Download to read offline










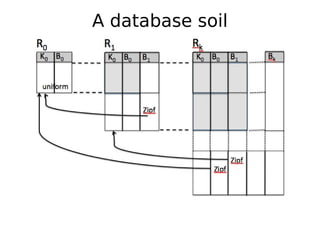







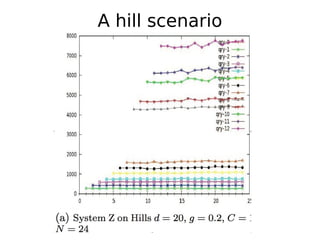
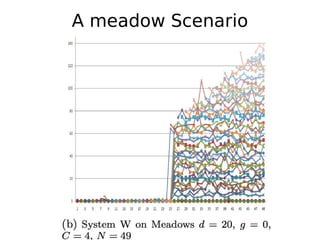
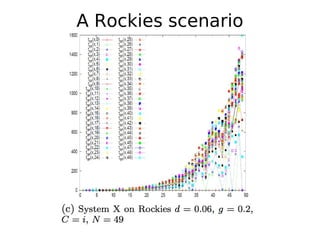







The document discusses 'tractor pulling' as a methodology for evaluating database management systems (DBMS) using various performance metrics and workload scenarios. It outlines different scenarios such as hill, meadow, and rockies to assess the robustness of databases during various operations, focusing on query processing and system performance under load. The need for better analysis tools and comparisons to measure differences in system behavior is emphasized, alongside the conclusion that tractor pulling is a valuable tool for testing DBMS robustness.