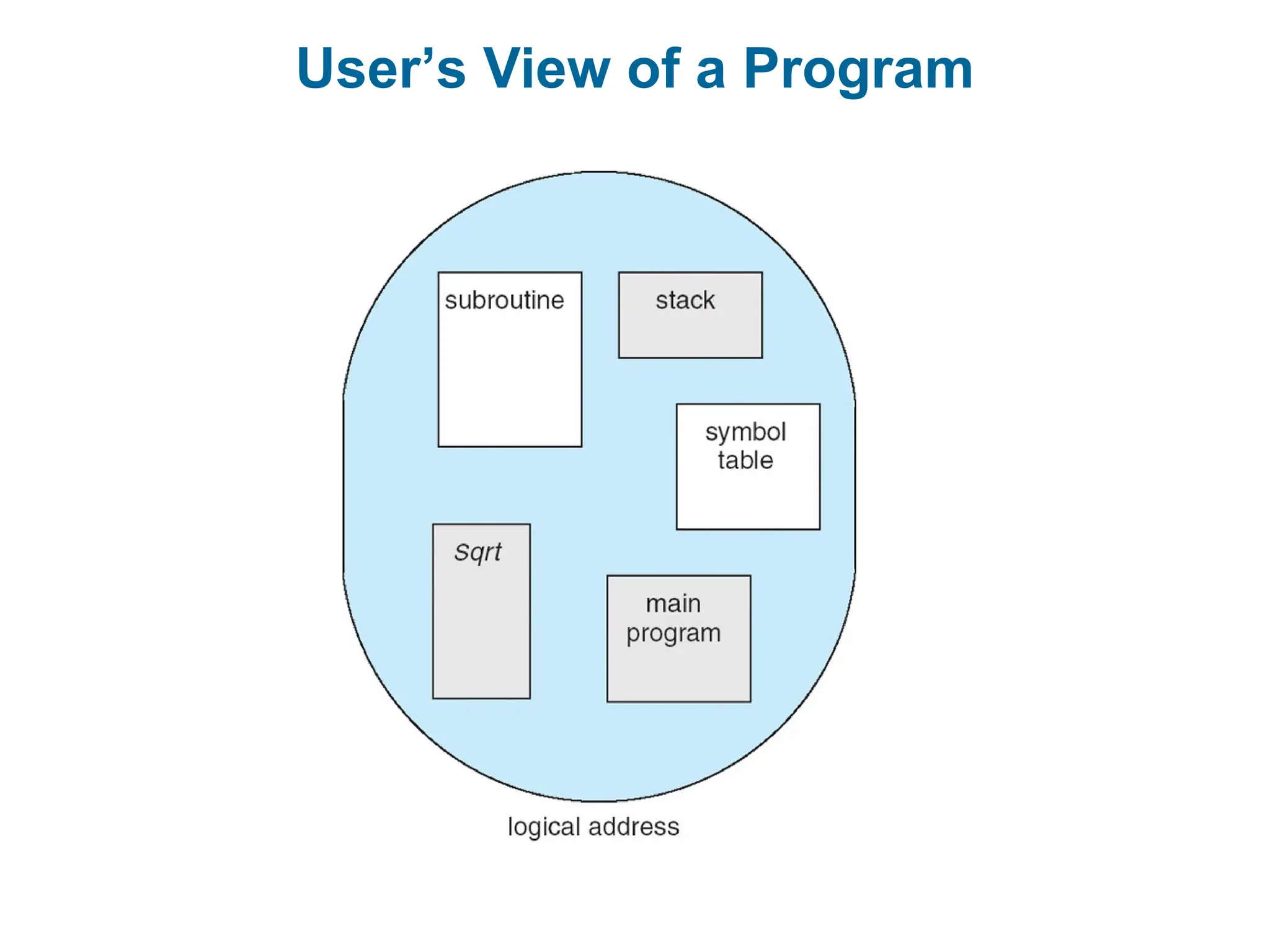
Segmentation
Memory-management schemethat supports user view of memory
A program is a collection of segments
A segment is a logical unit such as:
main program
procedure
function
method
object
local variables, global variables
common block
stack
symbol table
arrays
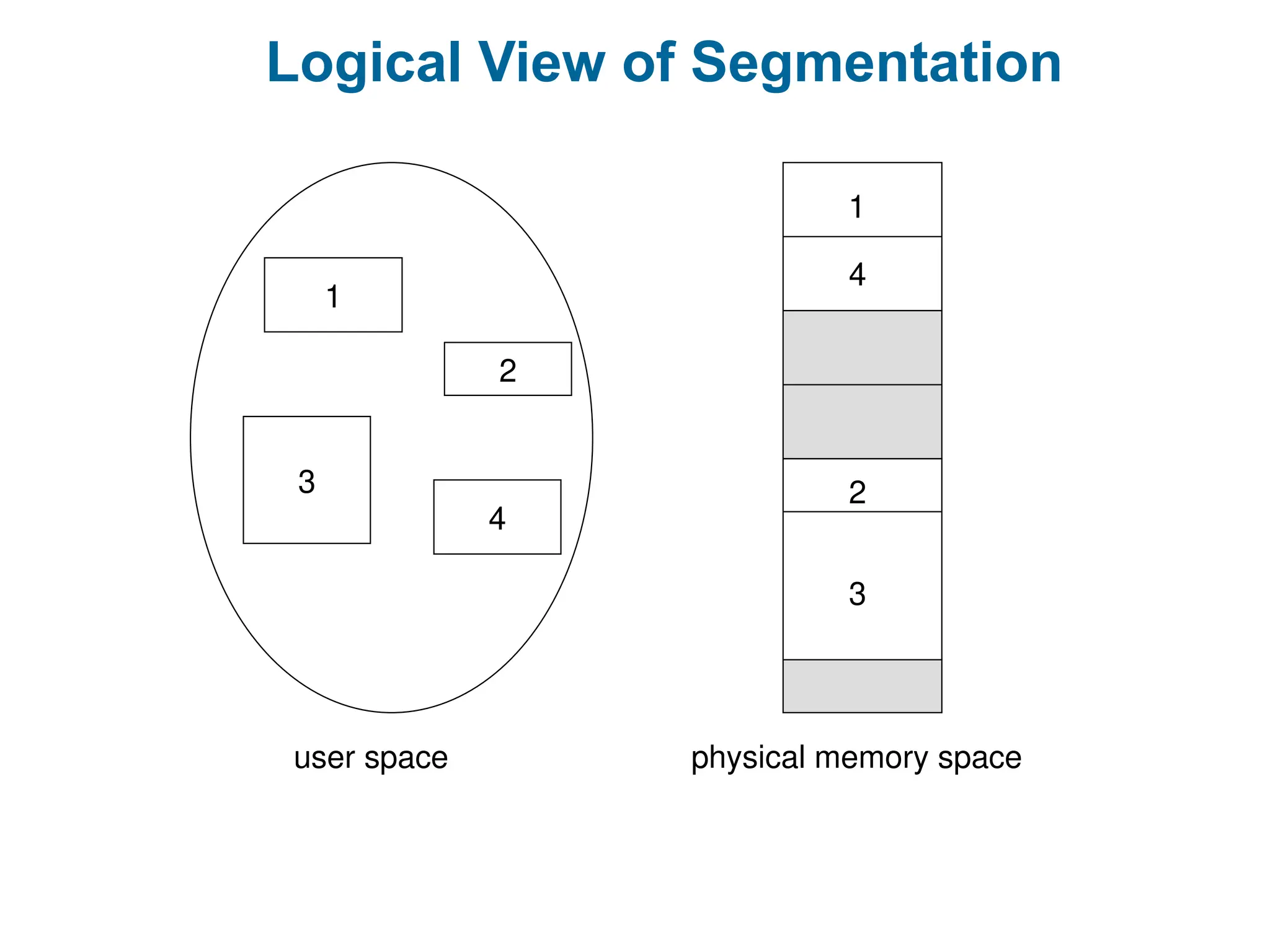
Logical View ofSegmentation
1
3
2
4
1
4
2
3
user space physical memory space
38.
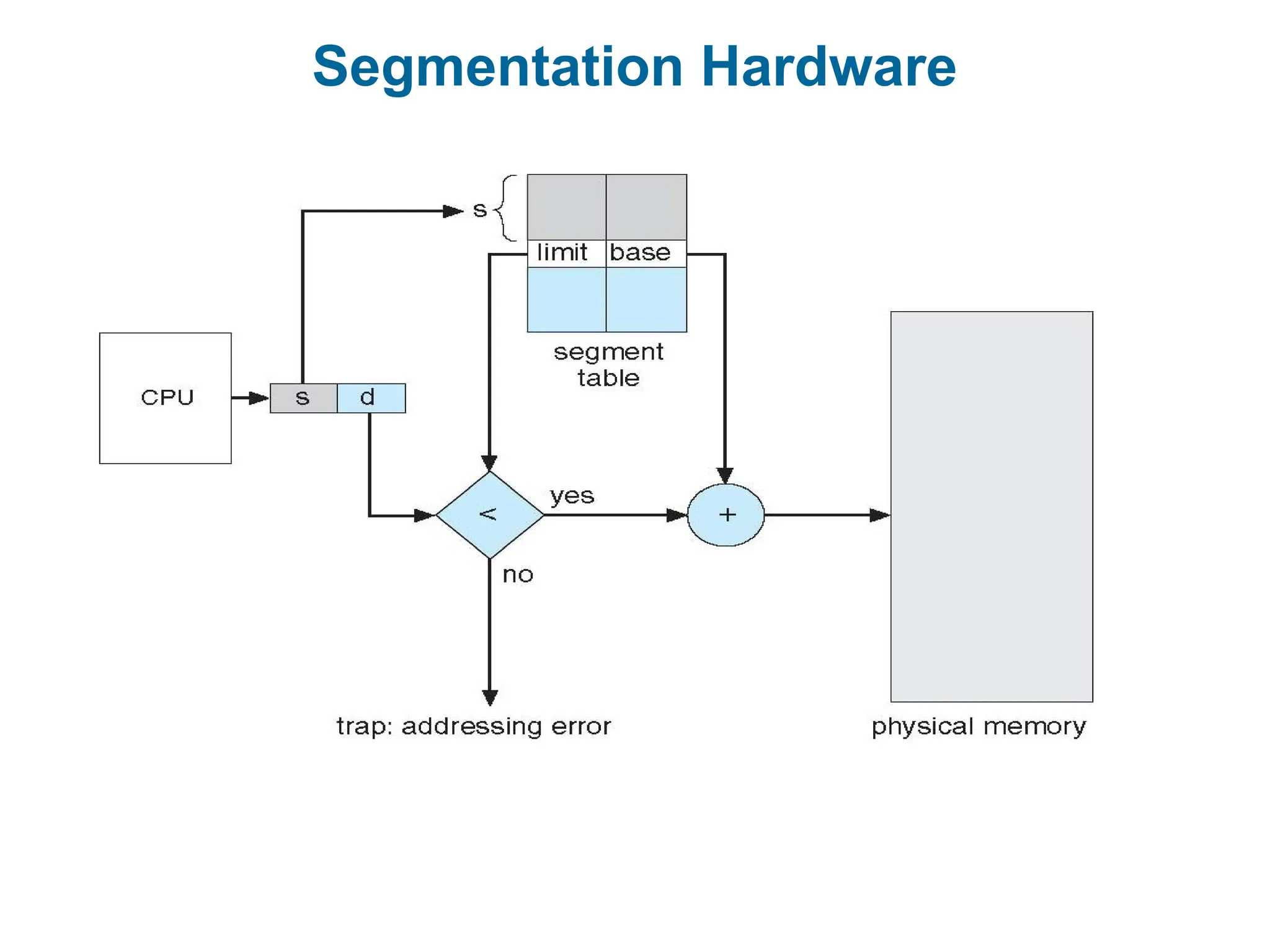
Segmentation Architecture
Logicaladdress consists of a two tuple:
<segment-number, offset>,
Segment table – maps two-dimensional physical addresses; each
table entry has:
base – contains the starting physical address where the
segments reside in memory
limit – specifies the length of the segment
Segment-table base register (STBR) points to the segment table
’s location in memory
Segment-table length register (STLR) indicates number of
segments used by a program;
segment number s is legal if s < STLR
Chapter 10: VirtualMemory
Background
Demand Paging
Process Creation
Page Replacement
Allocation of Frames
Thrashing
Operating System Examples
41.
