Download to read offline






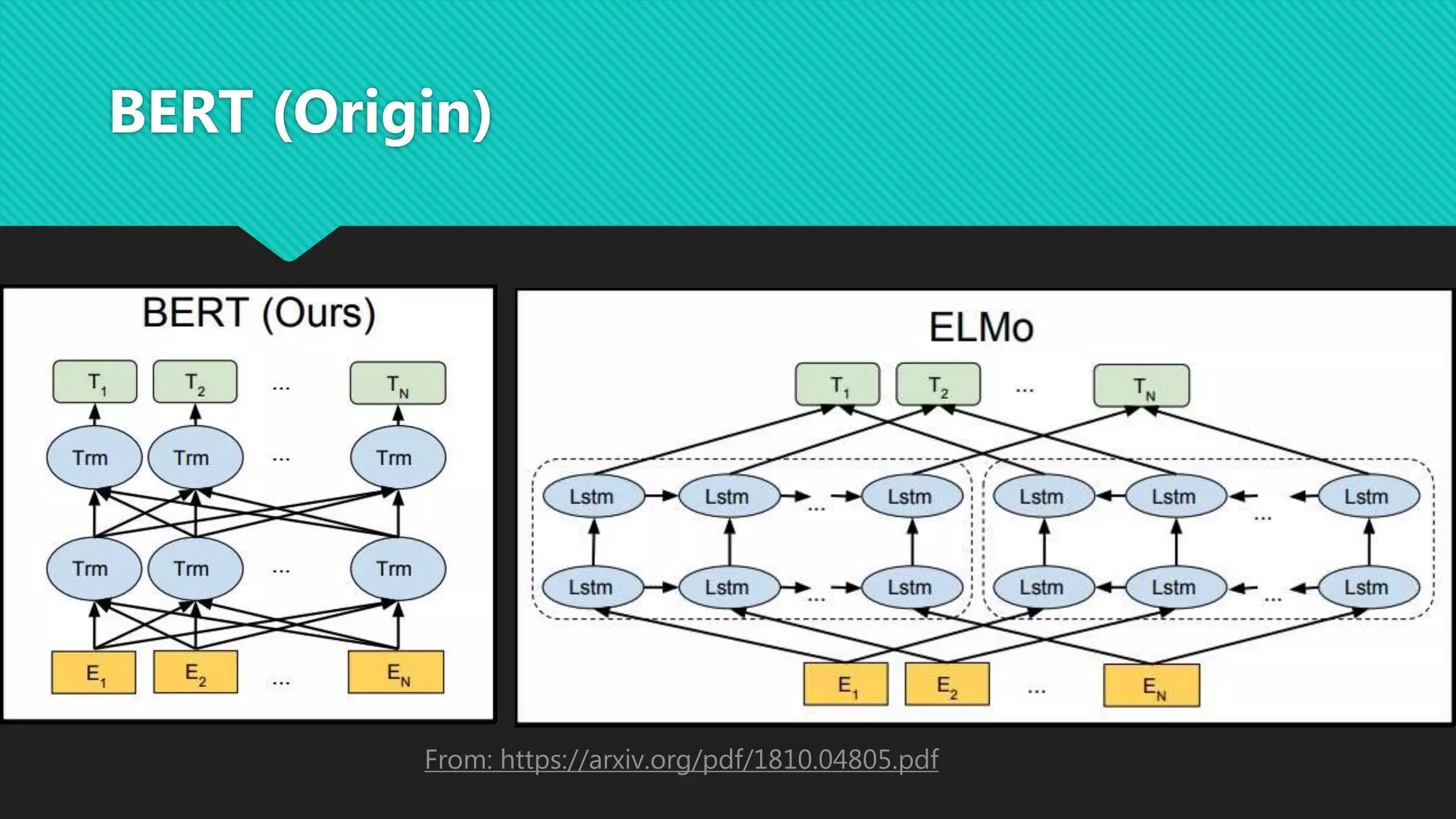

![BERT (training tasks)
Masked Language Model: masked word with the [MASK] token
Next Sentence Prediction](https://image.slidesharecdn.com/ibtd1zwnqggum1eu86h0-signature-75525836ffdd7653e07cc98c4424e2a1474784c088484fc6c26d5e97181bd851-poli-200