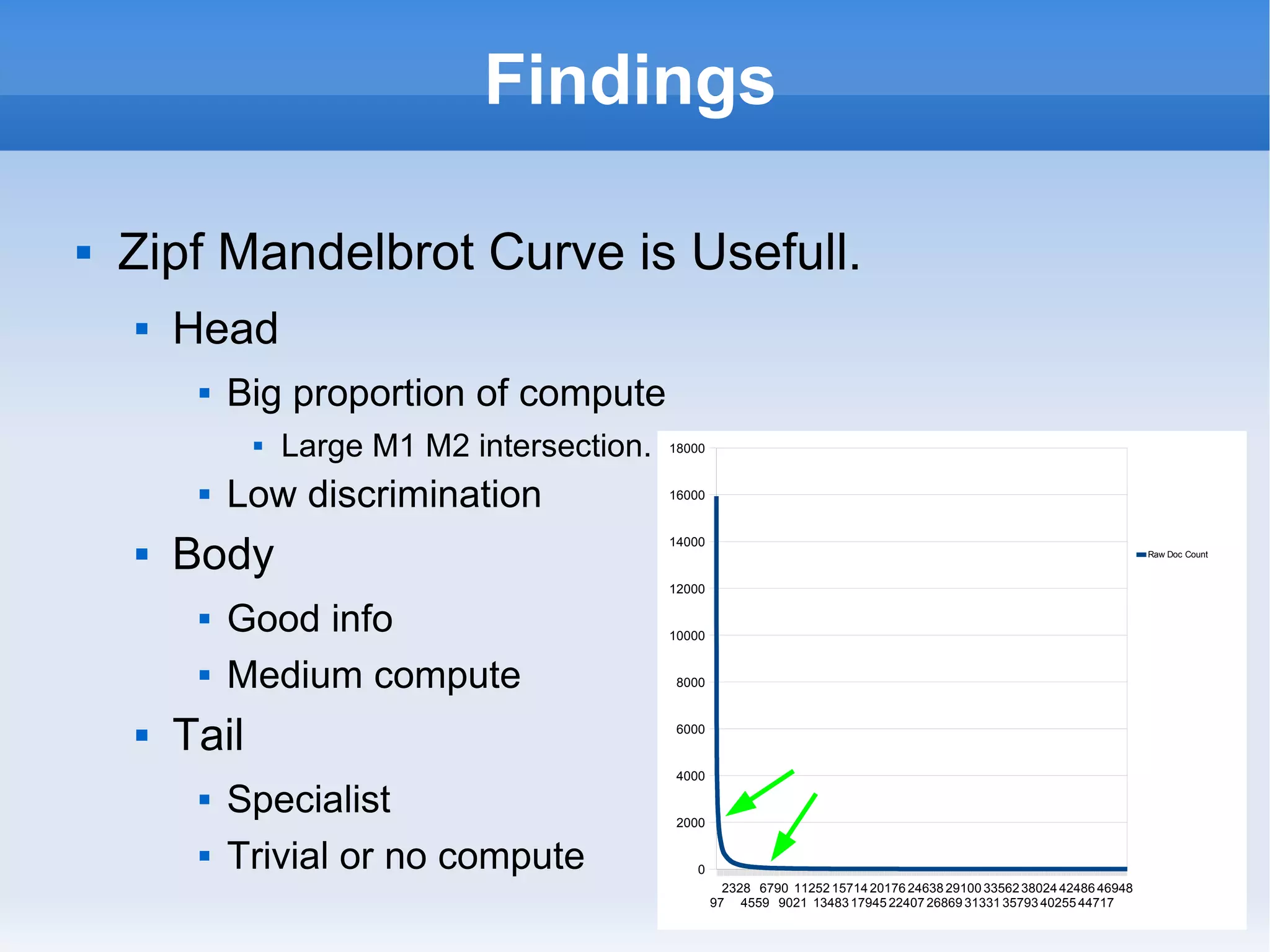
The document proposes a hybrid approach to scalably computing pairwise comparisons of large datasets that follows a Zipf-Mandelbrot distribution. It involves pre-computing and storing the most frequent "head" comparisons while computing less frequent "body" and trivial "tail" comparisons on-demand. This balances storage and computation needs while allowing dimensionality reduction as the dataset scales. Preliminary experiments tested the approach on loan data using HBase and HDFS. Further performance testing and integration with Hadoop is suggested to prove the approach.