Background
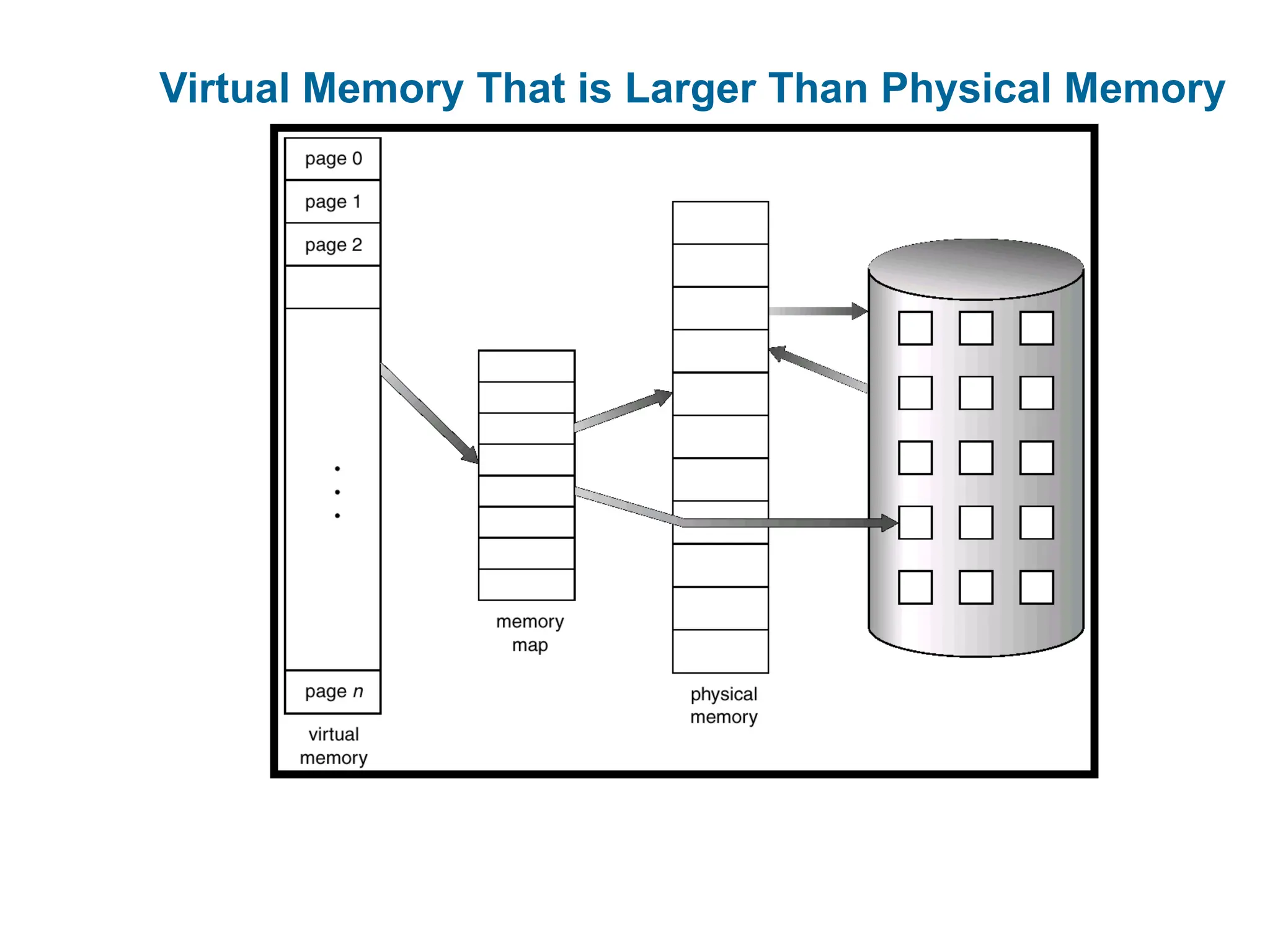
Virtual memory– separation of user logical memory from physical memory.
Only part of the program needs to be in memory for execution.
Logical address space can therefore be much larger than physical address
space.
Allows address spaces to be shared by several processes.
Virtual memory can be implemented via:
Demand paging
Demand segmentation – more complex
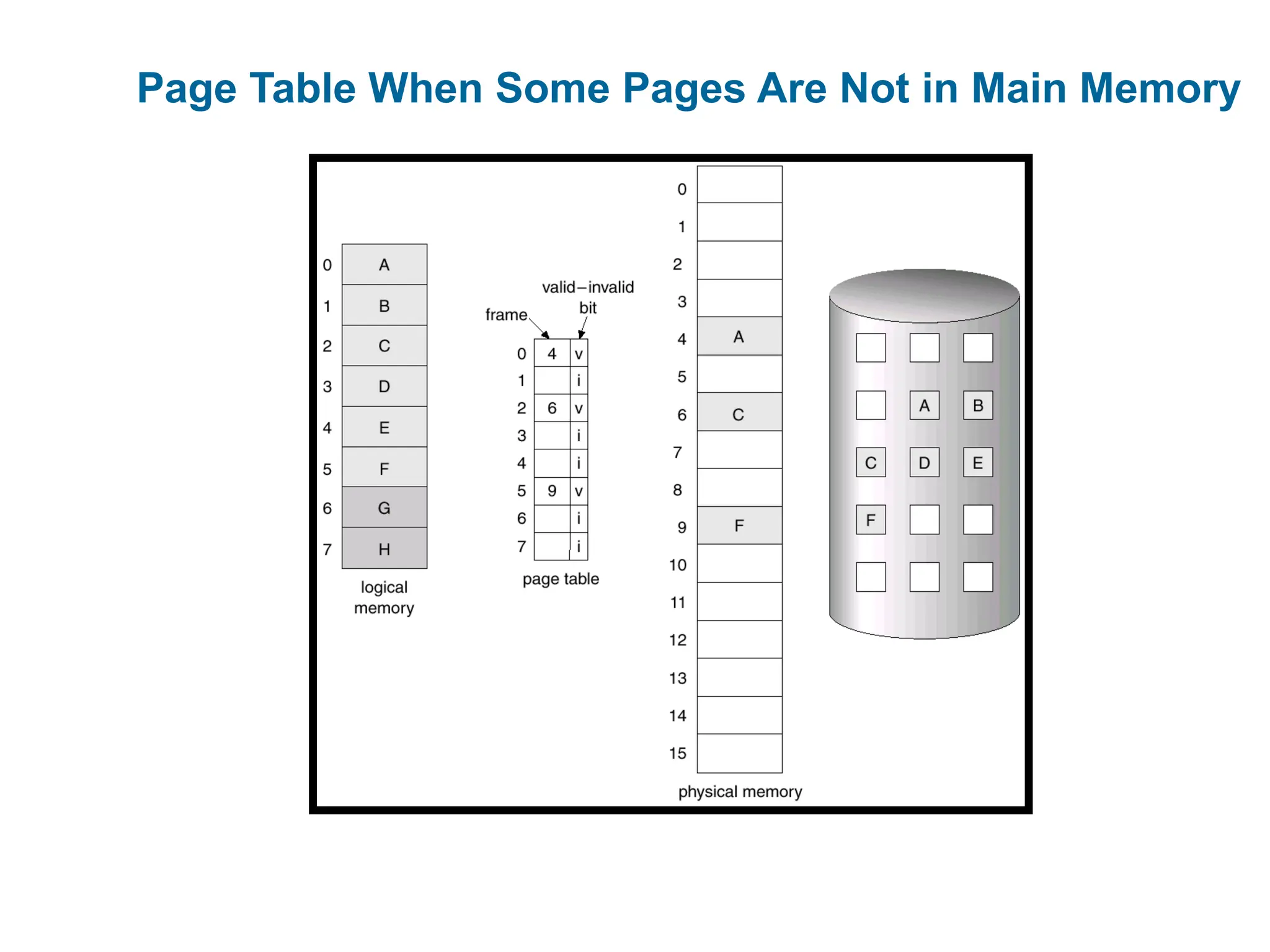
Demand Paging
Ademand-paging system is similar to a paging system with
swapping
A lazy swapper is used. It never swaps a page into memory
unless that page will be needed.
A swapper manipulate entire processes, whereas a pager is
concerned with the individual pages of process.
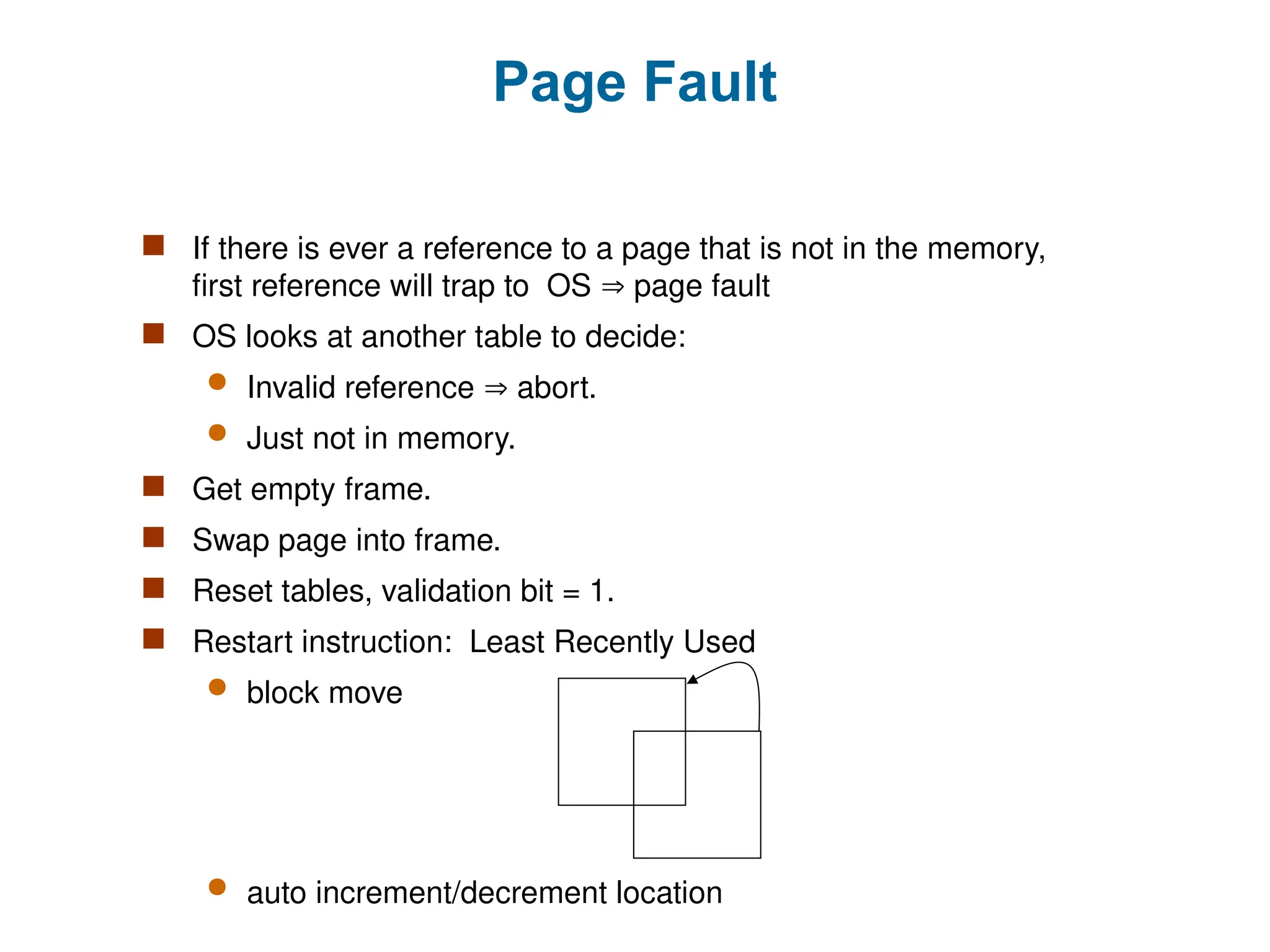
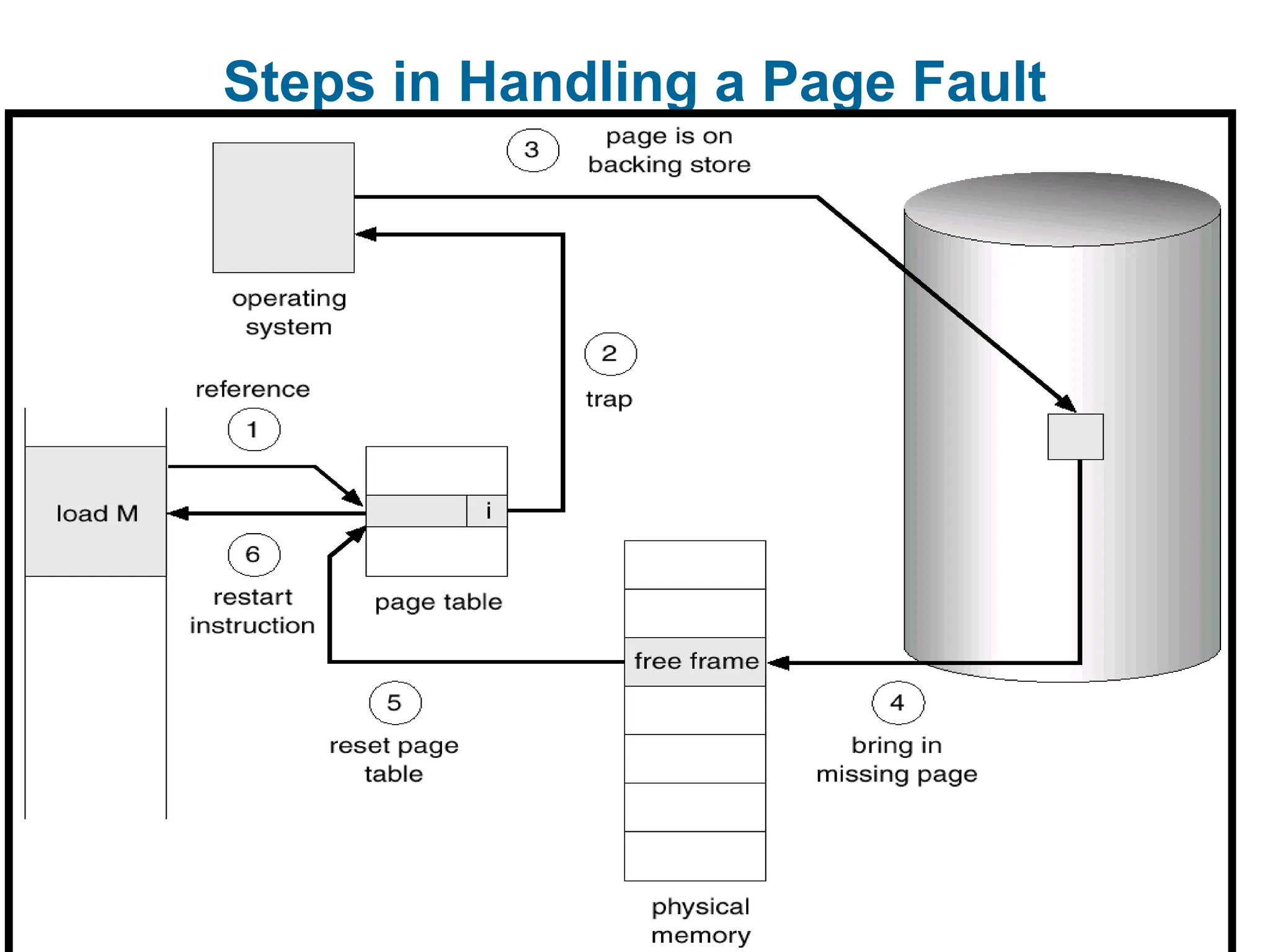
Page Fault
Ifthere is ever a reference to a page that is not in the memory,
first reference will trap to OS page fault
OS looks at another table to decide:
Invalid reference abort.
