Download to read offline






![Experimental Results 20
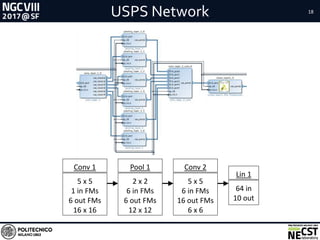
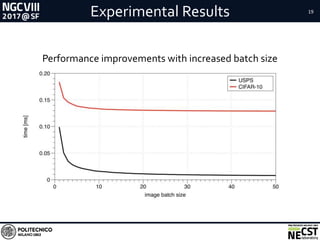
Dataset GFLOPS GFLOPS/W Images/s
Test Case 1 USPS 5.2 0.25 172414
Test Case 2 CIFAR-10 28.4 1.19 7809
MSR Work [1] CIFAR-10 - - 2318
Flips Flops LUTs BRAM DSP Slices
Test Case 1 41.10% 50.86% 3.50% 55.04%
Test Case 2 61.77% 71.24% 22.82% 74.32%
Performances and Power Efficiency Results
FPGA Resources Usage
[1] K. Ovtcharov et al., “Accelerating deep convolutional neural network using specialized hardware”, Microsoft Research
Whitepaper, 2015](https://image.slidesharecdn.com/talkquidcnndataflow-170713140513/85/CNN-Dataflow-Implementation-on-FPGAs-20-320.jpg)




![RelatedWorks● Previously based on
○ Matrix of Processing Elements [1]
○ LoopTiling + Roofline Model [1,2]
○ Parallel fixed convolvers [3]
[1] C.Zhang et al., “Optimizing fpga-based accelerator design for deep convolutional neural networks”, ISFPGA 2015
[2] M.Peemen et al., “Memory-centric accelerator design for convolutional neural networks”, ICCD 2013
[3] M.Sankaradas et al., “A massively parallel coprocessor for convolutional neural networks”, ASAP 2009
25
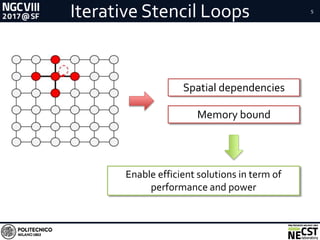
RelatedWorks
● Issues
○ Communication overhead
○ Suboptimal exploitation of on-chip memory
○ Execution in time (control flow) vs space (dataflow)](https://image.slidesharecdn.com/talkquidcnndataflow-170713140513/85/CNN-Dataflow-Implementation-on-FPGAs-25-320.jpg)

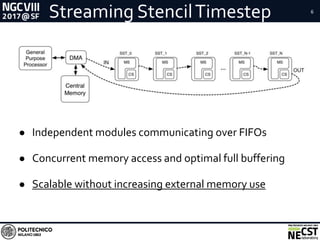
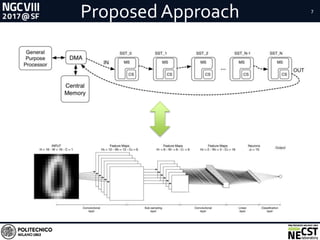
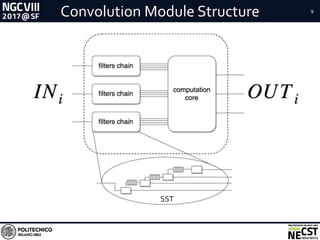
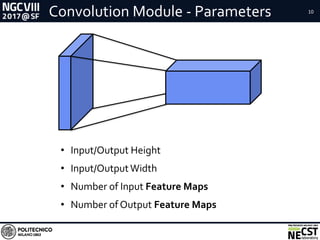
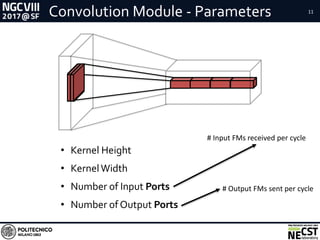
This document presents a methodology for accelerating convolutional neural networks (CNNs) on FPGAs using a dataflow approach. The key aspects of the methodology are: 1. Exploiting the dataflow pattern of CNN operations using independent modules with parametric levels of parallelism. 2. A streaming and dataflow computational paradigm with efficient memory access and full buffering to improve performance and scalability. 3. Modular implementations of convolution and fully-connected modules along with a network design approach, resulting in improved memory bandwidth utilization and high scalability given limited FPGA resources.





























![RPendsem_rsm[1]-1 , it is a research on 5 stages pipeline on risc v processor](https://cdn.slidesharecdn.com/ss_thumbnails/rpendsemrsm1-1-260115075908-8ec3c145-thumbnail.jpg?width=640&height=640&fit=bounds)











































