Download as PDF, PPTX




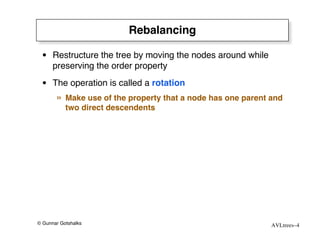
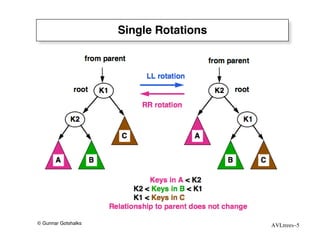


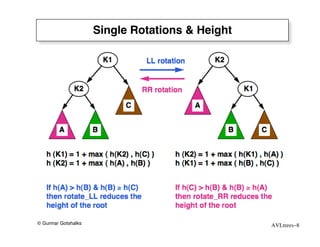

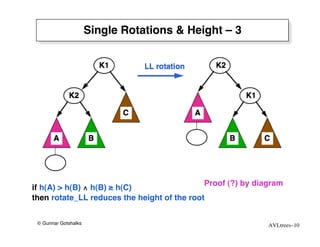
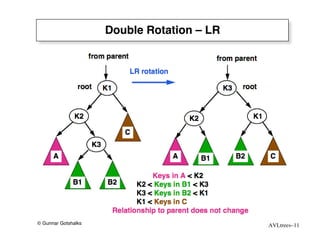
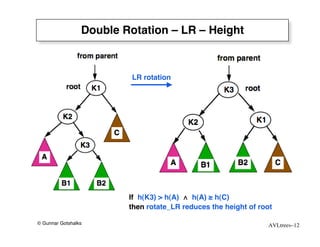
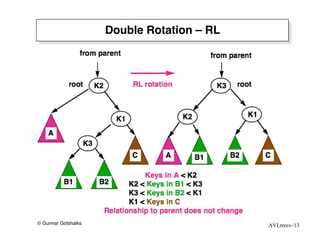
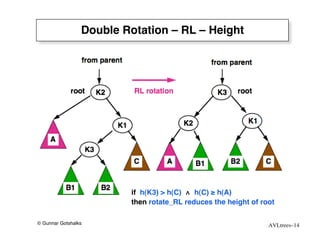




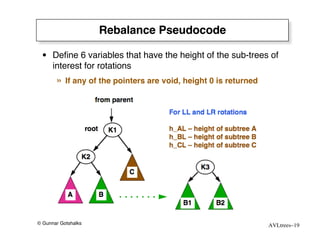
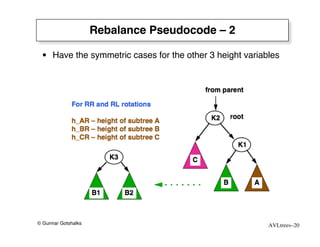









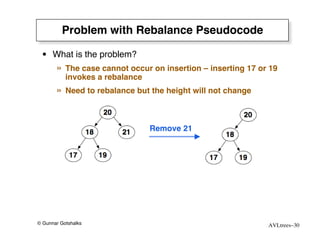
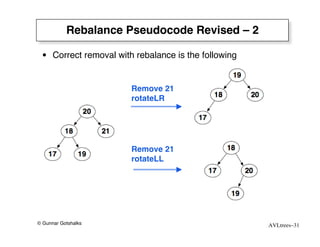



The document discusses AVL trees, which are self-balancing binary search trees. AVL trees ensure that insertions and deletions perform in O(log n) time by enforcing that the heights of any two subtrees of a node differ by at most one. They use rotations to rebalance the tree after insertions or deletions. Single and double rotations are used to move nodes and restore the balance property. Maintaining the balance factor during insertions, deletions, and rotations requires adjusting the heights of nodes as they are moved.





![[Vldb 2013] skyline operator on anti correlated distributions](https://cdn.slidesharecdn.com/ss_thumbnails/vldb2013skylineoperatoronanti-correlateddistributions-160331123240-thumbnail.jpg?width=640&height=640&fit=bounds)




























![4.10.AVLTrees[1].ppt](https://cdn.slidesharecdn.com/ss_thumbnails/4-230506160150-db7bb18c-thumbnail.jpg?width=640&height=640&fit=bounds)


































