Download to read offline











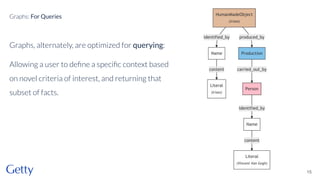

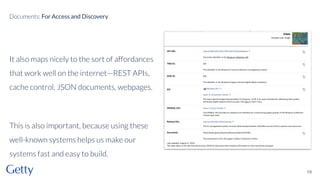


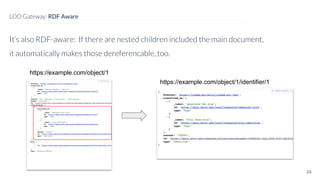

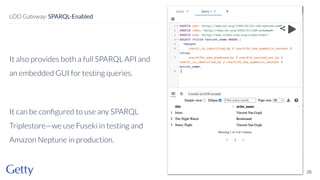



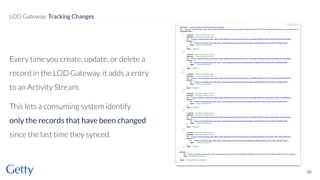
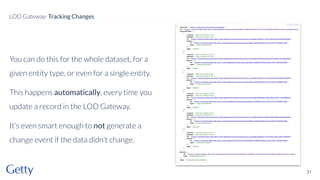




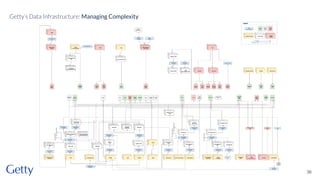
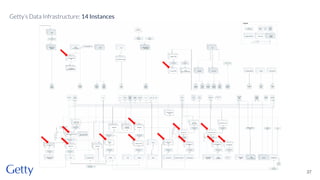



David Newbury from Getty discusses the open-source LOD Gateway, a tool designed to manage linked data in art and architecture since 2014. The Gateway simplifies the complexities of linked data by supporting both document-based access and graph-based querying, allowing users to efficiently create, update, and maintain JSON-LD records. This initiative follows Getty's commitment to improving data infrastructure while offering the tool under an open-source license to benefit the broader community.



































































