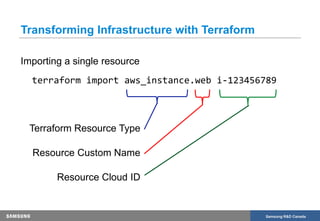
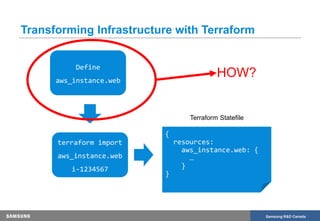
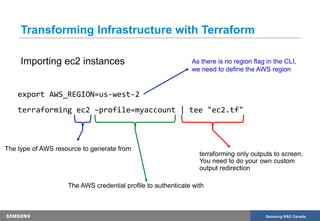
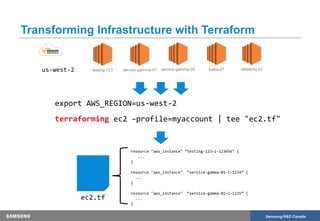
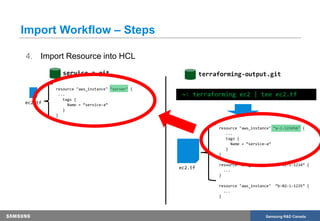
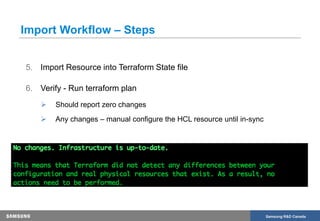
The document discusses the transformation of production infrastructure into code using HashiCorp's Terraform, focusing on the process of importing existing cloud resources and the associated lessons learned. It highlights the benefits of using Infrastructure as Code (IAC) for improved visibility, consistency, collaboration, and reusability of cloud infrastructure configurations. The presentation also outlines practical steps for successfully transitioning to Terraform, including effective communication and documentation strategies.











































































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)