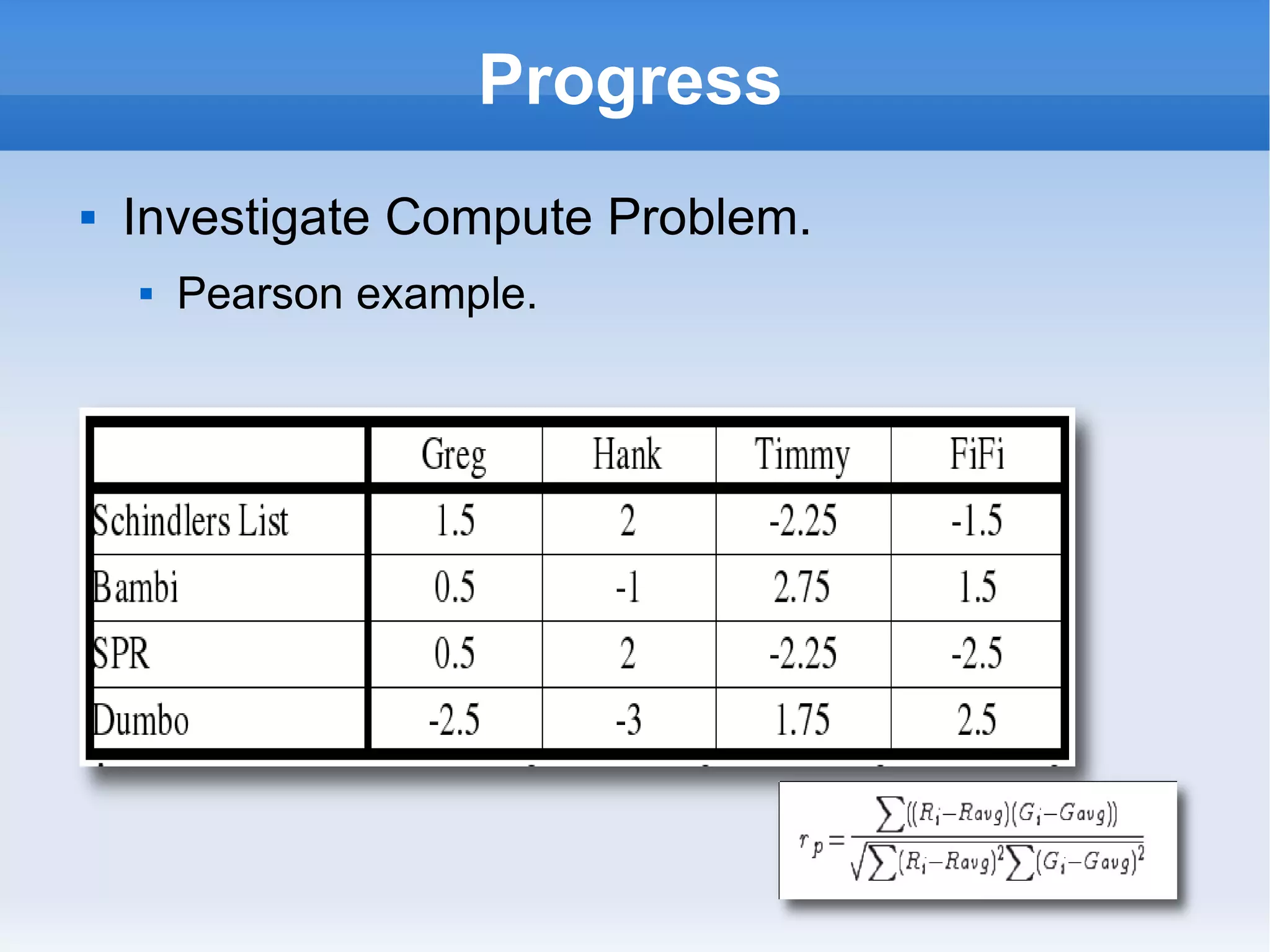

![Progress Investigate Scale N films M people M[(N(N-1)/2] time the algorithm cost Pearson: Numerator 2 – , 1 *, 1+ Denominator 2 -, 2 ^2, 2 + M(N) time to compute averages Can be done on ingest in M(N) time](https://image.slidesharecdn.com/sprint5demo-1227195410168419-8/75/End-of-Sprint-5-7-2048.jpg)


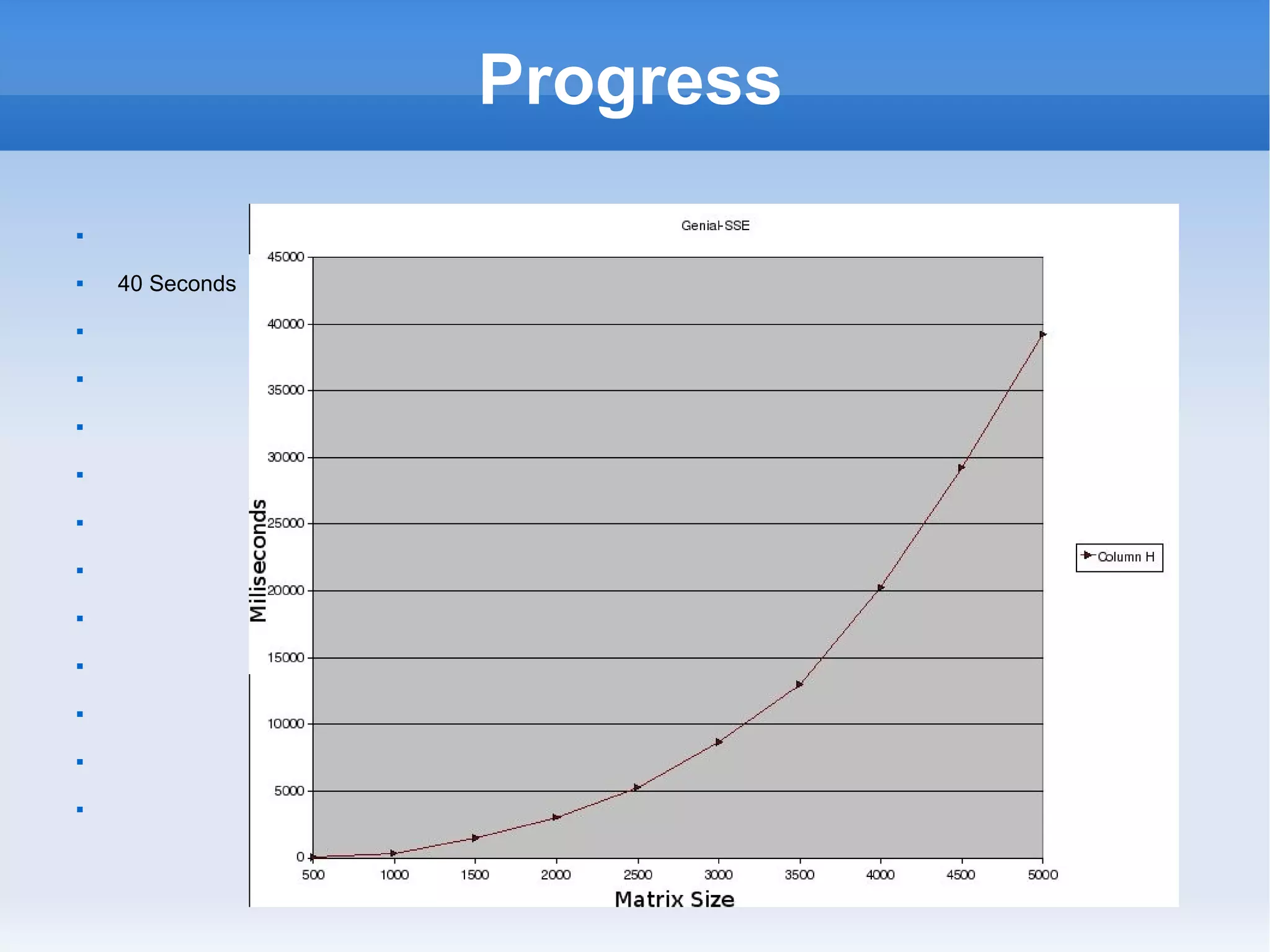
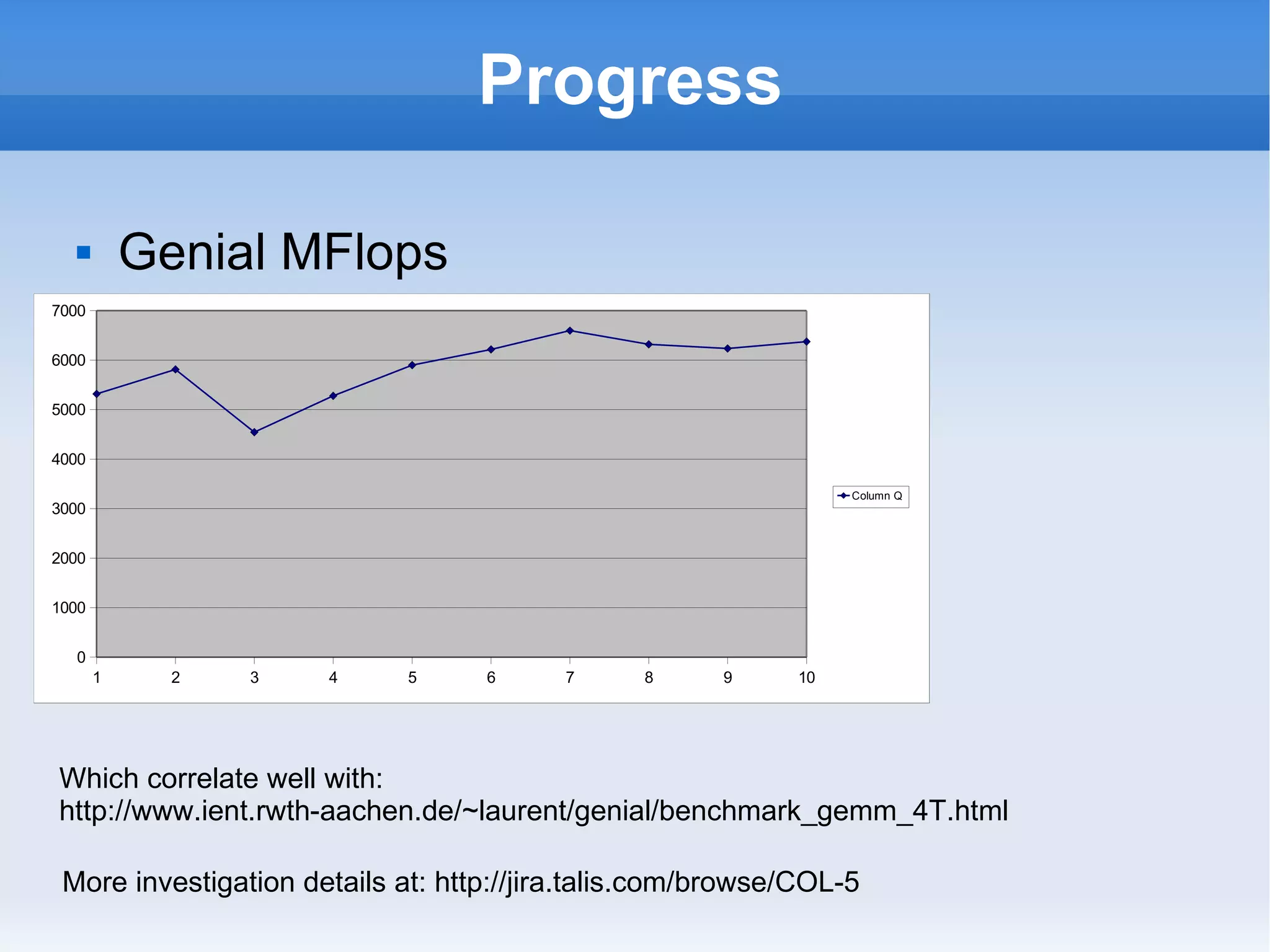











![Progress Very Sparse Turns out to be Zipf – Mandelbrot distribution. [1] G. K. Zipf, Human Behavior and the Principle of Least Effort. (Cam- bridge, Mass., 1949; Addison-; Wesley, 