806110847/75/Transformer-and-BERT-16-2048.jpg)

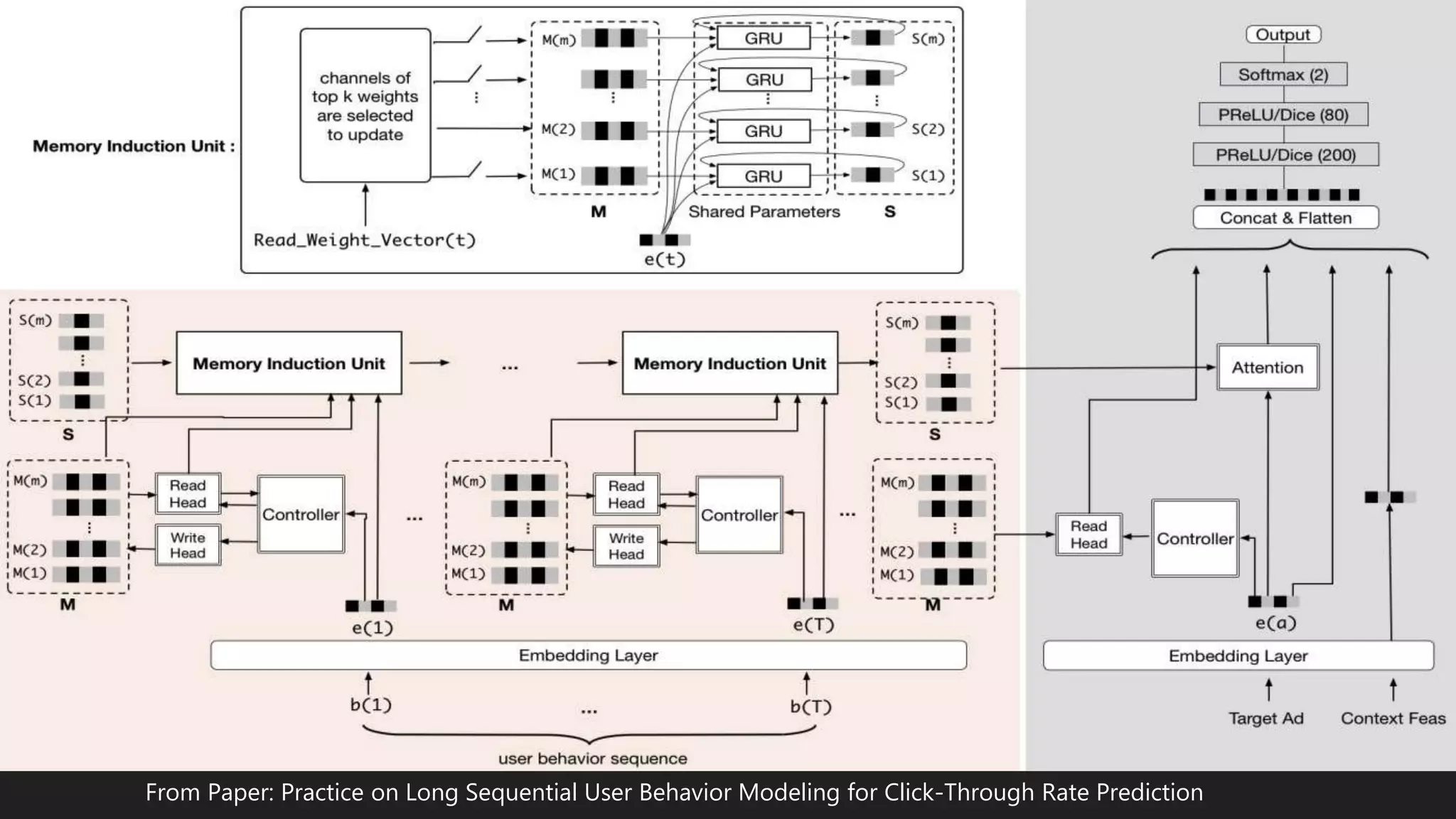


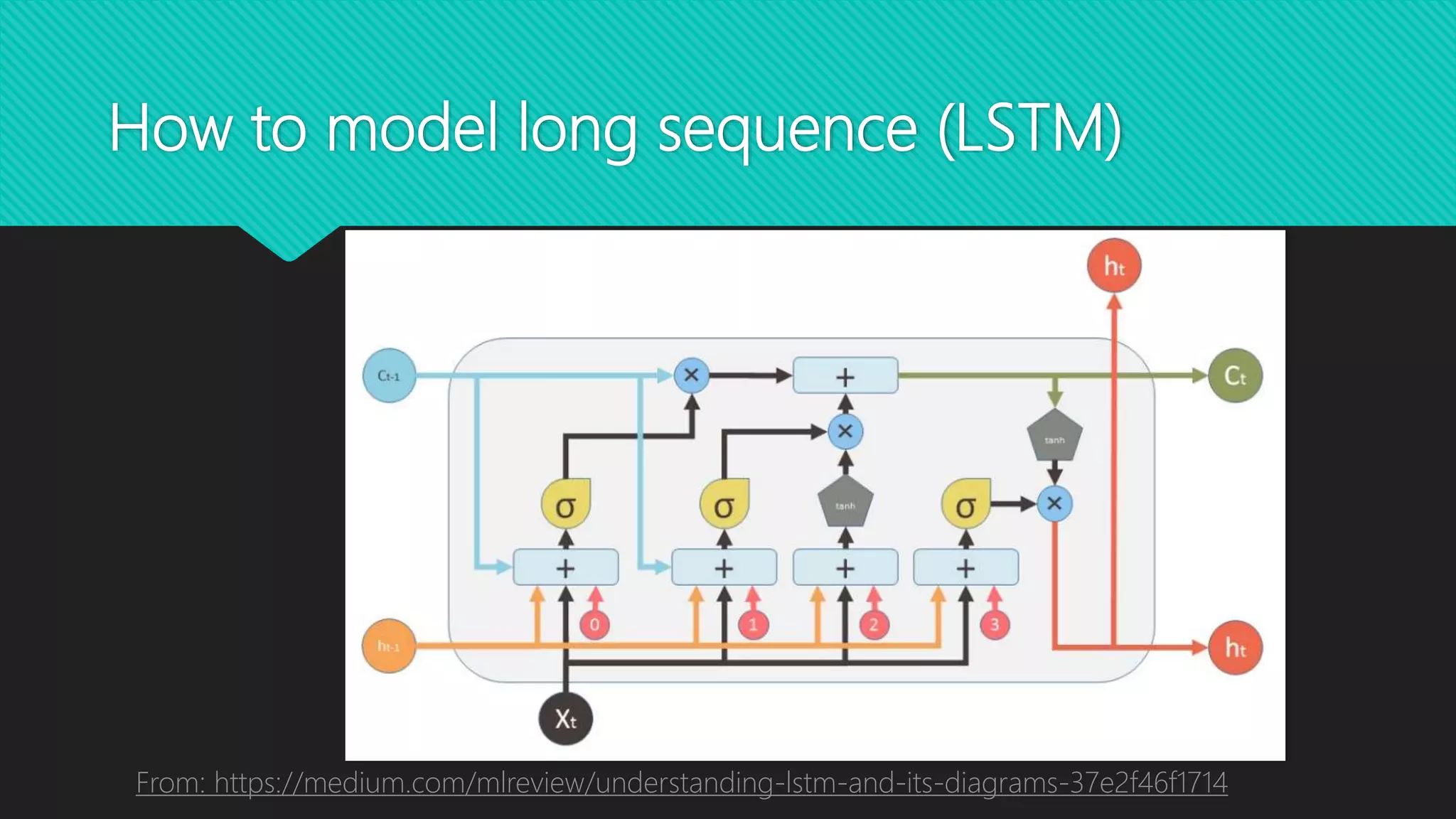
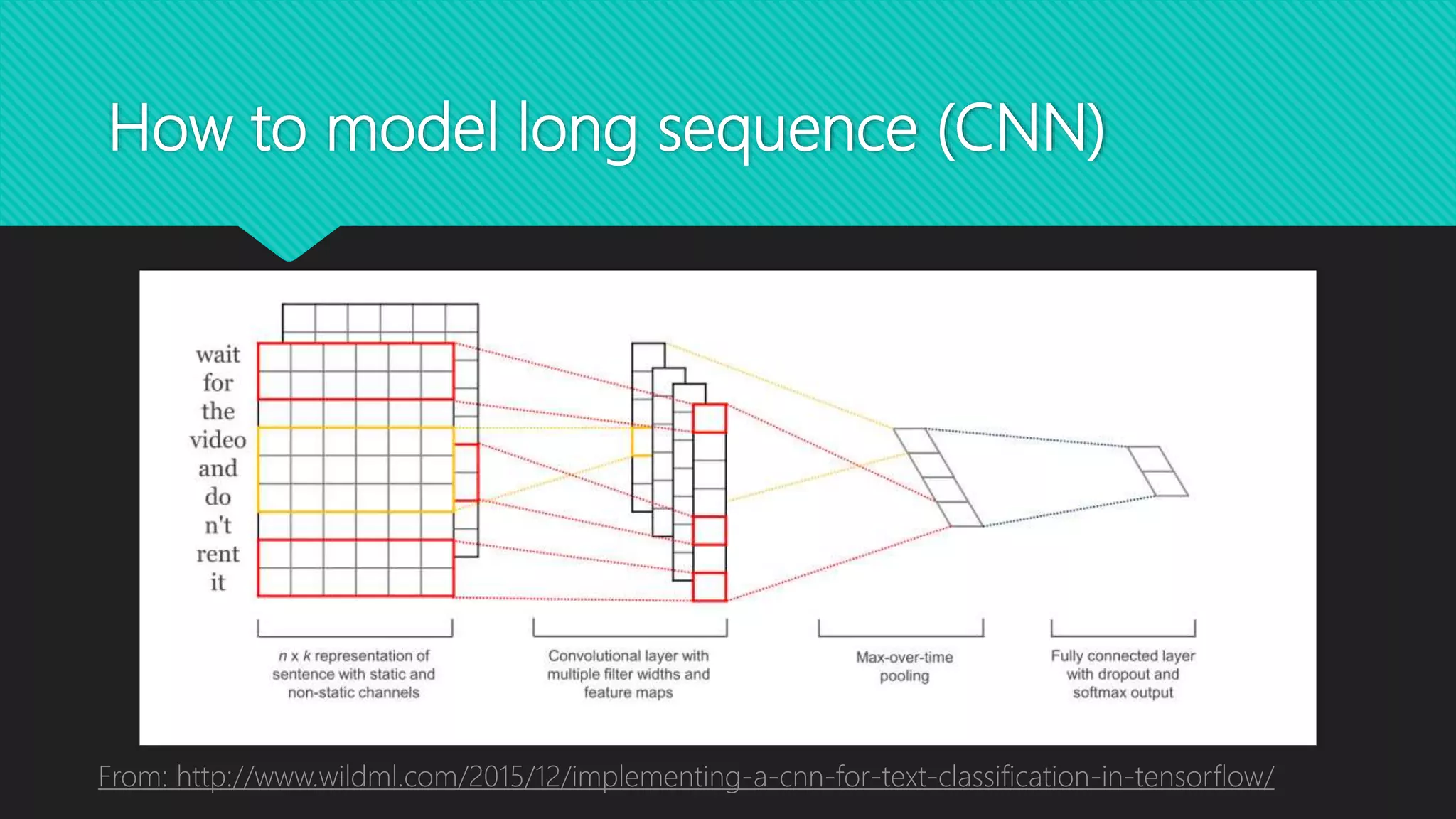
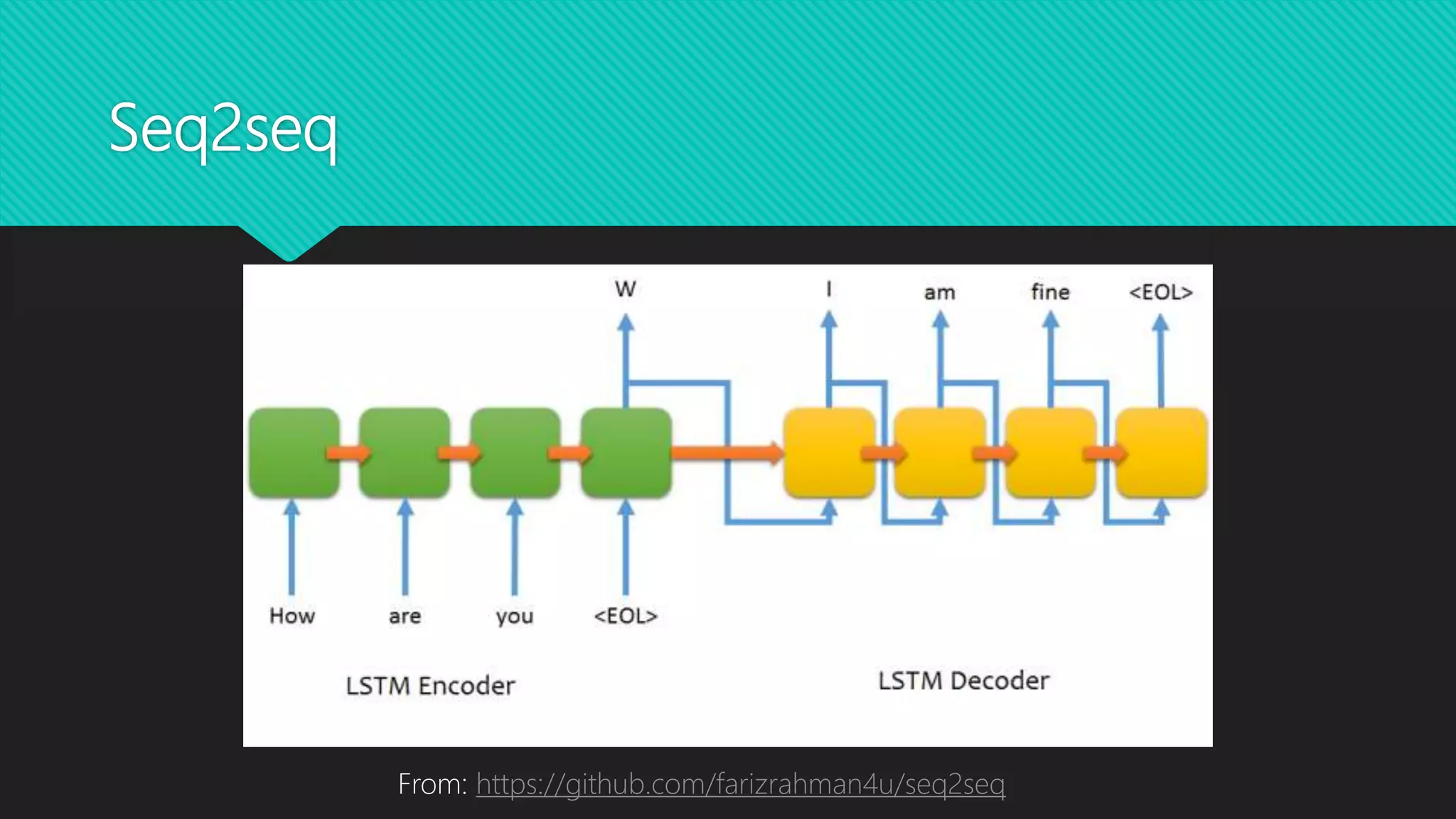
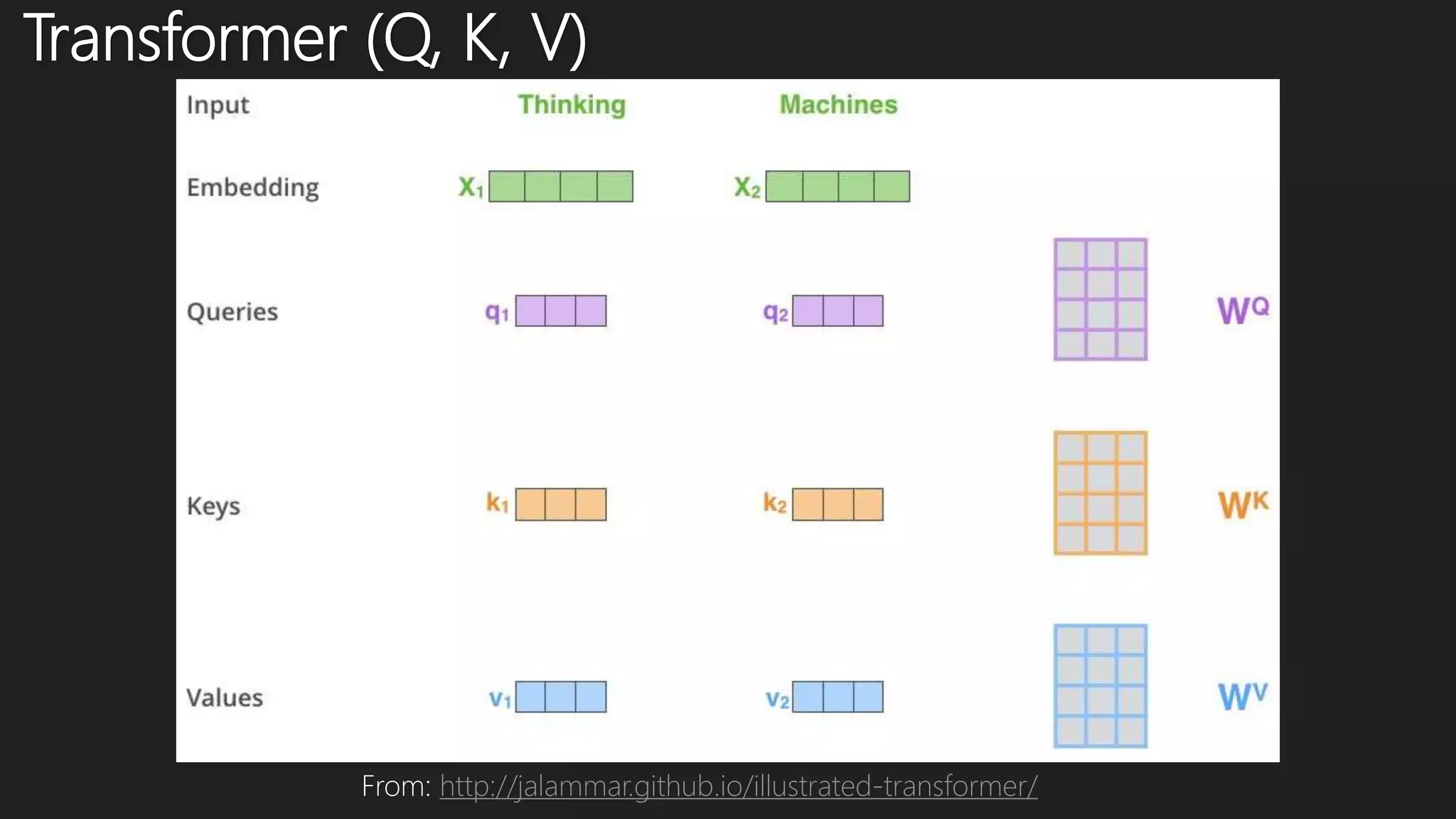
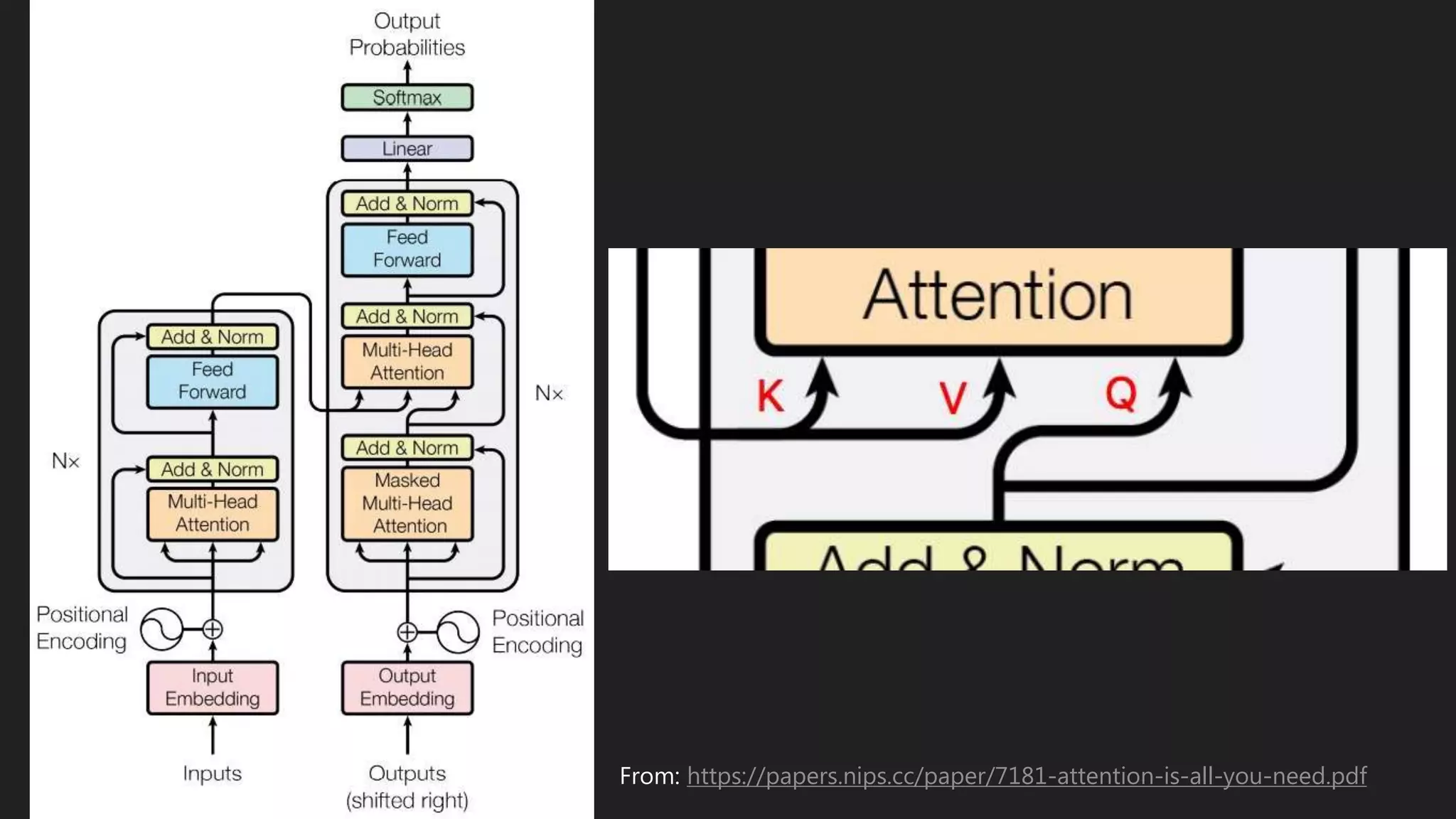
