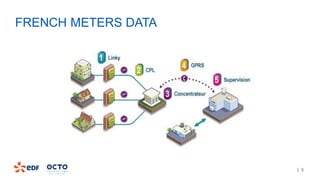
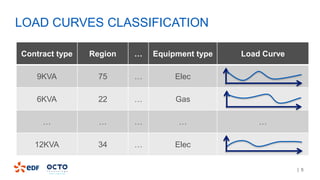
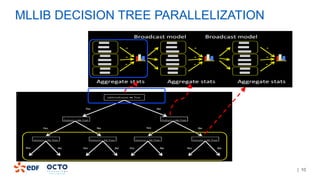
1. The document discusses Courbospark, a decision tree algorithm for time-series classification on Spark.
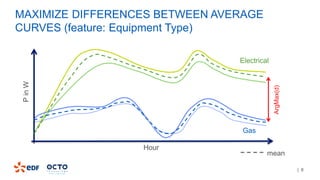
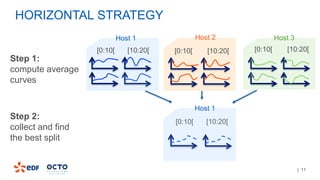
2. It was implemented by modifying MLLib to handle time-series data and splitting on nominal features using hierarchical clustering.
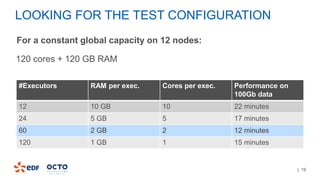
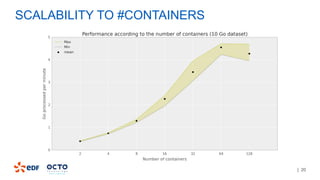
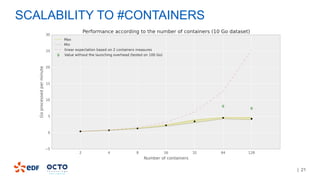
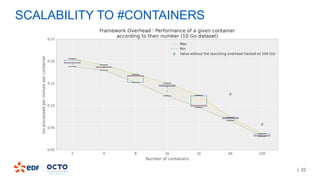
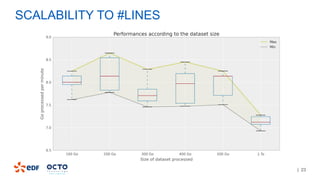
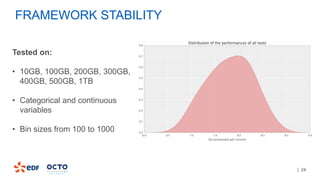
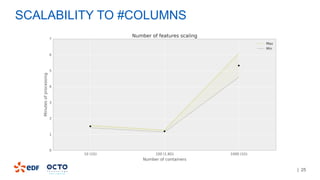
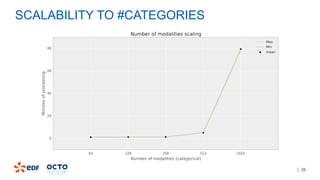
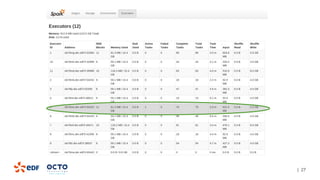
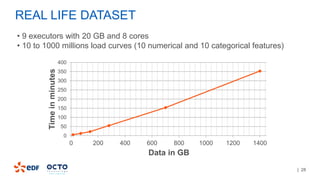
3. Performance tests showed good scalability to data size, number of executors, and number of columns/categories when run on a cluster.