Download as PDF, PPTX




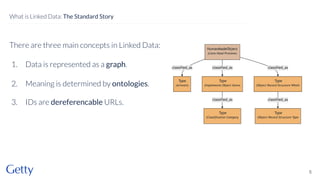
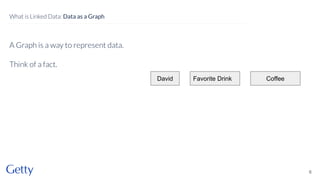
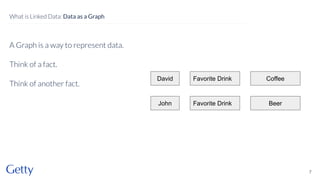
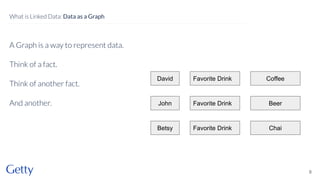



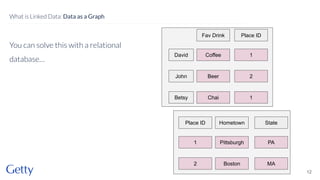
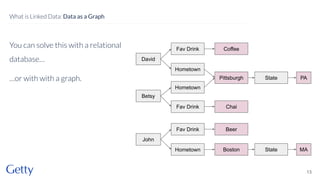

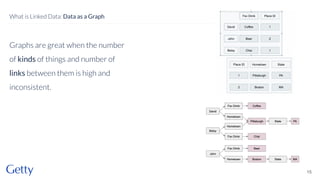
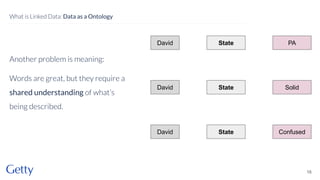
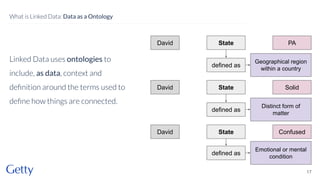
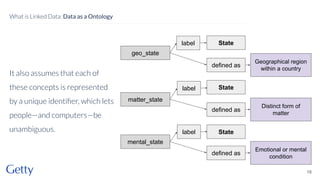
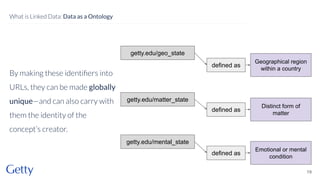
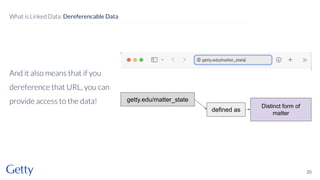
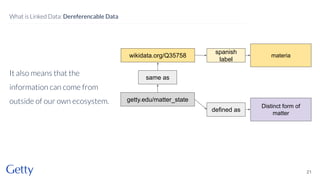

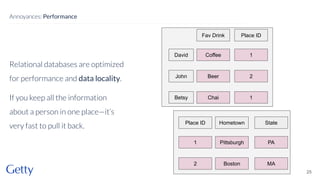


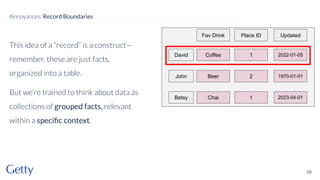
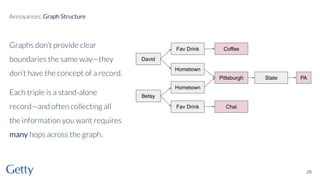
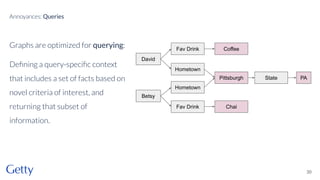
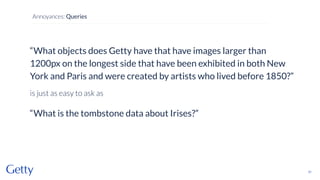


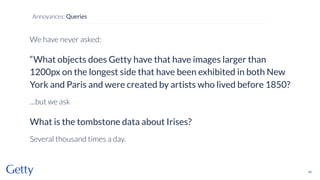
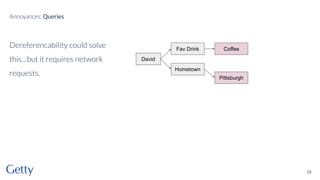
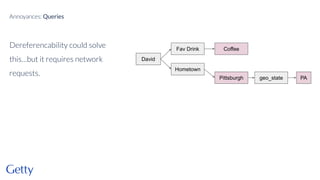
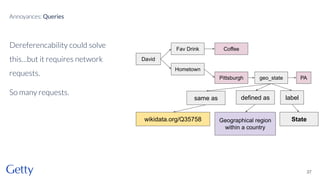
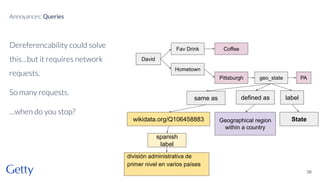
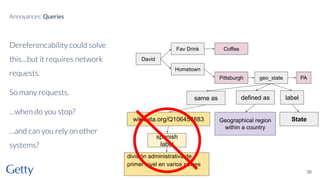



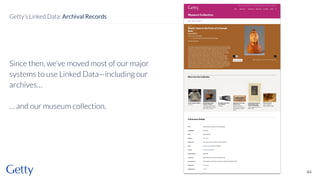




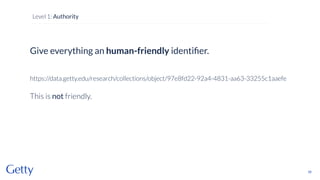
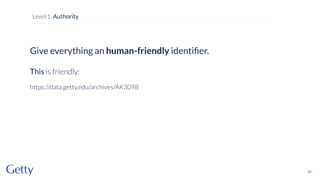
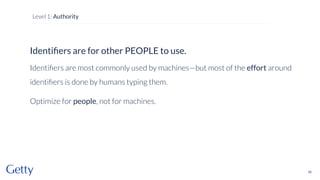


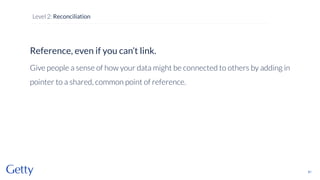








David Newbury of the Getty discusses linked data, emphasizing its advantages as a semantic web and its representation of data as graphs with dereferencable URLs. He outlines the challenges associated with linked data, including performance, query complexity, and practicalities of implementation, alongside lessons learned from Getty's experience in utilizing linked data since 2014. The presentation concludes with a framework for organizations to adopt linked data, highlighting the importance of identifiers, reconciliation, bidirectional linking, aggregation, interoperability, and building community around shared data.



































