Just not in memory.
Get empty frame.
Swap page into frame.
Reset tables, validation bit = 1.
Restart instruction: Least Recently Used
block move
auto increment/decrement location
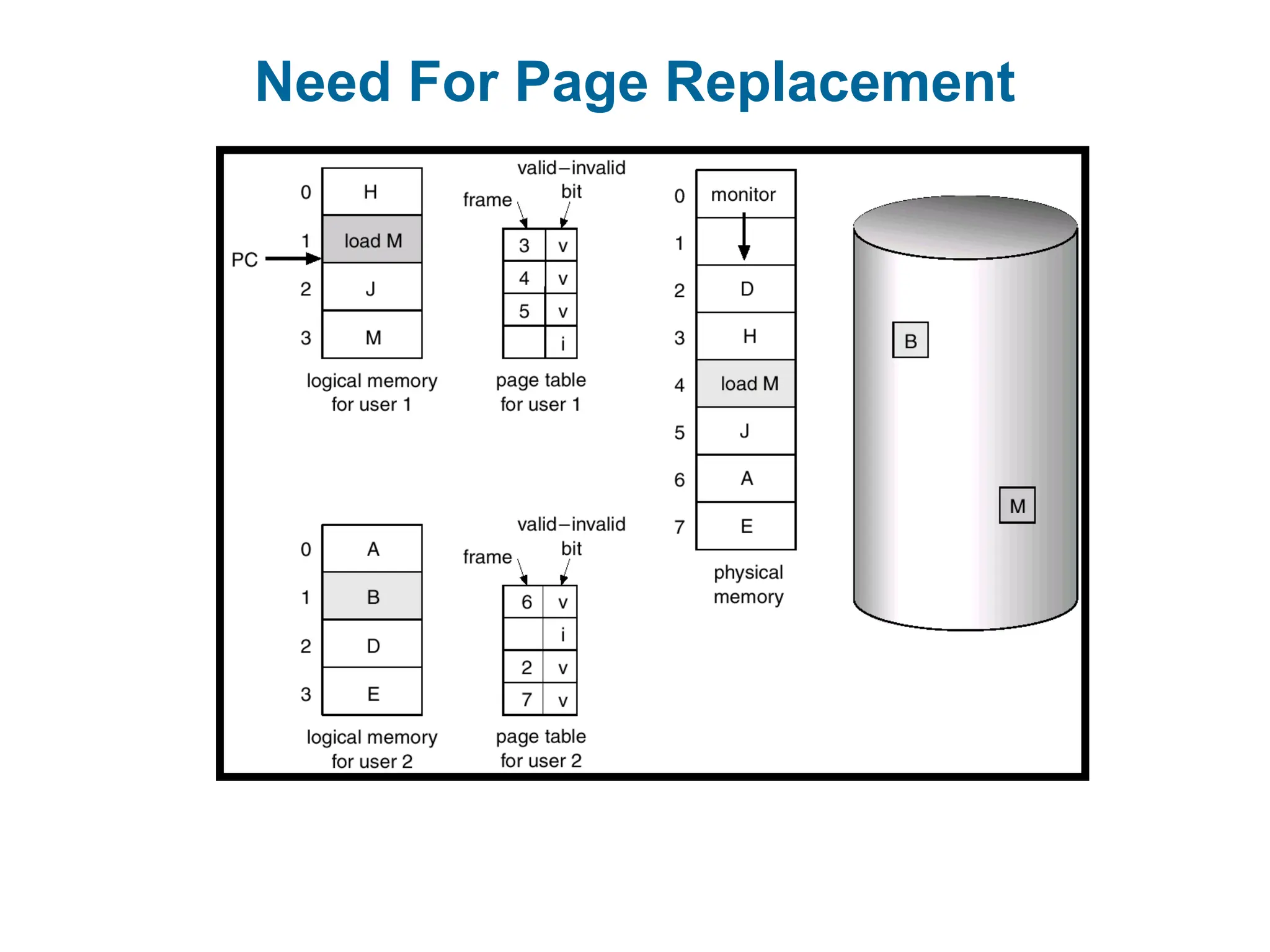
What happens ifthere is no free frame?
Page replacement – find some page in memory, but not really in use, swap it
out.
algorithm
performance – want an algorithm which will result in minimum number of
page faults.
Same page may be brought into memory several times.
49.
Process Creation
Virtualmemory allows other benefits during process creation:
- Copy-on-Write
- Memory-Mapped Files
50.
Copy-on-Write
Copy-on-Write (COW)allows both parent and child processes to
initially share the same pages in memory.
If either process modifies a shared page, only then is the page
copied.
COW allows more efficient process creation as only modified
pages are copied.
Copy-on-Write is a common technique used by several
operating systems when duplicating processes, including
Windows 2000, Linux, and Solaris 2.
Free pages for the stack and heap or copy-on-write are
allocated from a pool of zeroed-out pages.
vfork() (for virtual memory fork) is available in several versions
of UNIX (including Solaris 2) and can be used when the child
process calls exec() after creation.
51.
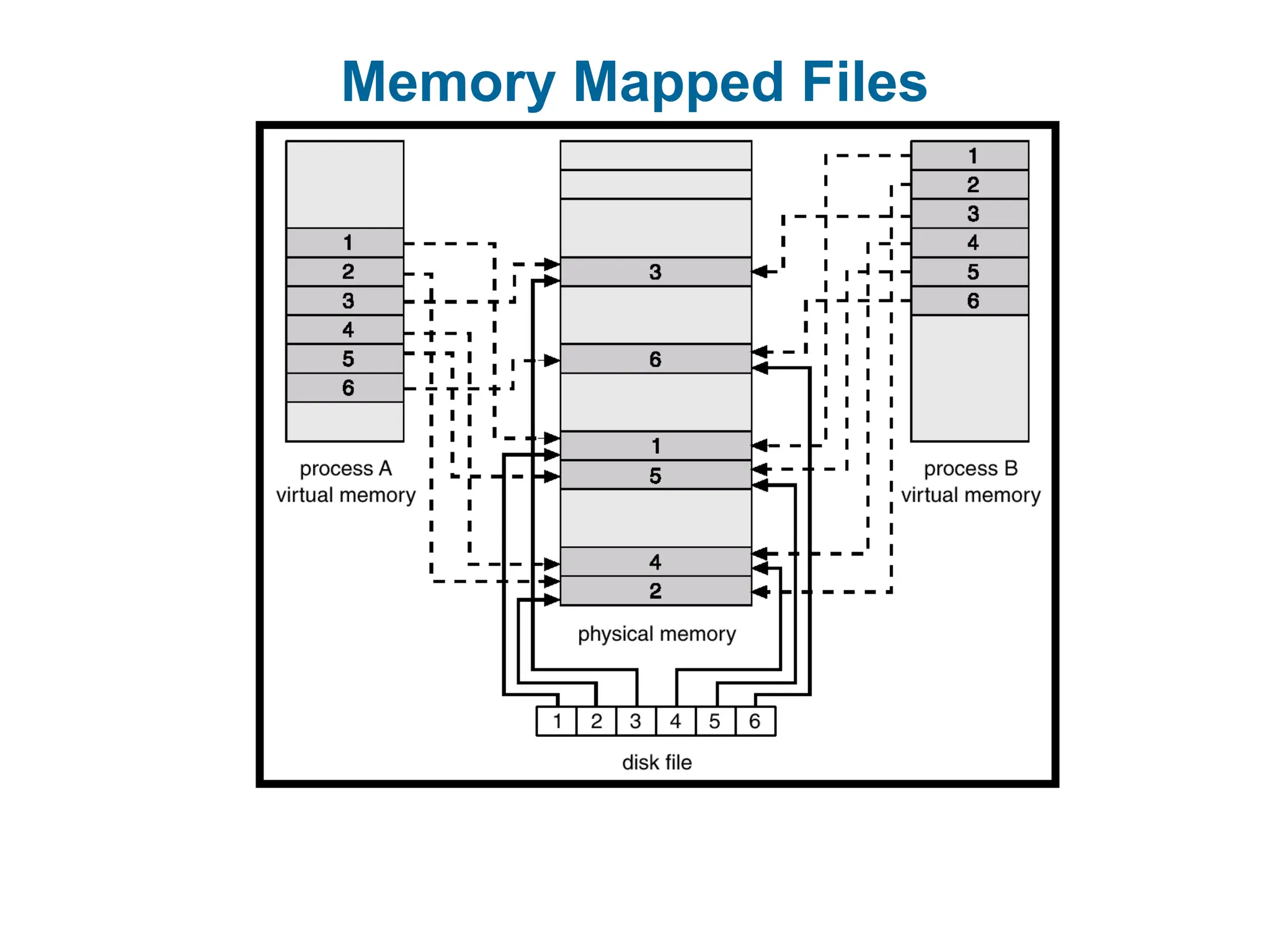
Memory-Mapped Files
Memory-mappedfile I/O allows file I/O to be treated as routine memory
access by mapping a disk block to a page in memory.
A file is initially read using demand paging. A page-sized portion of the file is
read from the file system into a physical page. Subsequent reads/writes
to/from the file are treated as ordinary memory accesses.
Simplifies file access by treating file I/O through memory rather than read()
and write() system calls.