1965). [2] B. Mandelbrot, “An informational theory of the statistical structure of language”, in Communication Theory, ed. Willis Jackson. (Better- worths, 1953). Word Count is .0025% dense Ignore Null for huge optimisation. 40,000 x less compute (using uniform density assumption) Zipf-Mandelbrot has the form: y = P1/(x+P2)^P3.](https://image.slidesharecdn.com/sprint5demo-1227195410168419-8/75/End-of-Sprint-5-23-2048.jpg)








![Progress Zipf Mandelbrot – Good Assumption? Most (all large complex systems?) data that we are likely to process will follow a Zipf-Mandlebrot model. K. Silagadze shows [1] that these comply... Clickstreams Page-rank (Linkage/Centrality) Citations Other long tail interactions. [1]Z. K. Silagadze [physics.soc-ph] 26 Jan 1999 Citations and the Zipf-Mandelbrot’s law - Budker Institute of Nuclear Physics, 630 090, Novosibirsk, Russia ing.](https://image.slidesharecdn.com/sprint5demo-1227195410168419-8/75/End-of-Sprint-5-32-2048.jpg)












![[Japanese]Obake-GAN (Perturbative GAN): GAN with Perturbation Layers](https://cdn.slidesharecdn.com/ss_thumbnails/masterthesisslideshare-190206090500-thumbnail.jpg?width=640&height=640&fit=bounds)

















































































