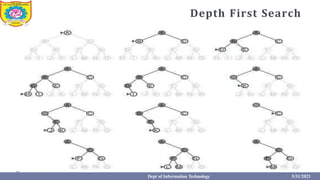
The document discusses various uninformed search strategies used in artificial intelligence. It describes strategies like breadth-first search, depth-first search, uniform cost search, depth-limited search, iterative deepening depth-first search, and bidirectional search. It explains the algorithms, properties, complexity analysis, and examples of each strategy. It also compares the different uninformed search strategies and discusses searching with partial information in sensorless, contingency, and exploration problems.












![Let us check if the UCS algorithm satisfies the 4 properties :
⦁ Uniform-cost search doesn’t care about the number of steps a path has, but only the total path
cost. It will get stuck in an infinite loop if there’s a path with infinite sequence of zero-cost
actions.Completeness is guaranteed only if the cost of every step is some positive number.
⦁ Uniform-cost search is optimal. This is because, at every step the path with the least cost is
chosen, and paths never gets shorter as nodes are added, ensuring that the search expands nodes in
the order of their optimal path cost.
⦁ To measure the time complexity, we need the help of path cost instead of the depth d. If C* is the
optimal path cost of the solution, and each step costs at least e, then the time complexity is:
O(b^[1+(C*/ e)]), which can be much greater than that of BFS. When all the step costs are the
same,then the optimal-cost search is same as BFS except that we go one more step deeper
.
⦁ In the first step, all the successors of the root node are stored. Then, the least-cost node is
removed, and its successors are added. Since we need the least cost of all the nodes explored, we
need to store all the nodes explored until the goal node is found. Hence, the space
complexity is also O(b^[1+(C*/e)]).
Dept of Information Technology 5/31/2023](https://image.slidesharecdn.com/unit2uninformedsearchstrategies-230531172321-e51eb98a/85/Unit-2-Uninformed-Search-Strategies-pptx-12-320.jpg)












![Sensorless problems
⦁ The agent can reach state 8 with the action sequence [Left, Absorb, Right, Absorb]
without knowing the initial state.
⦁ “When the world is not fully observable, the agent must reason about sets of
states (belief state),rather than a single state.”
⦁ Searching in the space of beliefstates;
1. An action is applied to abelief state by unioning the results of applying the action to
each physical state in the belief state.
2. A path now connects belief states.
3. A solution now is a path leading to a belief state,all of whose members are goal states.
In general,there are 2s belief states given S physical states.
The analysis is essentially the same if the environment is not deterministic. We just need
to add the various outcomes of the action to the successor belief state.
Dept of Information Technology 5/31/2023](https://image.slidesharecdn.com/unit2uninformedsearchstrategies-230531172321-e51eb98a/85/Unit-2-Uninformed-Search-Strategies-pptx-26-320.jpg)


![Exploration problems
⦁ This can be considered an extreme case of contingency problems; when the
states and actions of the environment is unknown, the agent must act to discover
them.
o No sensor
o Initial State(1,2,3,4,5,6,7,8)
o After action [Right] the state (2,4,6,8)
o After action [Absorb] the state (4,8)
o After action [Left] the state (3,7)
o After action [Absorb] the state (8)
o Answer :[Right,Absorb, Left,Absorb] coerce the world into state 7 without any sensor
o Belief State:Such state that agent belief to be there
Dept of Information Technology 5/31/2023](https://image.slidesharecdn.com/unit2uninformedsearchstrategies-230531172321-e51eb98a/85/Unit-2-Uninformed-Search-Strategies-pptx-29-320.jpg)
![Sensorless multi-state problem
30
⦁ Contingency, start in {1,3}.
⦁ Murphy’
s law, Absorb can dirty a clean
carpet.
⦁ Local sensing:dirt,location only.
– Percept = [L,Dirty] ={1,3}
– [Absorb] = {5,7}
– [Right] ={6,8}
– [Absorb] in {6}={8} (Success)
– BUT [Absorb] in {8} = failure
⦁ Solution??
– Belief-state:no fixed action sequence
guarantees solution
⦁ Relax requirement:
– [Absorb,Right,if[R,dirty] thenAbsorb]
– Select actions based on contingencies
arising during execution.
Sanjivani College of Engineering, Kopargaon Dept of Information Technology 5/31/2023](https://image.slidesharecdn.com/unit2uninformedsearchstrategies-230531172321-e51eb98a/85/Unit-2-Uninformed-Search-Strategies-pptx-30-320.jpg)





















































































