Downloaded 16 times
















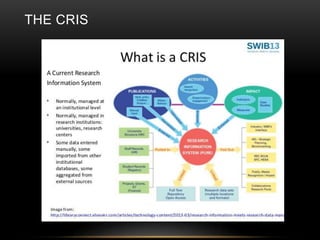





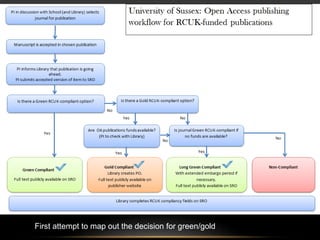
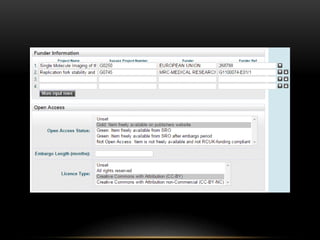
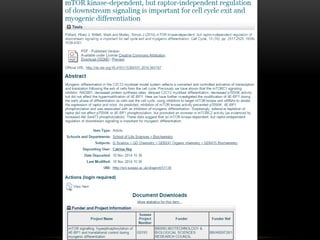






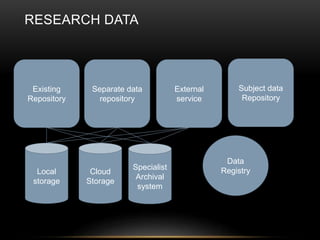



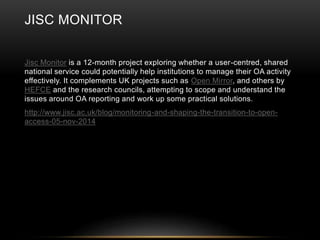
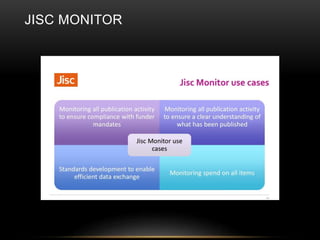
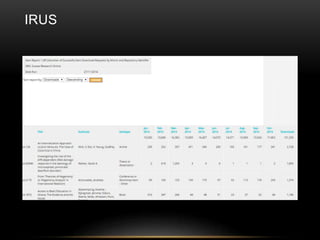
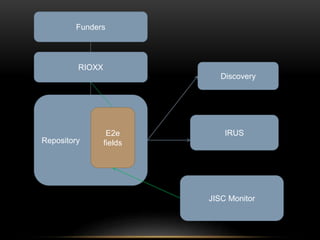



This document discusses the evolving role of institutional repositories (IRs) in light of increasing open access mandates from research funders. It provides a brief history of IRs and outlines challenges they currently face in supporting new compliance requirements. Specifically, IRs were not designed to track publications, link them to funded projects, or manage related metadata and processes. While some institutions have separate systems like a CRIS that can fulfill more of these functions, many rely solely on their IR. The document explores potential solutions on the horizon, like the JISC Monitor project and IRUS usage statistics service, that could help institutions manage open access activities and reporting. Overall, mandates are pushing IRs in new directions beyond their original open access goals























































