Also allows several processes to map the same file allowing the pages in
memory to be shared.
Page Replacement
Anoperating system has to decided how much memory to
allocate to I/O and how much to program pages so as to prevent
over-allocation of memory.
Prevent over-allocation of memory by modifying page-fault
service routine to include page replacement.
If no frames are free, two page transfers are required. Use
modify (dirty) bit to reduce overhead of page transfers – only
modified pages are written to disk.
Page replacement completes separation between logical
memory and physical memory – large virtual memory can be
provided on a smaller physical memory.
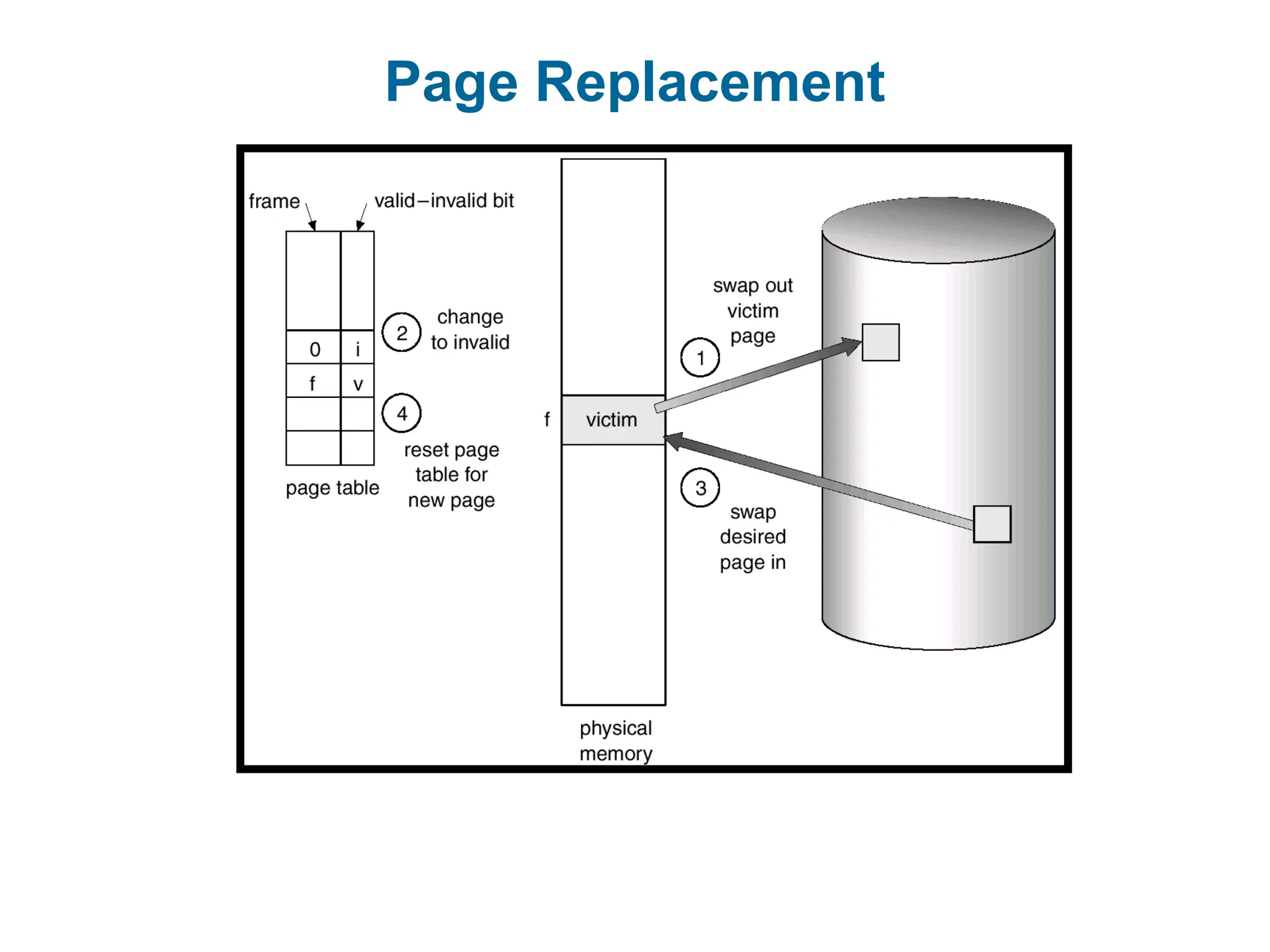
Basic Page Replacement
1.Find the location of the desired page on disk.
2. Find a free frame:
- If there is a free frame, use it.
- If there is no free frame, use a page replacement
algorithm to select a victim frame.
3. Read the desired page into the (newly) free frame. Update the
page and frame tables.
4. Restart the process.
Only the page which has been modified will be written back to
the disk.
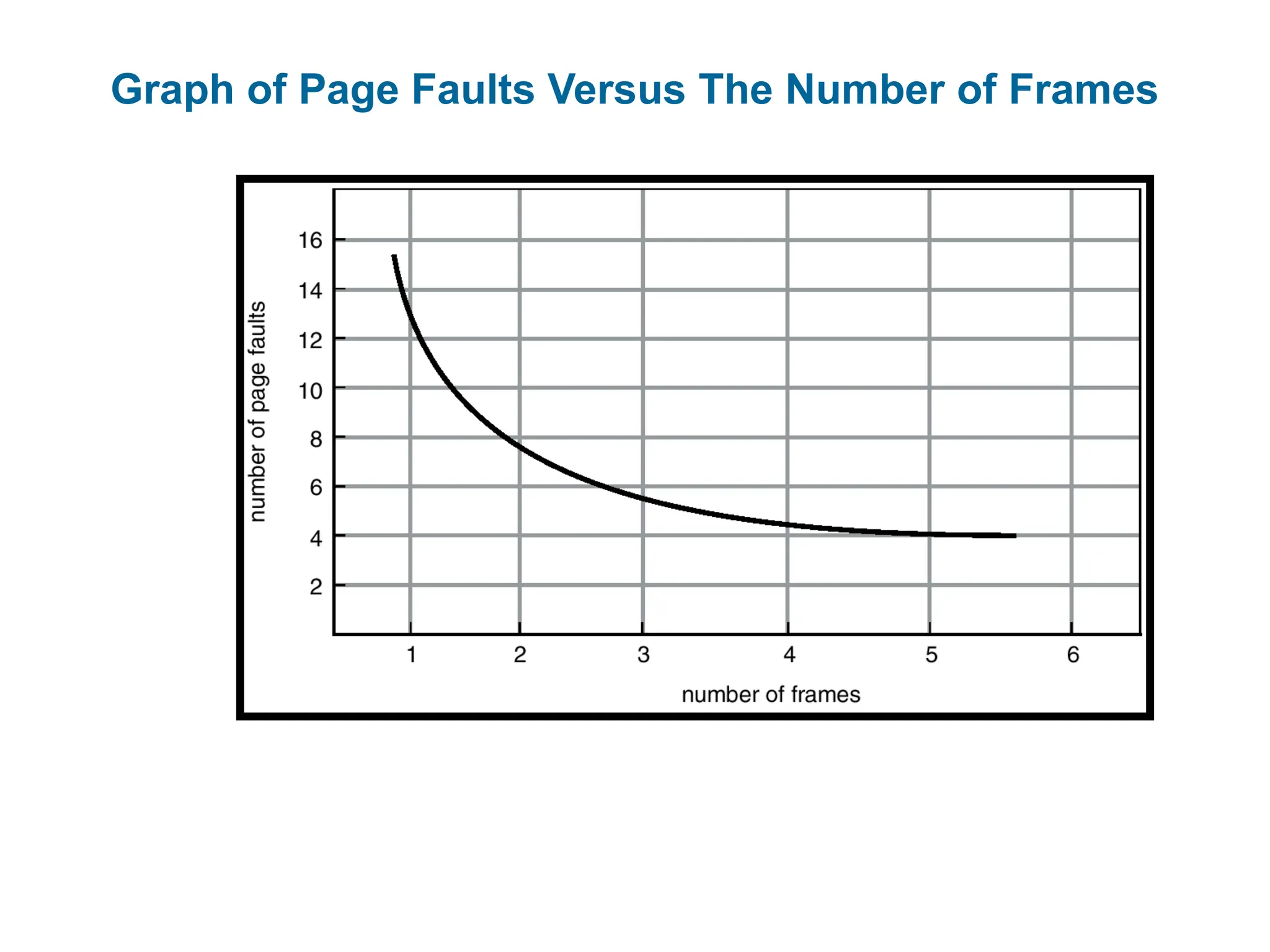
Page Replacement Algorithms
We must solve two major problems in demand paging: We must
develop:
A frame-allocation algorithm – How many frames are
allocated to each process.
A page-replacement algorithm – Which frames are
selected to be replaced.
Which algorithm? We want lowest page-fault rate.
Evaluate algorithm by running it on a particular string of memory
references (reference string) and computing the number of
page faults on that string.
They can be generated by a random generator or from the
system memory reference record.
