Download to read offline





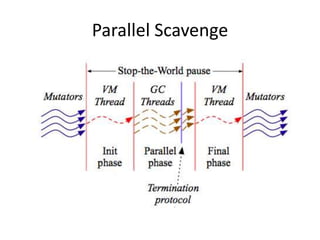
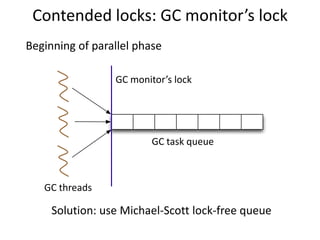
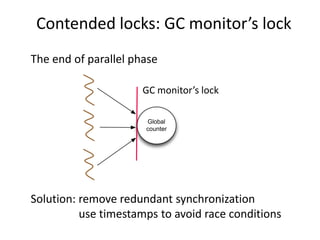

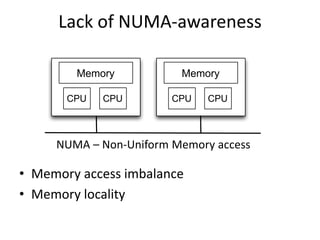





This study examined the scalability of stop-the-world garbage collectors on multicore systems. It identified bottlenecks in the Parallel Scavenge collector related to contended locks and lack of NUMA awareness. To address these, it implemented a NUMA-aware Parallel Scavenge (NAPS) collector using lock-free queues, removing redundant synchronization, and employing NUMA-aware memory allocation. Evaluation on SPEC benchmarks showed NAPS improved performance and scalability over Parallel Scavenge, reducing maximum pause times by up to 2.8x on a 48-core system.





























































