Download to read offline








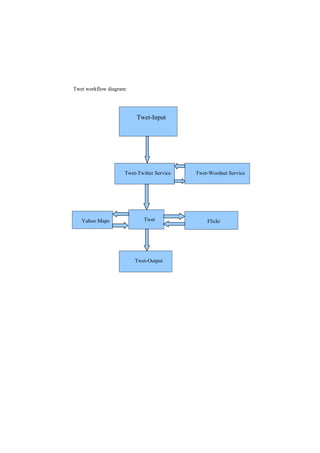
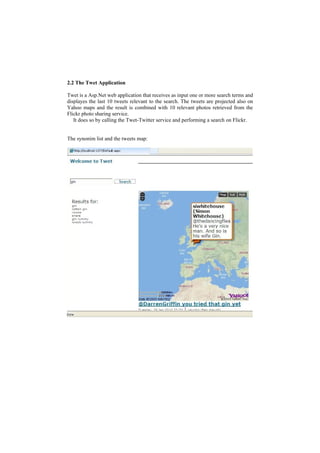
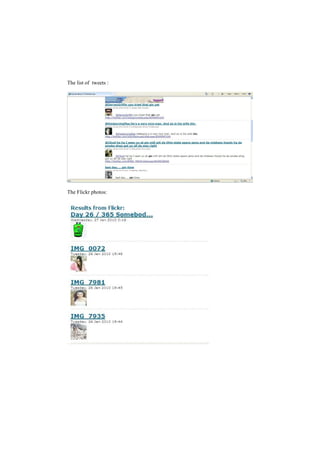






Twet is a search tool that combines results from Twitter and Flickr. It searches for tweets and photos related to a search term. It uses WordNet to include synonyms in the search. Search results include tweets displayed on a Yahoo Maps overlay and relevant Flickr photos. The Twet application and Twet-Twitter and Twet-WordNet services work together to provide this mashup of social media search results.




























































