








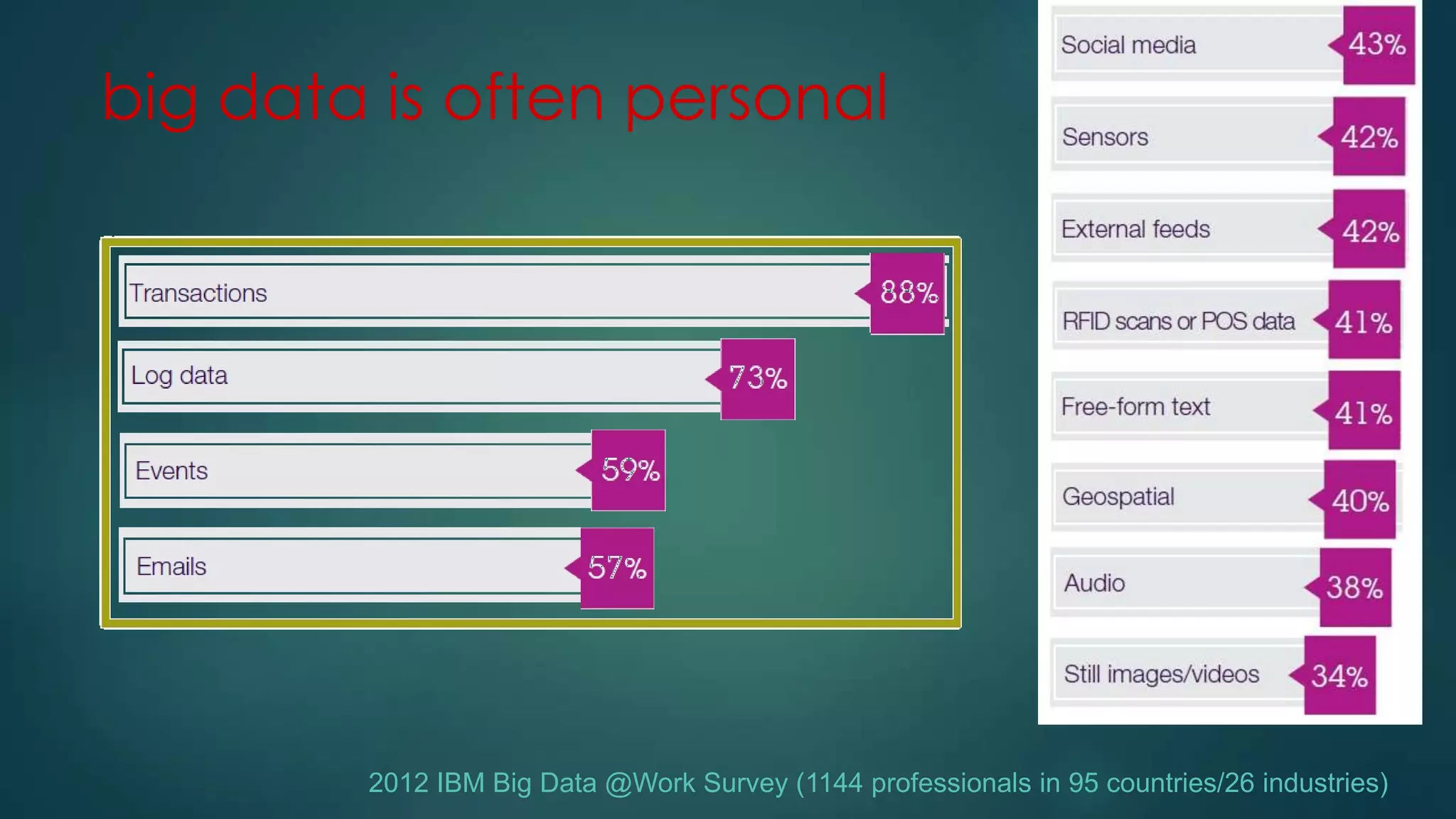
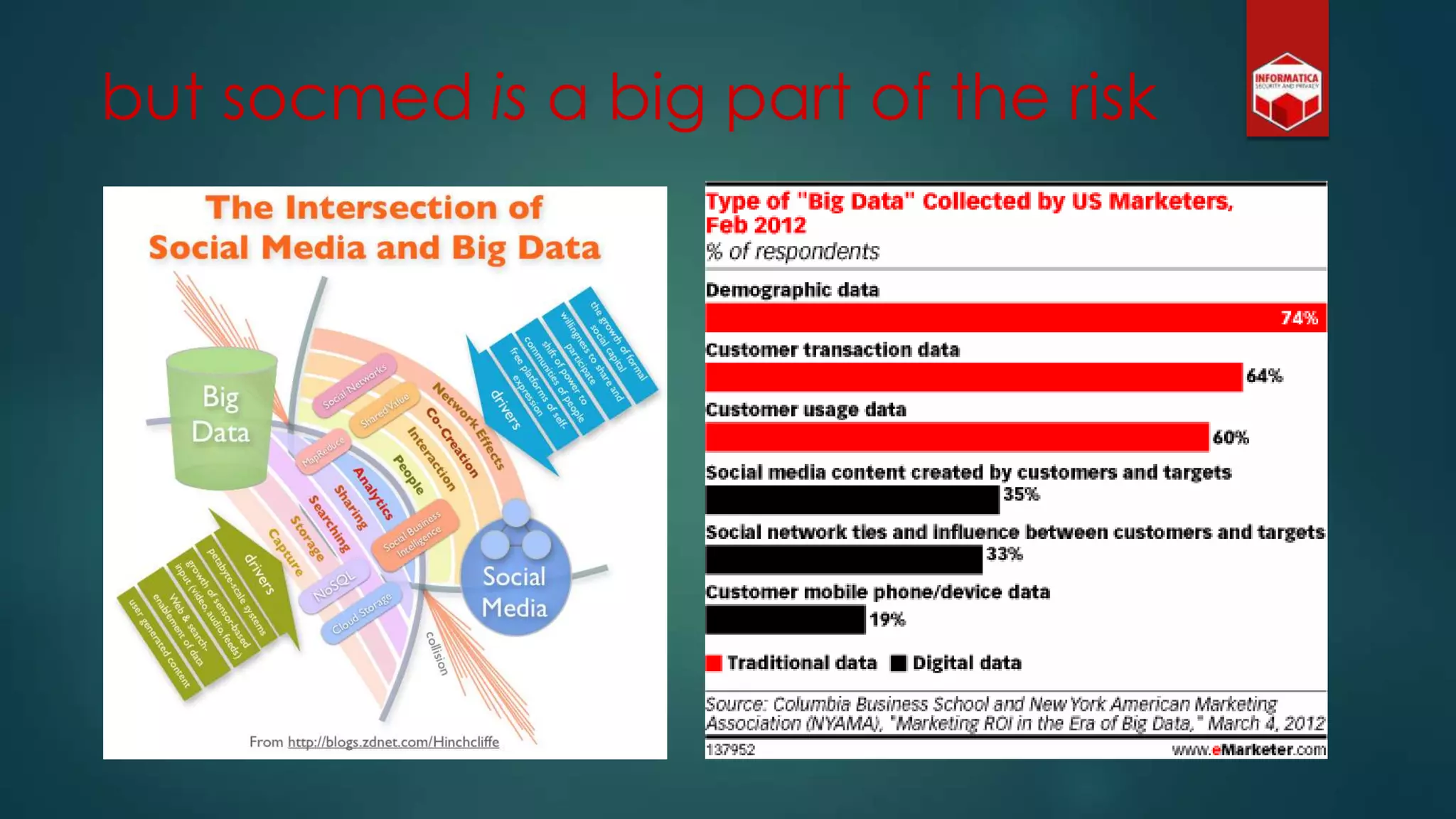
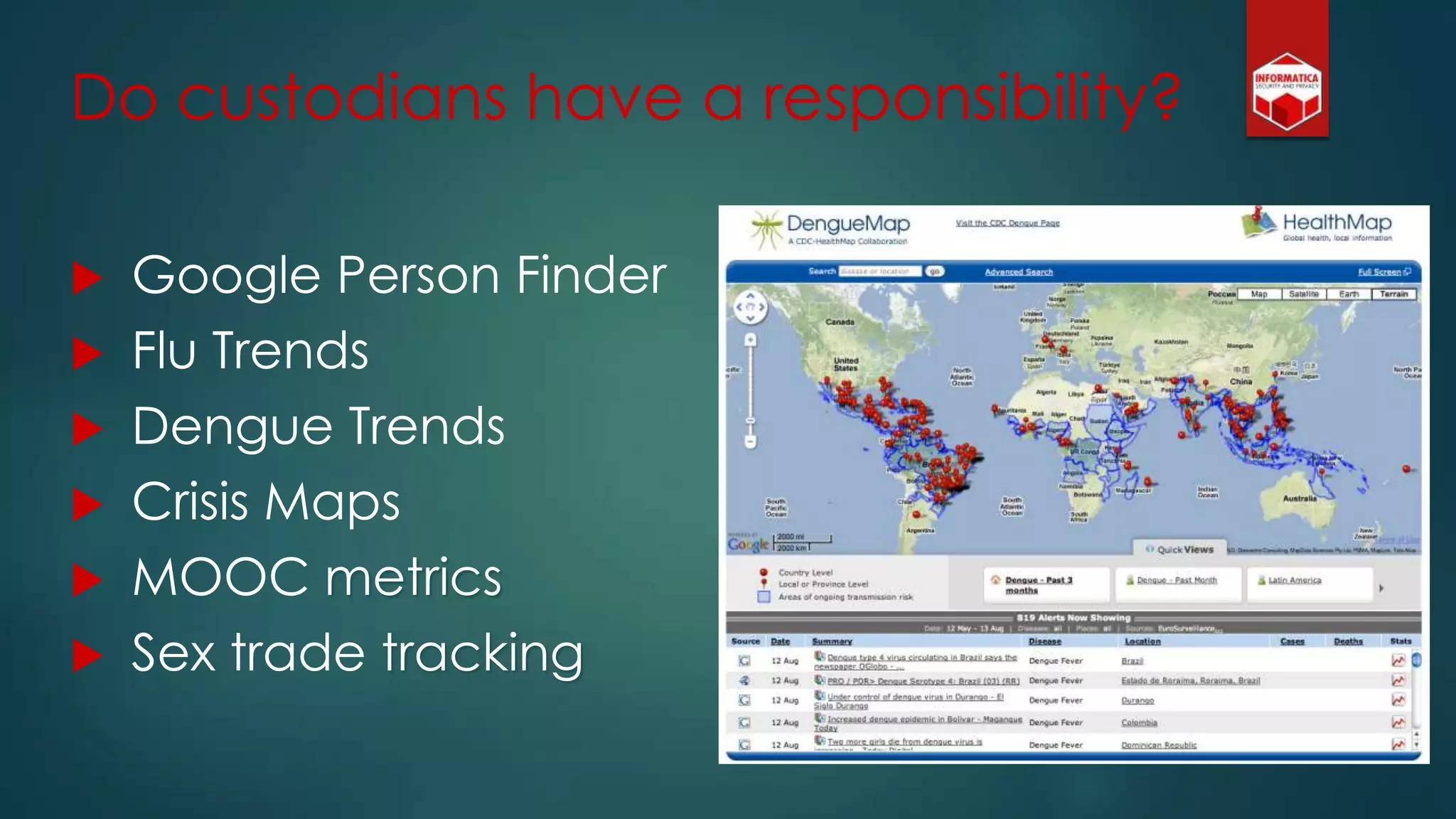