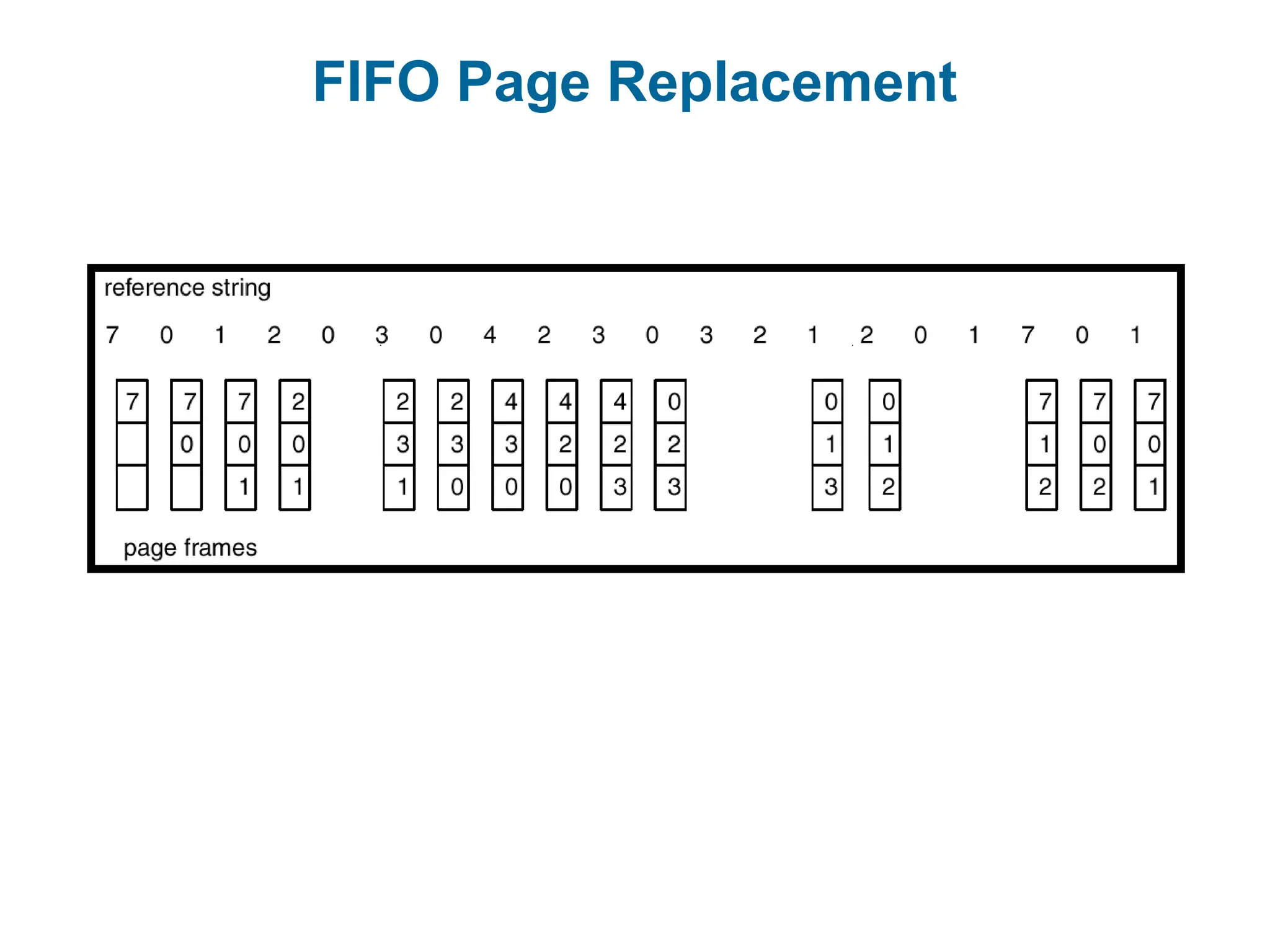
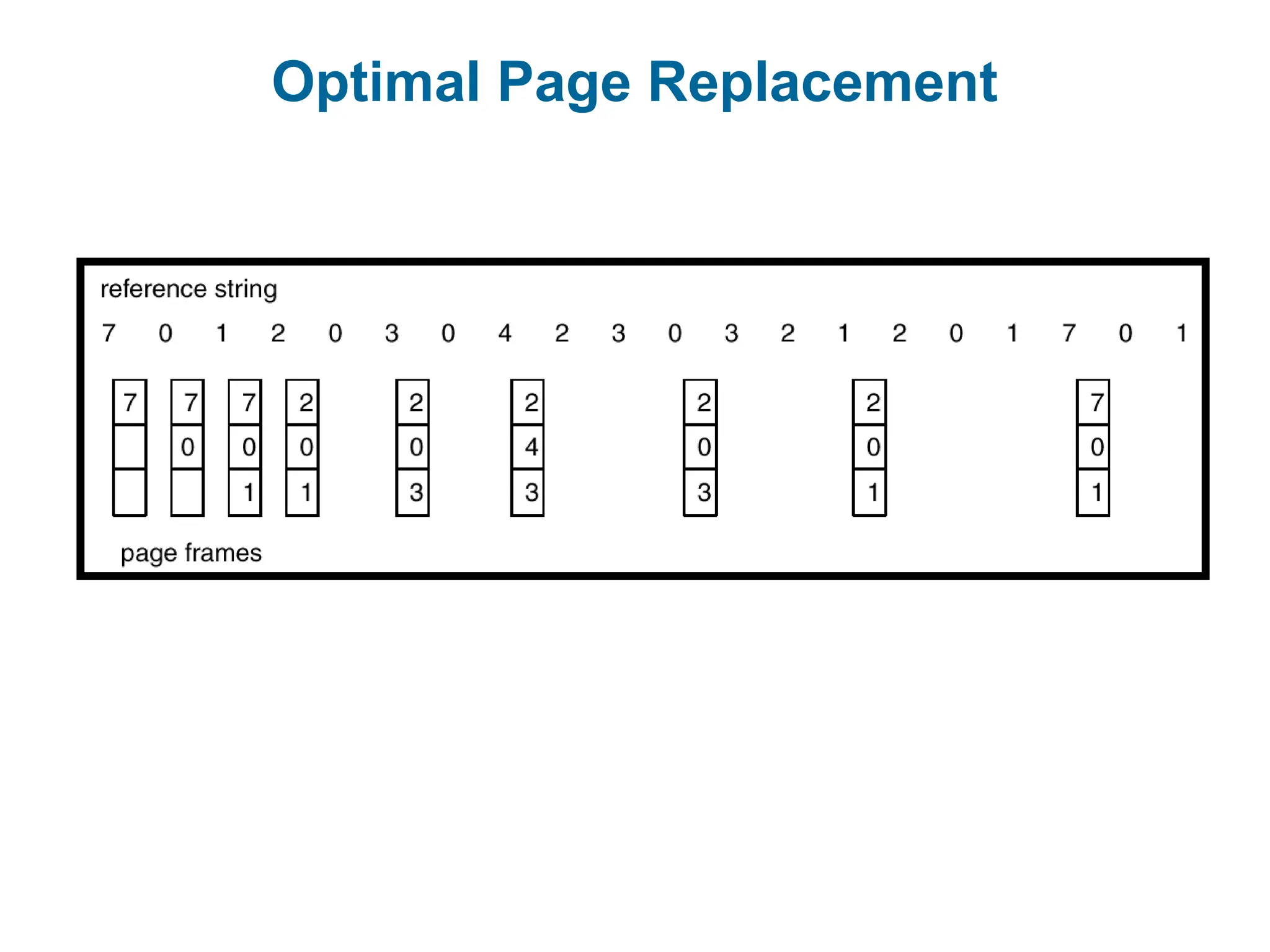
In all our examples, the reference string is
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5.
Optimal Algorithm
Replacepage that will not be used for longest period of time.
4 frames example
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
How do you know this?
Used for measuring how well your algorithm performs.
1
2
3
4
6 page faults
4 5
Optimal Algorithm
What’sthe best we can possible do?
Assume perfect knowledge of the future
Not realizable in practice (usually)
Useful for comparison: if another algorithm is within 5% of optimal, not
much more needs to be done.
Algorithm: replace the page that will be used furthest in the future.
Only works if we know the whole sequence!
Can be approximated by running the program twice
o Once to generate the reference trace
o Once (ore more) to apply the optimal algorithm
Nice, but not achievable in real systems.
65.
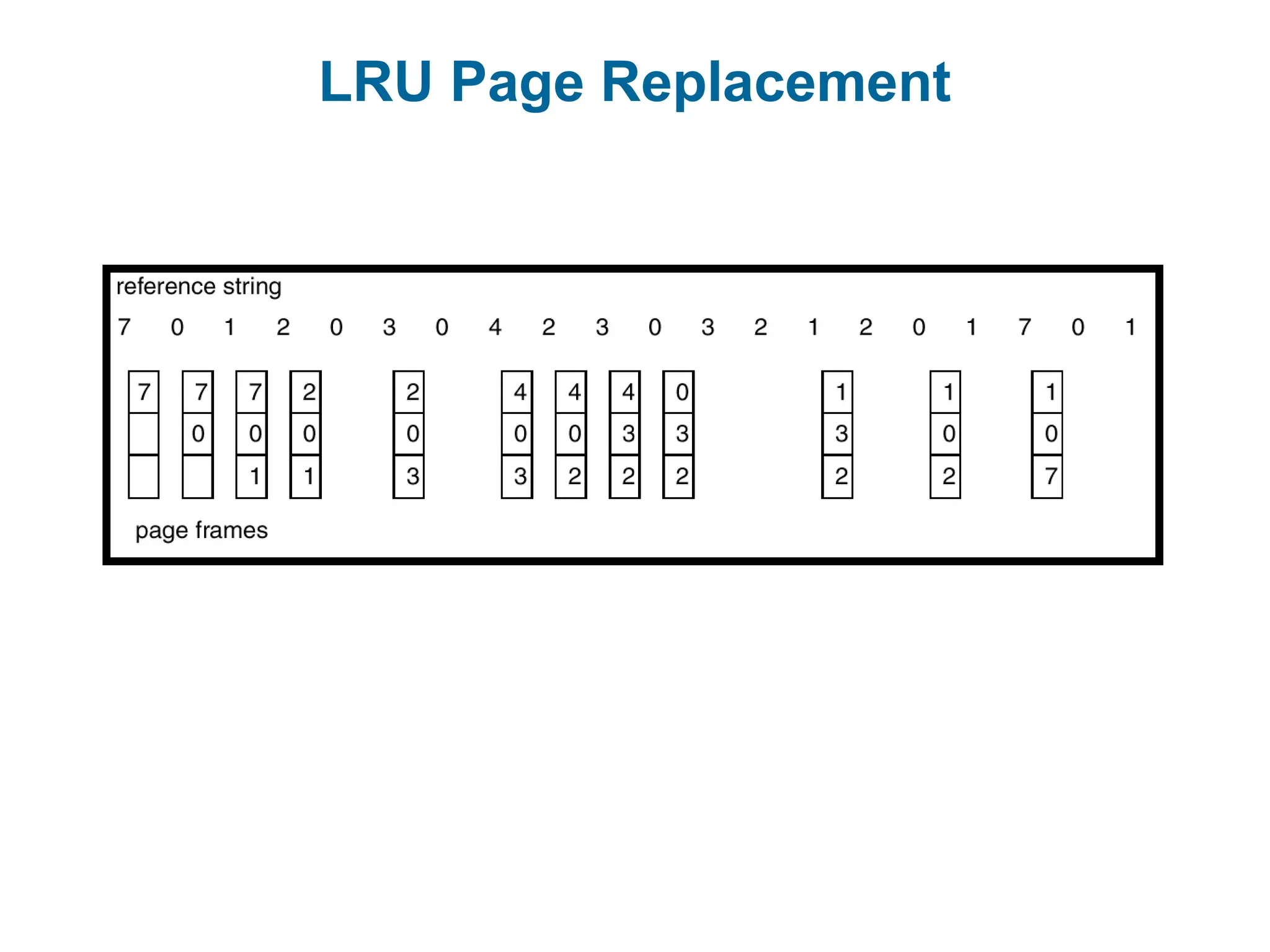
Least Recently Used(LRU) Algorithm
Reference string: 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5
Counter implementation
Every page entry has a counter; every time page is referenced through
this entry, copy the clock into the counter.
When a page needs to be changed, look at the counters to determine
which are to change.
1
2
3
5
4
4 3
5
LRU Algorithm (Cont.)
How to implement LRU replacement?
Counter implementation – associate with each page-table entry
a time-of-use field, and add a logical clock or counter.
The contents of the clock register are copied to the time-of-
use field.
Search the page table and Replace the page with the
smallest time value.
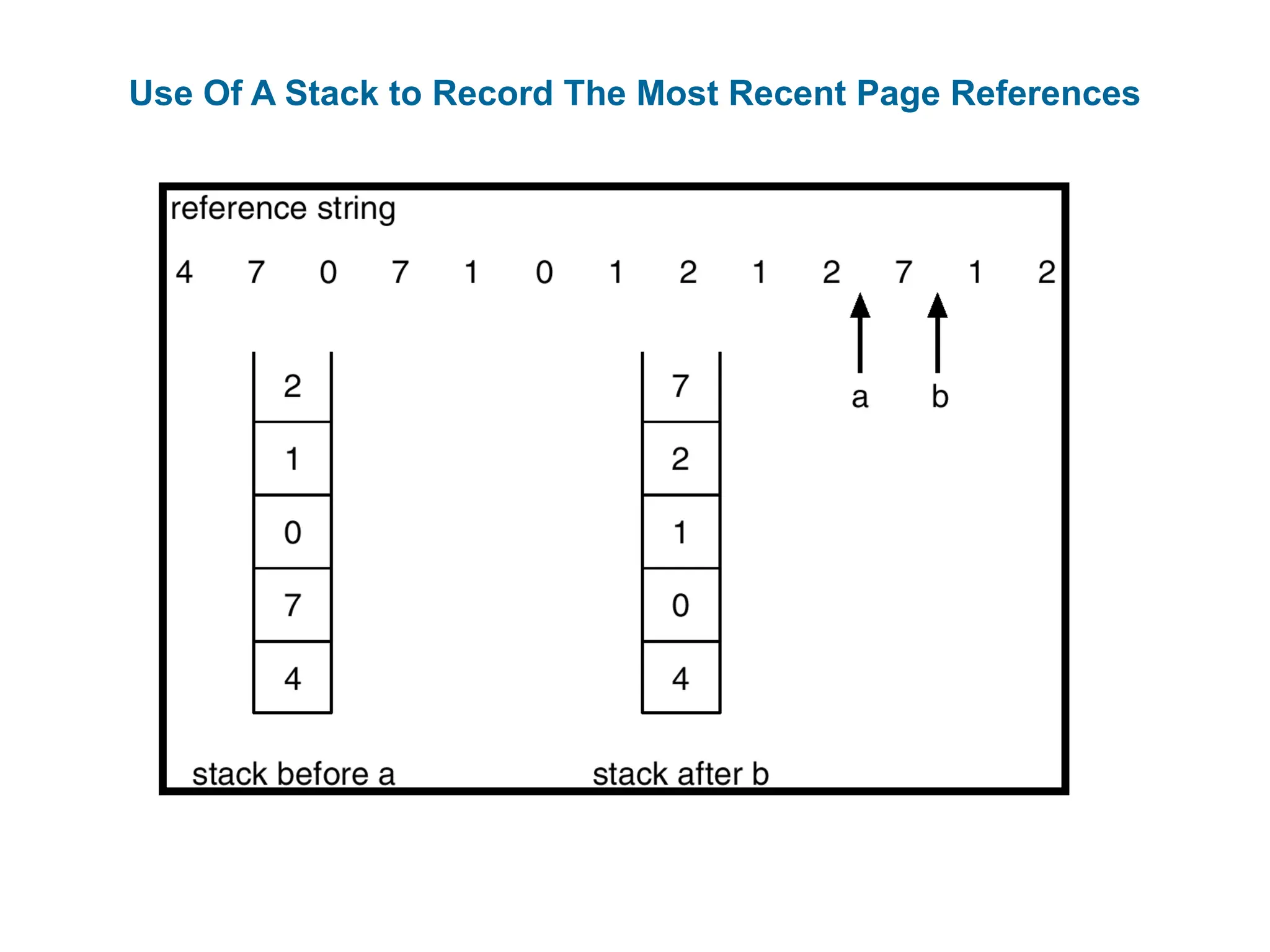
Stack implementation – keep a stack of page numbers in a
double link form:
Page referenced:
move it to the top
requires 6 pointers to be changed at worst
No search for replacement
Neither implementation of LRU would be conceivable without
hardware assistance beyond the standard TLB registers.