This document discusses various methods for modeling long sequences, including LSTMs, CNNs, attention mechanisms, and Transformers. It provides details on the Transformer architecture such as multi-head attention, feed-forward layers, and computational complexity. BERT is introduced as a Transformer-based model used for natural language understanding tasks. Details are given on BERT's training methodology and the resources required to train BERT-base.


![[Question Paper] Microprocessor and Microcontrollers (Revised Course) [April ...](https://cdn.slidesharecdn.com/ss_thumbnails/mm-qprevisedcourseapr-2015-170713044202-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Question Paper] Microprocessor and Microcontrollers (Revised Course) [Septem...](https://cdn.slidesharecdn.com/ss_thumbnails/mm-qprevisedcoursesep-2013-170713044201-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Question Paper] Microprocessor and Microcontrollers (Revised Course) [June /...](https://cdn.slidesharecdn.com/ss_thumbnails/mm-qprevisedcoursejun-2014-170713050810-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Question Paper] Embedded System (Revised Course) [April / 2015]](https://cdn.slidesharecdn.com/ss_thumbnails/es-qp-revised-course-april-2015-170802133639-thumbnail.jpg?width=640&height=640&fit=bounds)








![B.Sc.IT: Semester - VI (October - 2013) [IDOL - Revised Course | Question Paper]](https://cdn.slidesharecdn.com/ss_thumbnails/bscit-sem-vi-oct-idol-2013-qp-180803214355-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)





