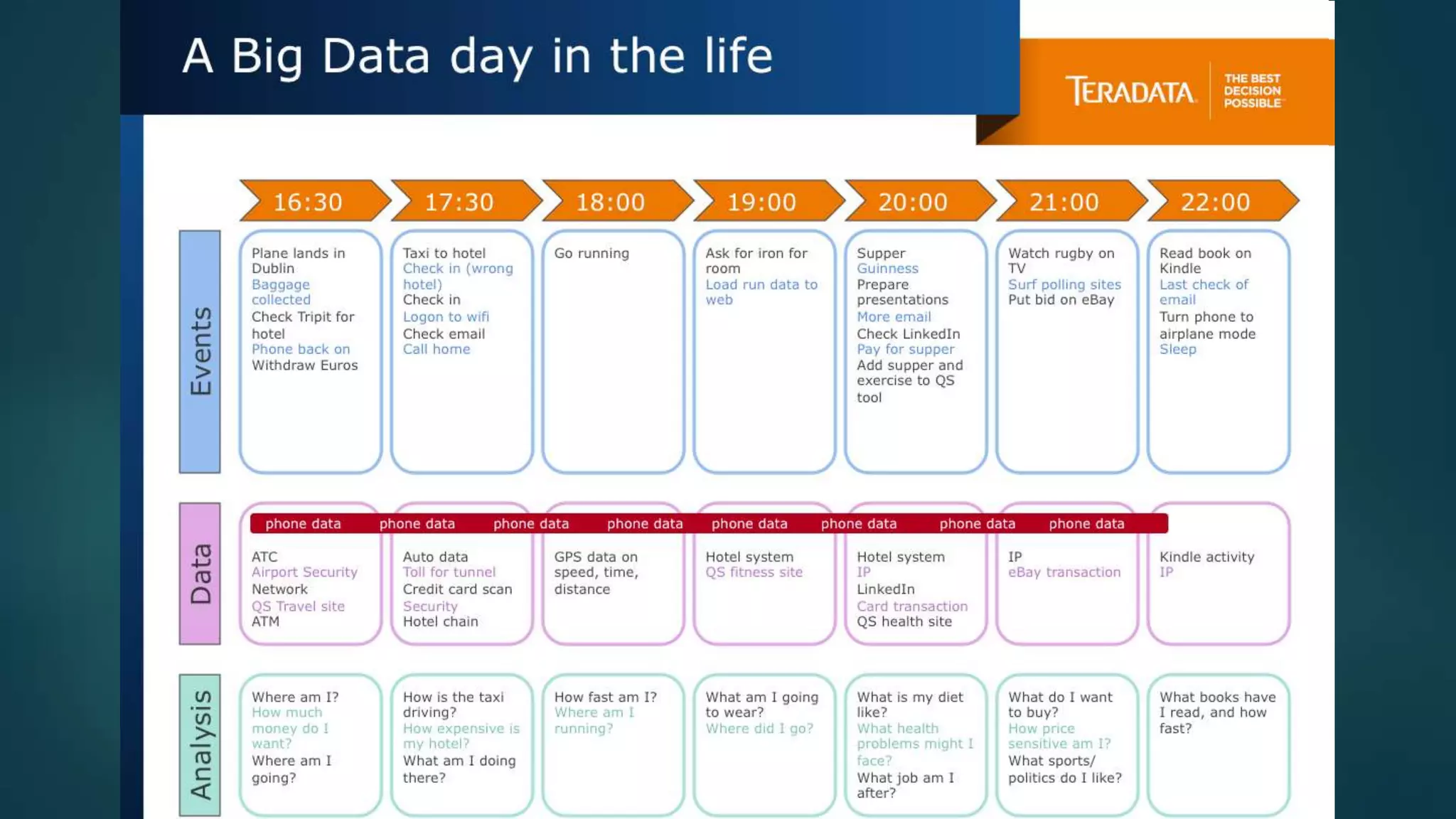





























![Privacy must be tack[l]ed [head-]on](https://image.slidesharecdn.com/iapp-bigdata-130920084113-phpapp01/75/The-REAL-Impact-of-Big-Data-on-Privacy-54-2048.jpg)







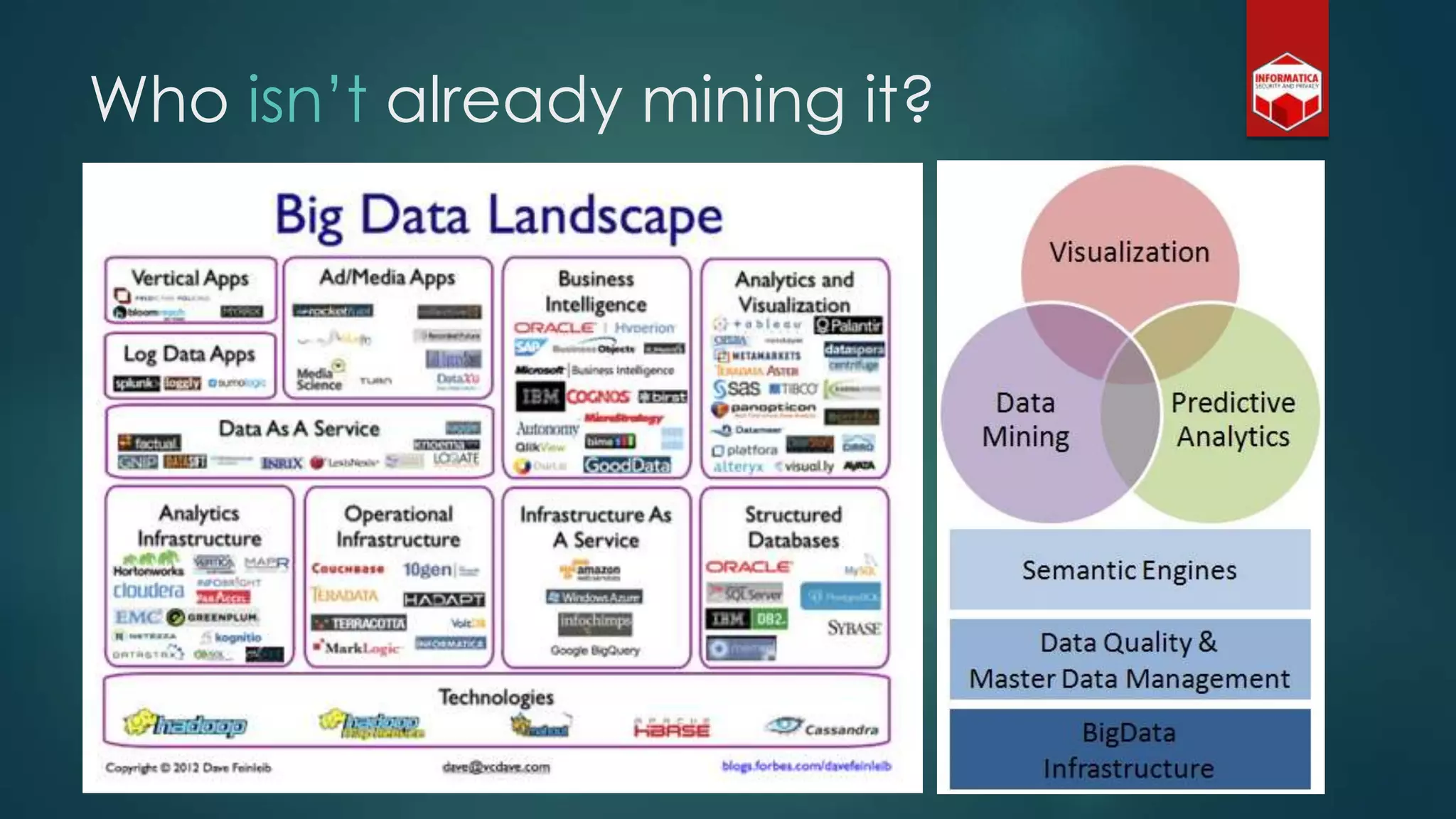
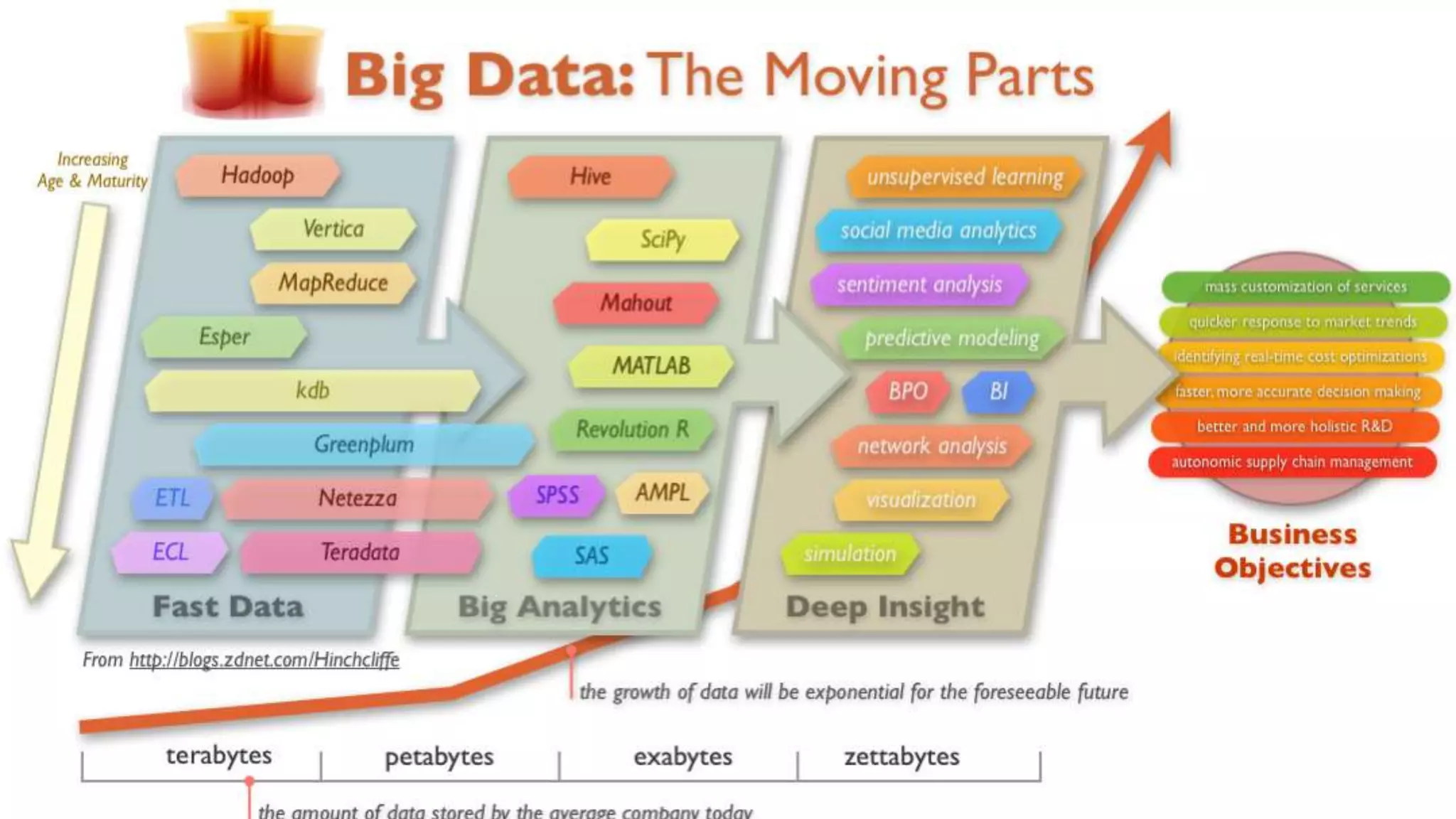