68.
Use Of AStack to Record The Most Recent Page References
69.
LRU Approximation Algorithms
Not-recently-used (NRU)
Each page has a reference bit and modified bit.
R = referenced (read or written recently)
M = modified (written to)
When a process starts, both bits R and M are set to 0 for all
pages.
Bits are set when page is referenced and/or modified.
Pages are classified into four classes
class R M
----- --- ---
0 0 0
1 0 1
2 1 0
3 1 1
70.
LRU Approximation Algorithms
Not-recently-used (NRU)
Periodically, (on each clock interval (20msec) ), the R bit is
cleared. (i.e. R = 0).
The NRU algorithm selects to remove a page at random
from the lowest numbered, nonempty class.
Easy to understand and implement.
Performance adequate (though not optimal)
71.
LRU Approximation Algorithms
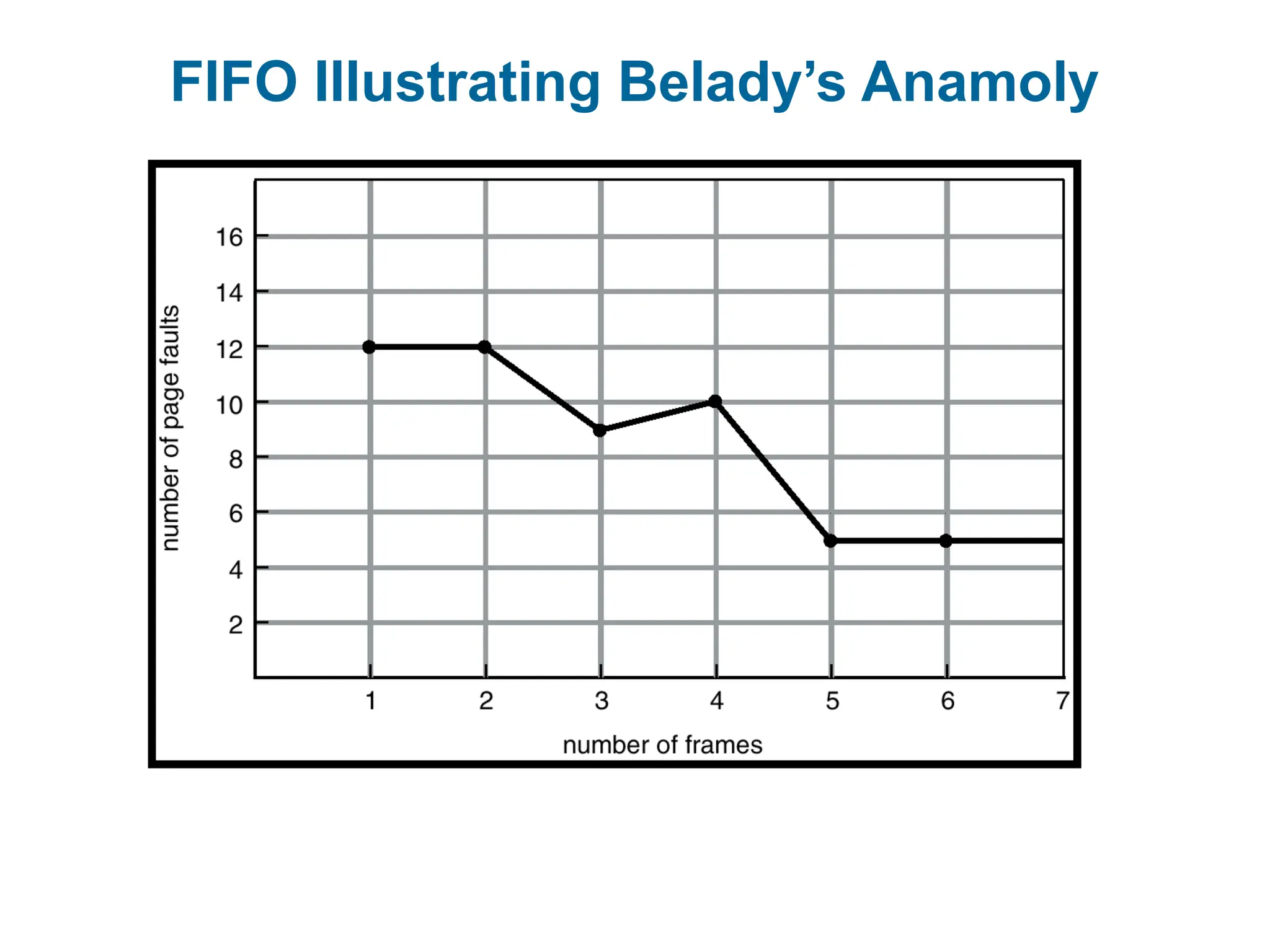
First-In, First-Out: (FIFO)
a list is maintained, with the oldest page at the front of the
list.
the page at the front of the list is selected to be evicted.
Advantage: easy to implement
PROBLEM: Important, frequently-used pages may be
evicted.
72.
LRU Approximation Algorithms
Reference bit
With each page associate a bit, initially = 0
When page is referenced bit set to 1.
Replace the one which is 0 (if one exists). We do not know
the order, however.
This leads to many page-replacement algorithms that
approximate LRU replacement.
Additional-Reference-Bits Algorithm
We can keep an 8-bit byte for each page in a table in memory.
At regular intervals, a timer interrupt transfers control to the
operating system. The operating system shifts the reference
bit right.
The page with the lowest number is the LRU page.
73.
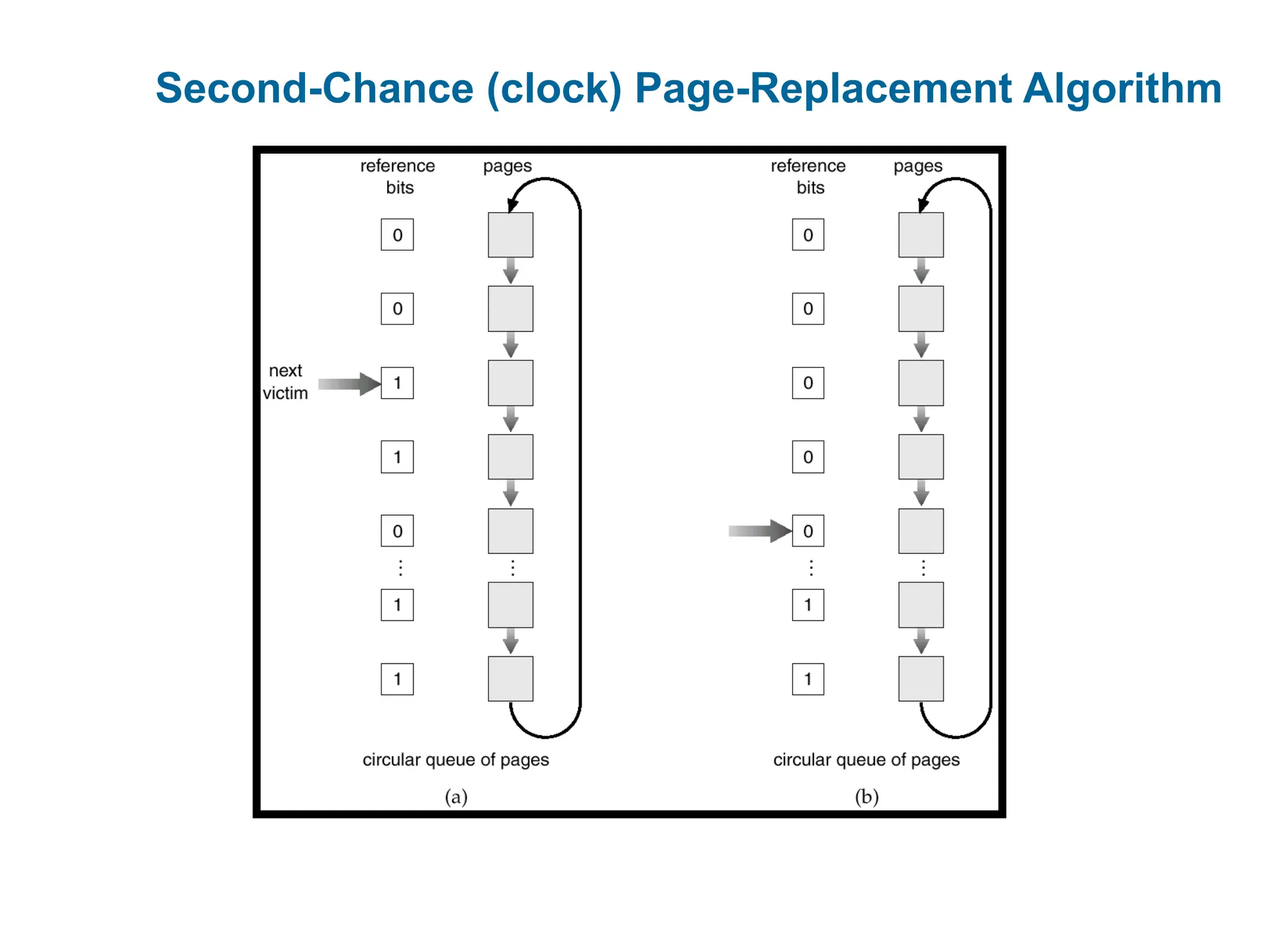
LRU Approximation Algorithms
In the extreme case, the number can be reduced to zero, leaving
only the reference bit. This is called the second-chance (clock)
algorithm.
Second chance – clock implentation
Need reference bit.
Clock replacement.
If reference bit is 0, throw the page out.
If page to be replaced (in clock order) has reference bit = 1.
then:
set reference bit 0.
leave page in memory.
Continue to search for a free page and replace it (in
clock order), subject to same rules.
Counting Algorithms
Keepa counter of the number of references that have been
made to each page.
LFU Algorithm: replaces page with smallest count.
MFU Algorithm: based on the argument that the page with the
smallest count was probably just brought in and has yet to be
used.
Page-buffering algorithm
Keep a pool of free frames.
Maintain a list of modified pages – write out the modified
page when the paging device is idle.
Keep a pool of free frames, but remember which page was
in each frame.
76.
Summary of LRUAlgorithm
Few computers have the necessary hardware to implement full
LRU.
Counter-based method could be done, but it’s slow to find
the desired page.
Linked-list method (indicated above) impractical in hardware
Approximate LRU with Not Frequently Used (NFU)
At each clock interrupt, scan through page table
If the reference bit (R) is 1 for a page, add one to its counter
value.
On replacement, pick the page with the lowest counter
value.
Problem: no notion of age – pages with high counter values will
tend to keep them.
Solution: put aging information into the counter.
77.
Summary of PageReplacement Algorithm
OPT (Optimal): Not implementable, but useful as a benchmark
NRU (Not Recently Used): Crude
FIFO (First-In First-Out): Might throw out useful pages
Second chance: Improvement over FIFO
Clock: Better implementation of second chance
LRU (Least Recently Used): Excellent, but hard to implement
exactly
NFU (Not Frequently Used): Poor approximation to LRU
MFU (Most Frequently Used): Poor approximation to LRU
Aging: Good approximation to LRU, efficient to implement
78.
Allocation of Frames
Each process needs minimum number of pages.
Example: IBM 370 – 6 pages to handle SS MOVE instruction:
instruction is 6 bytes, might span 2 pages.
2 pages to handle from.
2 pages to handle to.
Two major allocation schemes.
fixed allocation
priority allocation
79.
Fixed Allocation
Equalallocation – e.g., if 100 frames and 5 processes, give
each 20 pages.
Proportional allocation – Allocate according to the size of
process.
m
S
s
p
a
m
s
S
p
s
i
i
i
i
i
i
for
allocation
frames
of
number
total
process
of
size
59
64
137
127
5
64
137
10
127
10
64
2
1
2
a
a
s
s
m
i
80.
