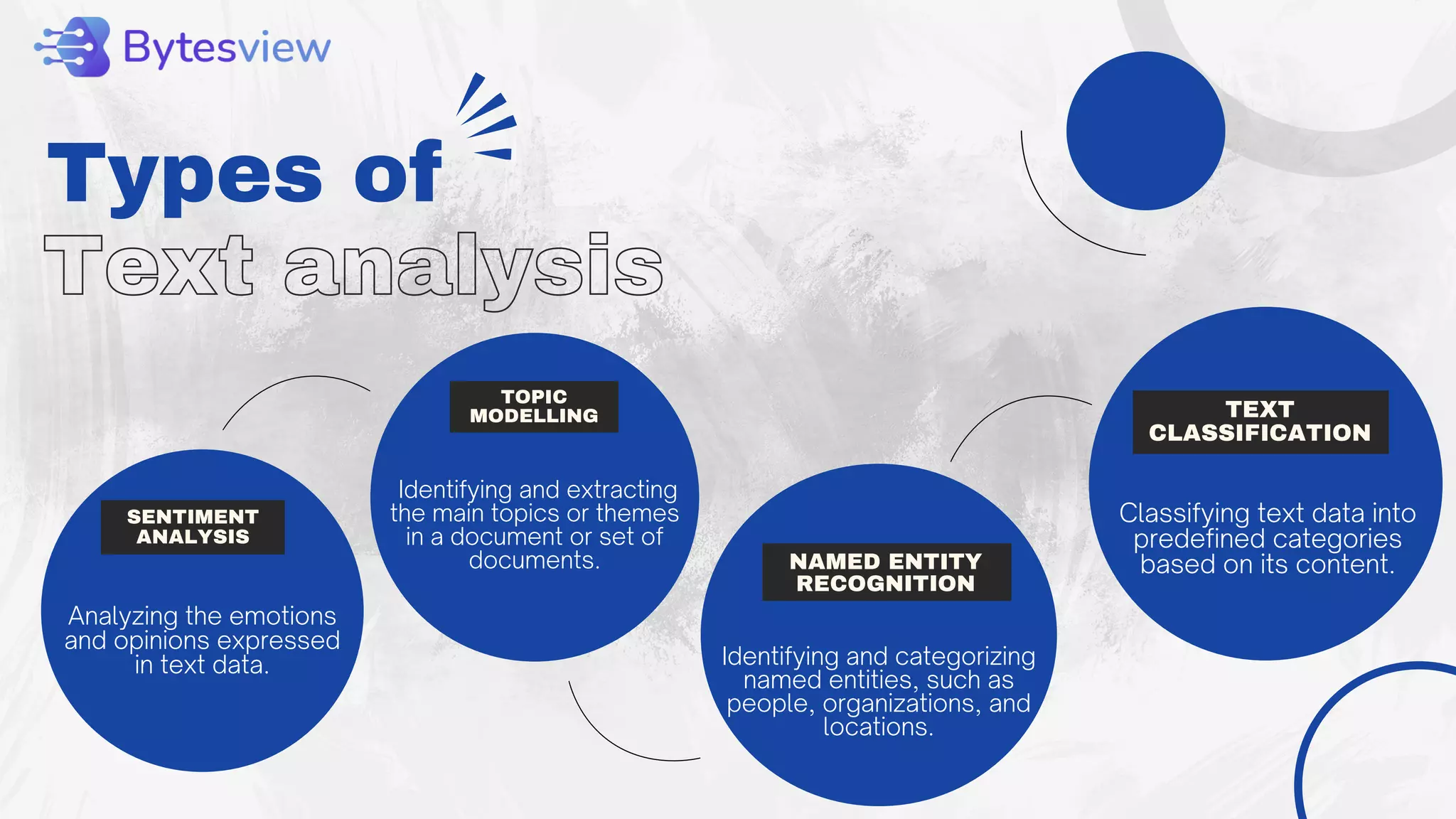
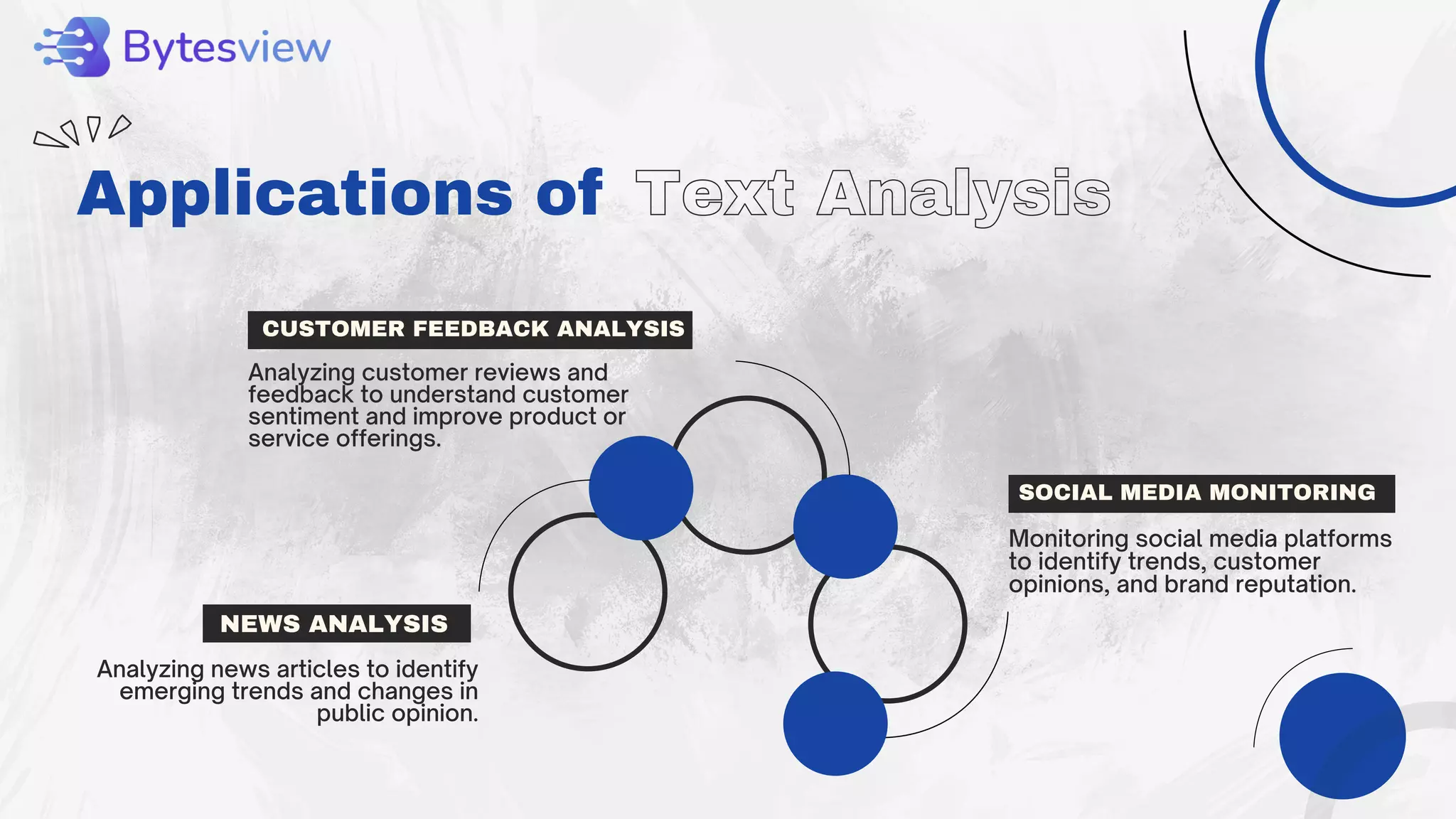
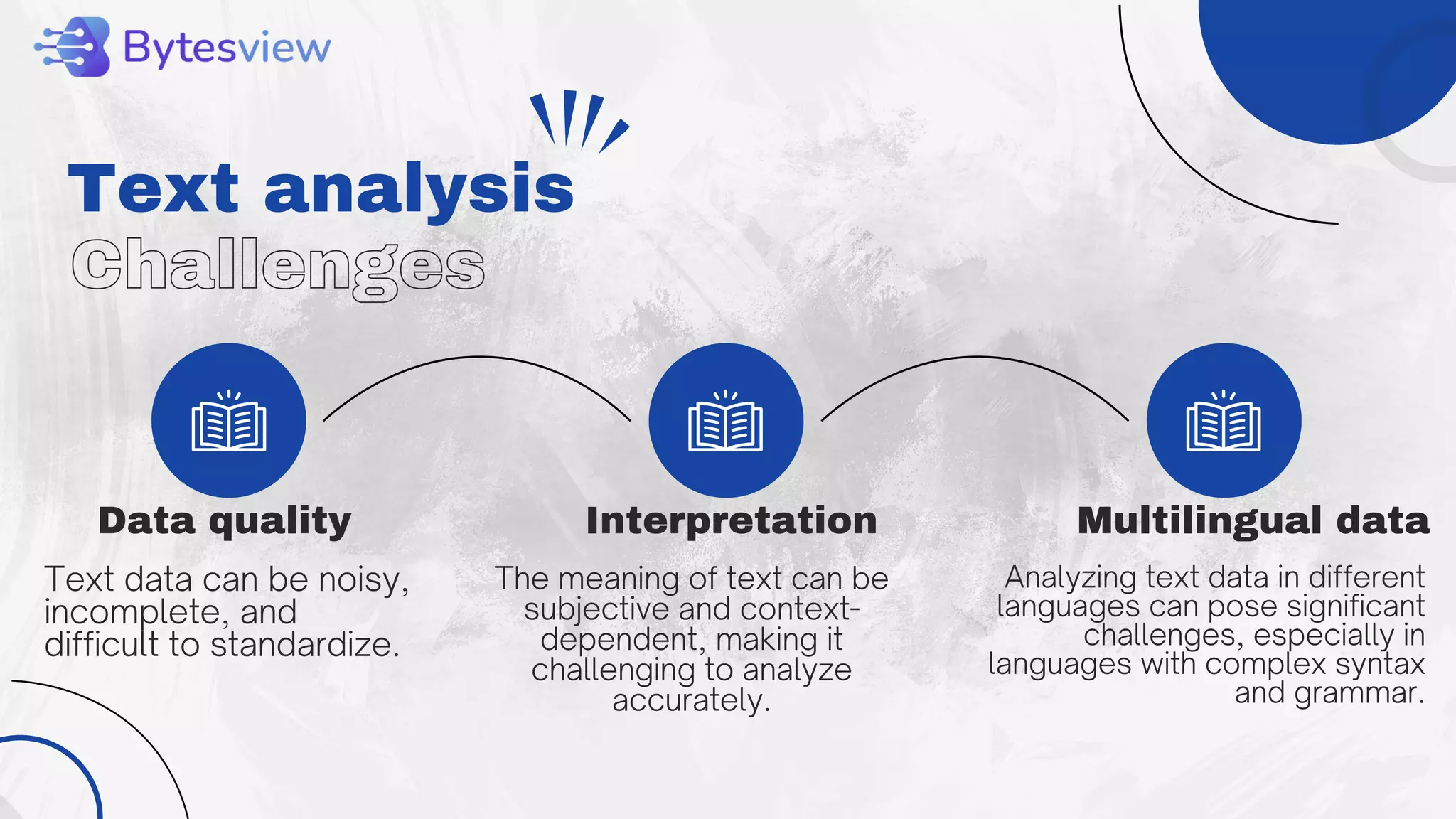
The document outlines the process of text analysis, defining it as the examination and interpretation of text data to extract meaningful insights using techniques like sentiment analysis and natural language processing. It discusses various types of text analysis and their applications, including customer feedback and social media monitoring, while addressing challenges such as data quality and multilingual interpretation. Ultimately, it emphasizes the importance of text analysis in driving informed decisions and business value despite the inherent challenges.





















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