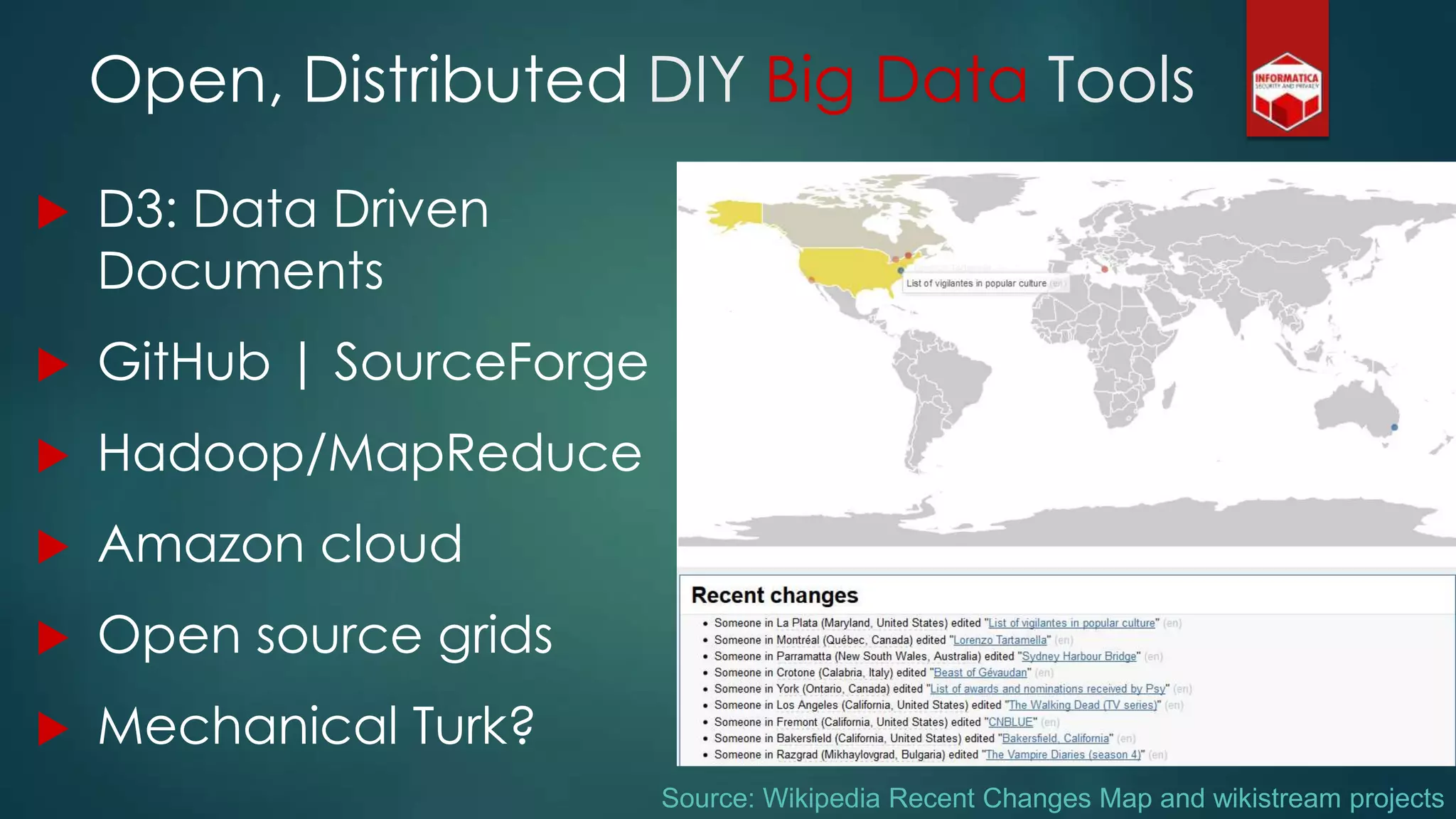
The document explores the concept of big data, its promises, challenges, and implications for privacy and business intelligence. It emphasizes the importance of data analytics in various fields, from crime prediction to customer service, while also addressing the risks associated with personal data usage and the need for responsible data handling. Overall, it advocates for a balanced approach to harnessing big data's potential while safeguarding individuals' privacy.


























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