Priority Allocation
Usea proportional allocation scheme using priorities rather than size.
If process Pi generates a page fault,
select a replacement from its frames.
select a replacement from frames of any process with lower priority
number.
81.
Global vs. LocalAllocation
Global replacement – process selects a replacement frame from the set of
all frames; one process can take a frame from another.
Local replacement – each process selects from only its own set of allocated
frames.
82.
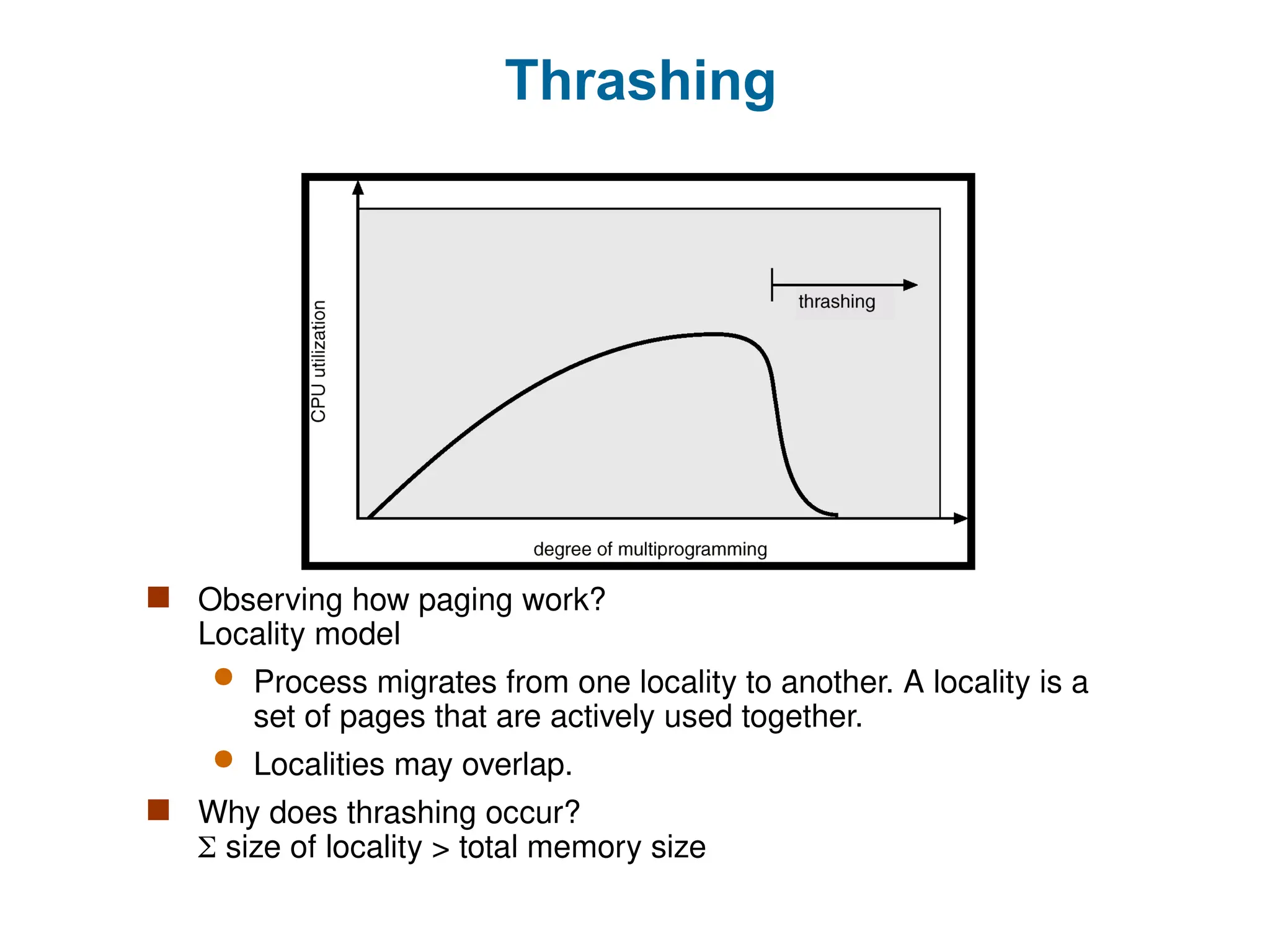
Thrashing
If aprocess does not have “enough” pages, the page-fault rate is very high.
This leads to:
low CPU utilization.
operating system thinks that it needs to increase the degree of
multiprogramming.
another process added to the system.
Thrashing a process is busy swapping pages in and out.
83.
Thrashing
Observing howpaging work?
Locality model
Process migrates from one locality to another. A locality is a
set of pages that are actively used together.
Localities may overlap.
Why does thrashing occur?
size of locality > total memory size
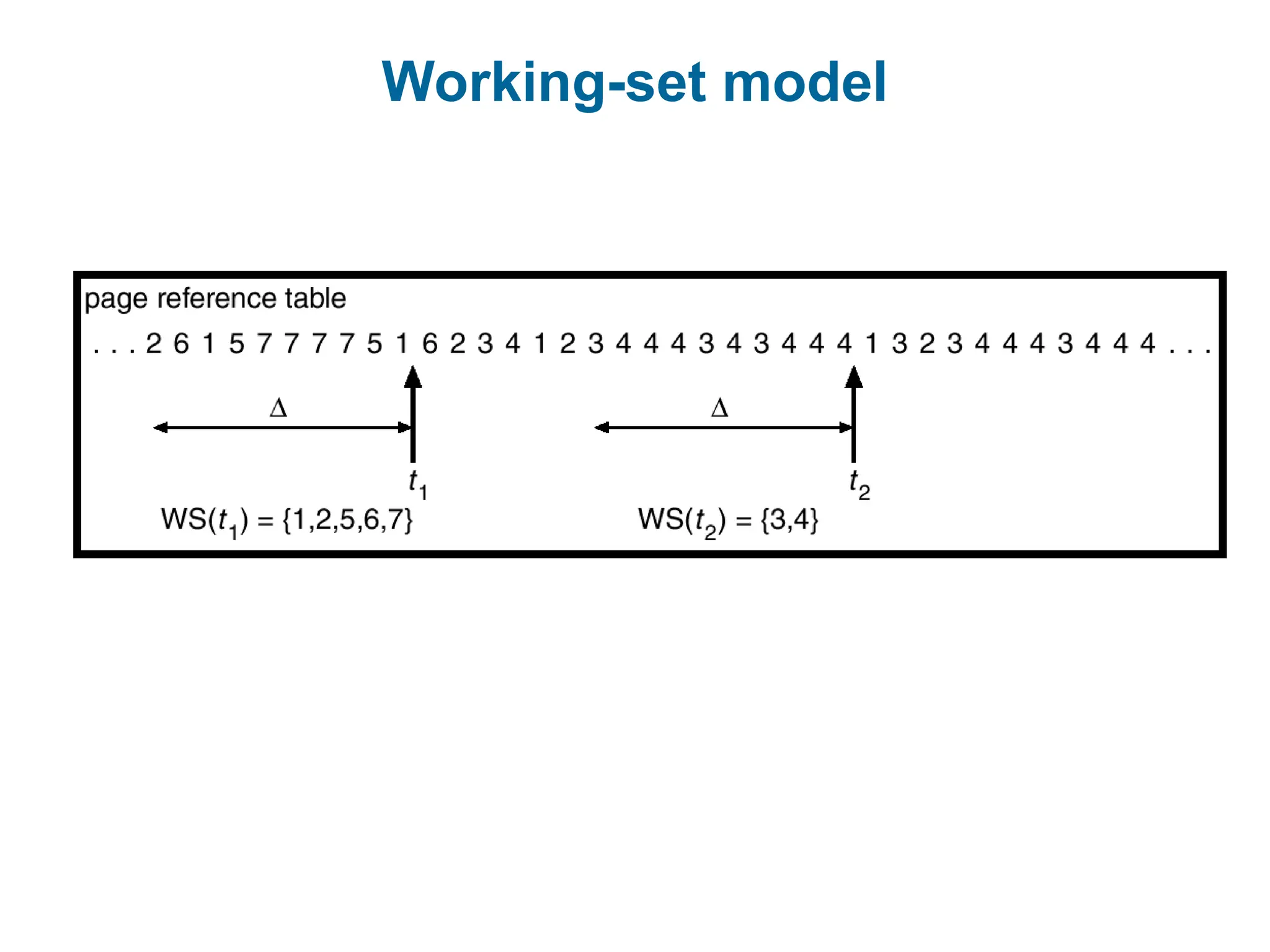
Working-Set Model
working-set window a fixed number of page references
Example: 10,000 instruction
The idea is to examine the most recent page references.
WSSi (working set of Process Pi) =
total number of pages referenced in the most recent (varies in
time)
if too small will not encompass entire locality.
if too large will encompass several localities.
if = will encompass entire program.
D = WSSi total demand frames
if D > m Thrashing
Policy if D > m, then suspend one of the processes.
Keeping Track ofthe Working Set
Approximate with interval timer + a reference bit
Example: = 10,000
Timer interrupts after every 5000 time units.
Keep in memory 2 bits for each page.
Whenever a timer interrupts copy and sets the values of all reference
bits to 0.
If one of the bits in memory = 1 page in working set.
Why is this not completely accurate?
Improvement = 10 bits and interrupt every 1000 time units. Costly.
88.
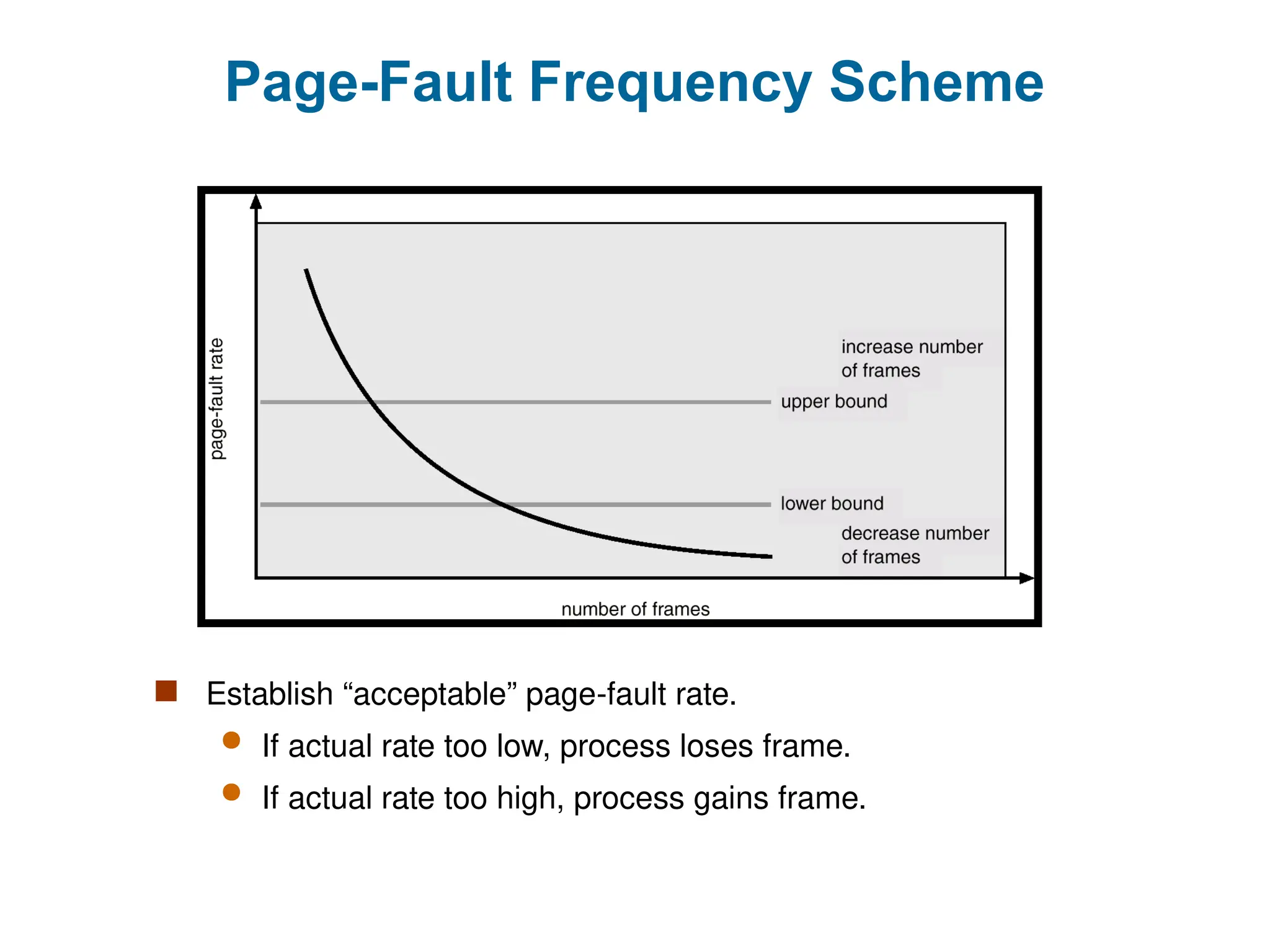
Page-Fault Frequency Scheme
Establish “acceptable” page-fault rate.
