Download as PDF, PPTX










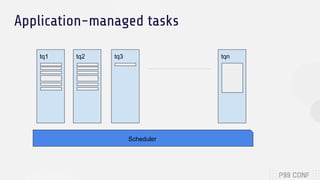
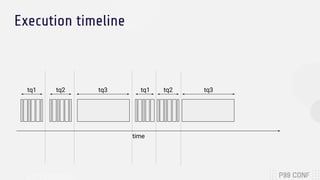





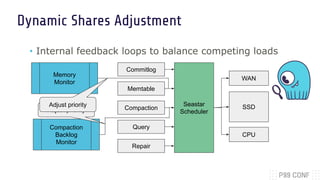
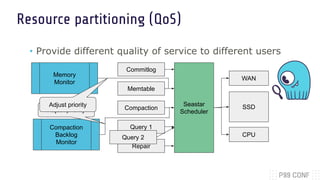



The document discusses optimizing both throughput and latency in computing by utilizing application-level priority management and task isolation strategies. It highlights the differences between throughput computing, which focuses on maximizing utilization, and latency computing, which prioritizes timely operations. Additionally, it introduces ScyllaDB, a distributed NoSQL database that significantly outperforms others in low-latency scenarios and outlines its design principles for efficient task scheduling.























































