If actual rate too low, process loses frame.
If actual rate too high, process gains frame.
89.
Other Considerations
Prepaging– bring into memory at one time all the pages that will
be needed.
An attempt to prevent high level of initial paging.
When the process is to be resumed, we automatically bring
back into memory its entire working set before restarting the
process.
The question is whether the cost of using prepaging is less
than page faults.
Assume that s pages are prepared and a fraction f of theses
pages is actually used. If f is 1, prepaging wins.
Page size selection
table size – a larger page needs fewer tables.
Fragmentation – a smaller page causes less fragmentation.
I/O overhead – a larger page causes less overhead.
Locality – a smaller page has better locality.
Modern systems tend to use larger page size.
90.
Other Considerations (Cont.)
TLB Reach - The amount of memory accessible from the TLB (Translation
Look-Aside Buffer).
TLB Reach = (TLB Size) X (Page Size)
Ideally, the working set of each process is stored in the TLB. Otherwise
there is a high degree of page faults.
91.
Increasing the Sizeof the TLB
Increase the Page Size. This may lead to an increase in fragmentation as
not all applications require a large page size.
Provide Multiple Page Sizes. This allows applications that require larger
page sizes the opportunity to use them without an increase in fragmentation.
For example, Solaris2 8 KB, 64 KB, 512 KB, and 4 MB.
Recent trends indicate a move towards software-managed TLBs and
operating-system support for multiple page sizes.
The UltraSparc, MIPS, Alpha architectures employ software-managed TLBs.
The PowerPC and Pentium manage the TLB in hardware.
92.
Other Considerations (Cont.)
Inverted Page Table
We save memory by creating a table that has one entry per physical
memory page.
However, the inverted page table no longer contains complete
information about the logical address space.
An external page tables must be kept.
It requires careful handling in the kernel and a delay in the page-lookup
processing.
93.
Other Considerations (Cont.)
Program structure
int A[][] = new int[1024][1024];
Each row is stored in one page
Program 1 for (j = 0; j < A.length; j++)
for (i = 0; i < A.length; i++)
A[i,j] = 0;
1024 x 1024 page faults
Program 2 for (i = 0; i < A.length; i++)
for (j = 0; j < A.length; j++)
A[i,j] = 0;
1024 page faults
94.
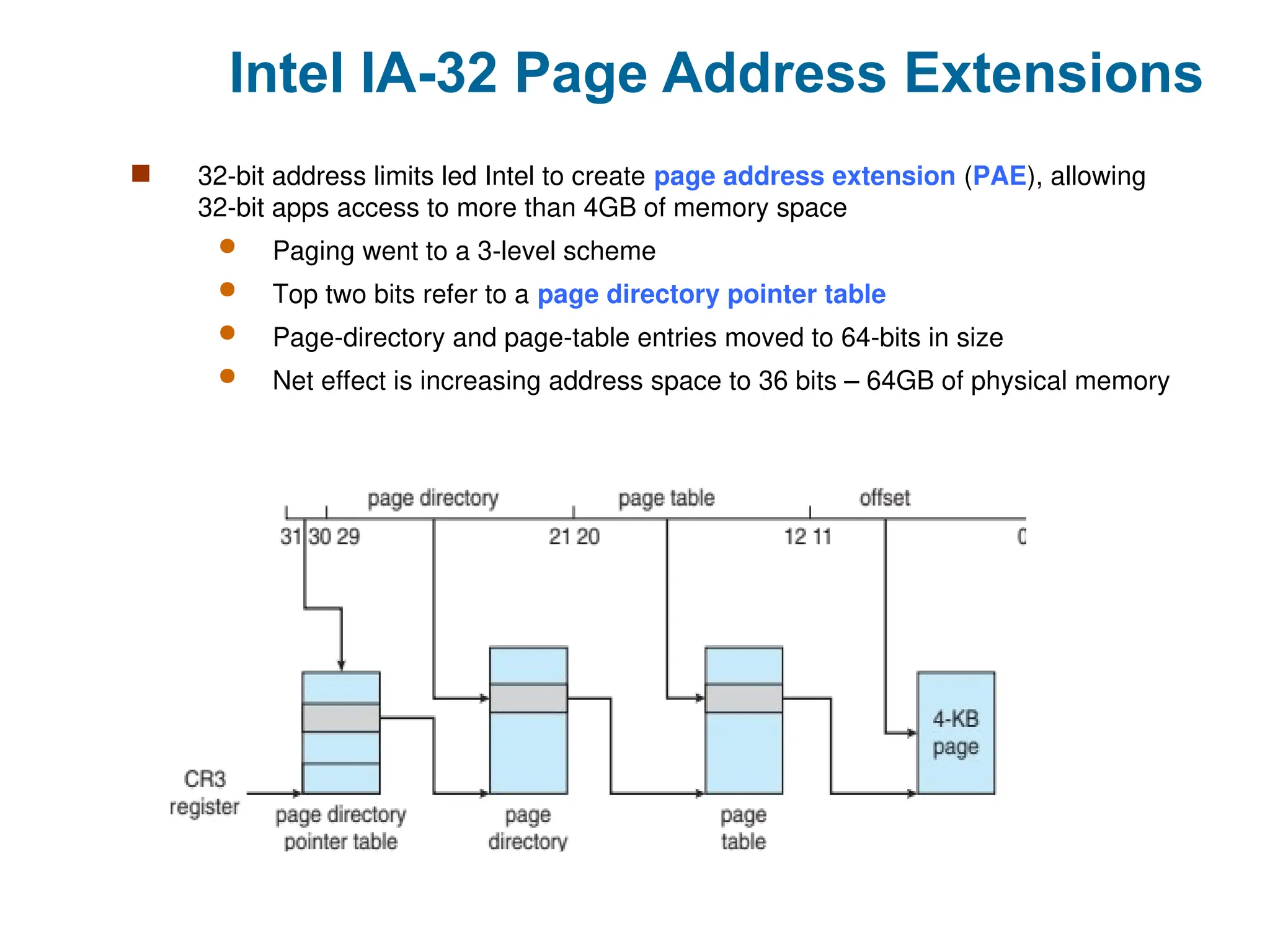
Intel IA-32 PageAddress Extensions
32-bit address limits led Intel to create page address extension (PAE), allowing
32-bit apps access to more than 4GB of memory space
Paging went to a 3-level scheme
Top two bits refer to a page directory pointer table
Page-directory and page-table entries moved to 64-bits in size
Net effect is increasing address space to 36 bits – 64GB of physical memory
95.
Intel x86-64
Currentgeneration Intel x86 architecture
64 bits is ginormous (> 16 exabytes)
In practice only implement 48 bit addressing
Page sizes of 4 KB, 2 MB, 1 GB
Four levels of paging hierarchy
Can also use PAE so virtual addresses are 48 bits and physical
addresses are 52 bits
96.
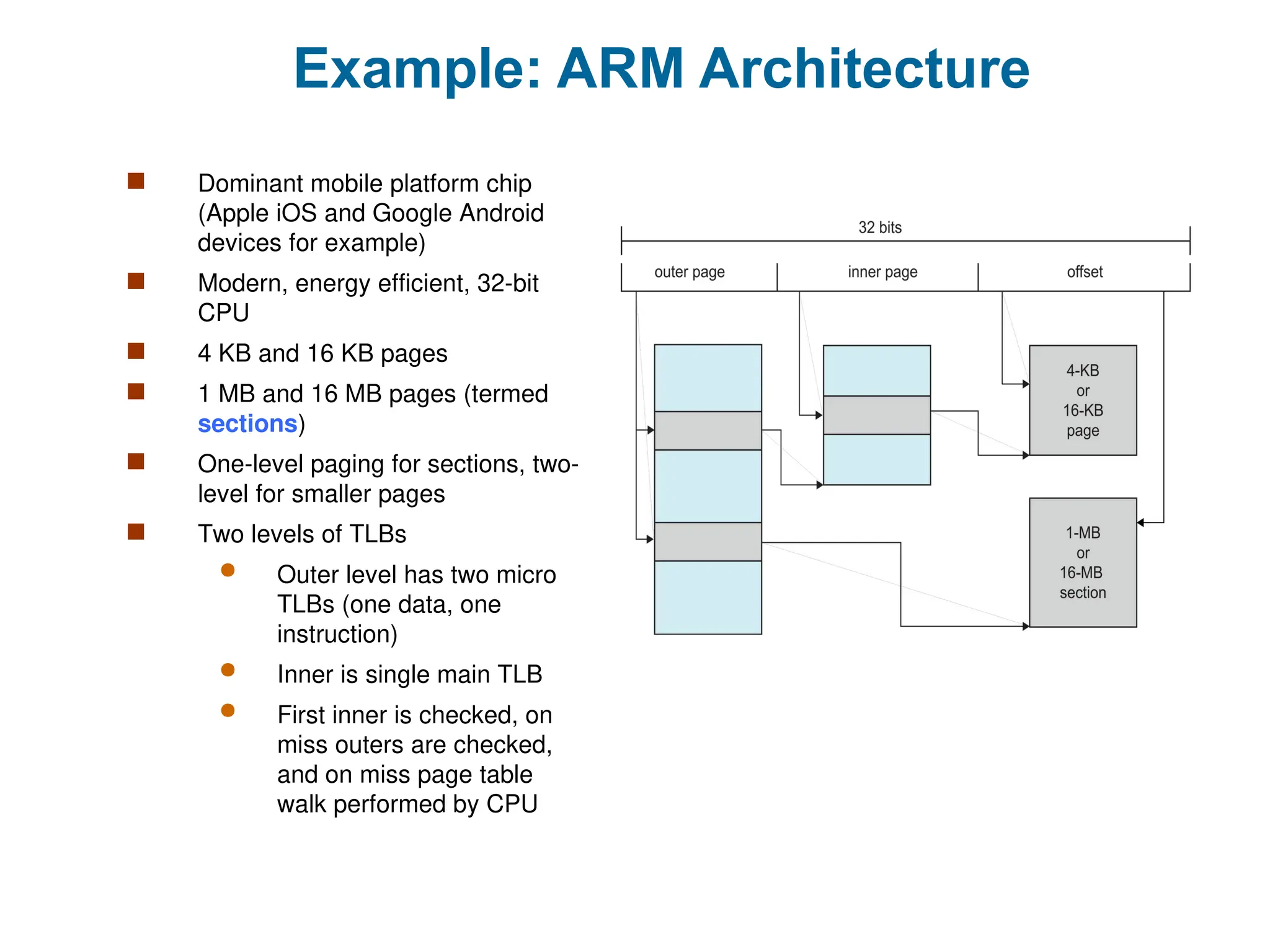
Example: ARM Architecture
Dominant mobile platform chip
(Apple iOS and Google Android
devices for example)
Modern, energy efficient, 32-bit
CPU
4 KB and 16 KB pages
1 MB and 16 MB pages (termed
sections)
One-level paging for sections, two-
level for smaller pages
Two levels of TLBs
Outer level has two micro
TLBs (one data, one
instruction)
Inner is single main TLB
First inner is checked, on
miss outers are checked,
and on miss page table
walk performed by CPU
























































![Other Considerations (Cont.)
Program structure
int A[][] = new int[1024][1024];
Each row is stored in one page
Program 1 for (j = 0; j < A.length; j++)
for (i = 0; i < A.length; i++)
A[i,j] = 0;
1024 x 1024 page faults
Program 2 for (i = 0; i < A.length; i++)
for (j = 0; j < A.length; j++)
A[i,j] = 0;
1024 page faults](https://image.slidesharecdn.com/unit-4class2-250702060656-4e77db67/75/unit-4-class-2-ppt-Memory-managements-part-1-93-2048.jpg)