Downloaded 14 times




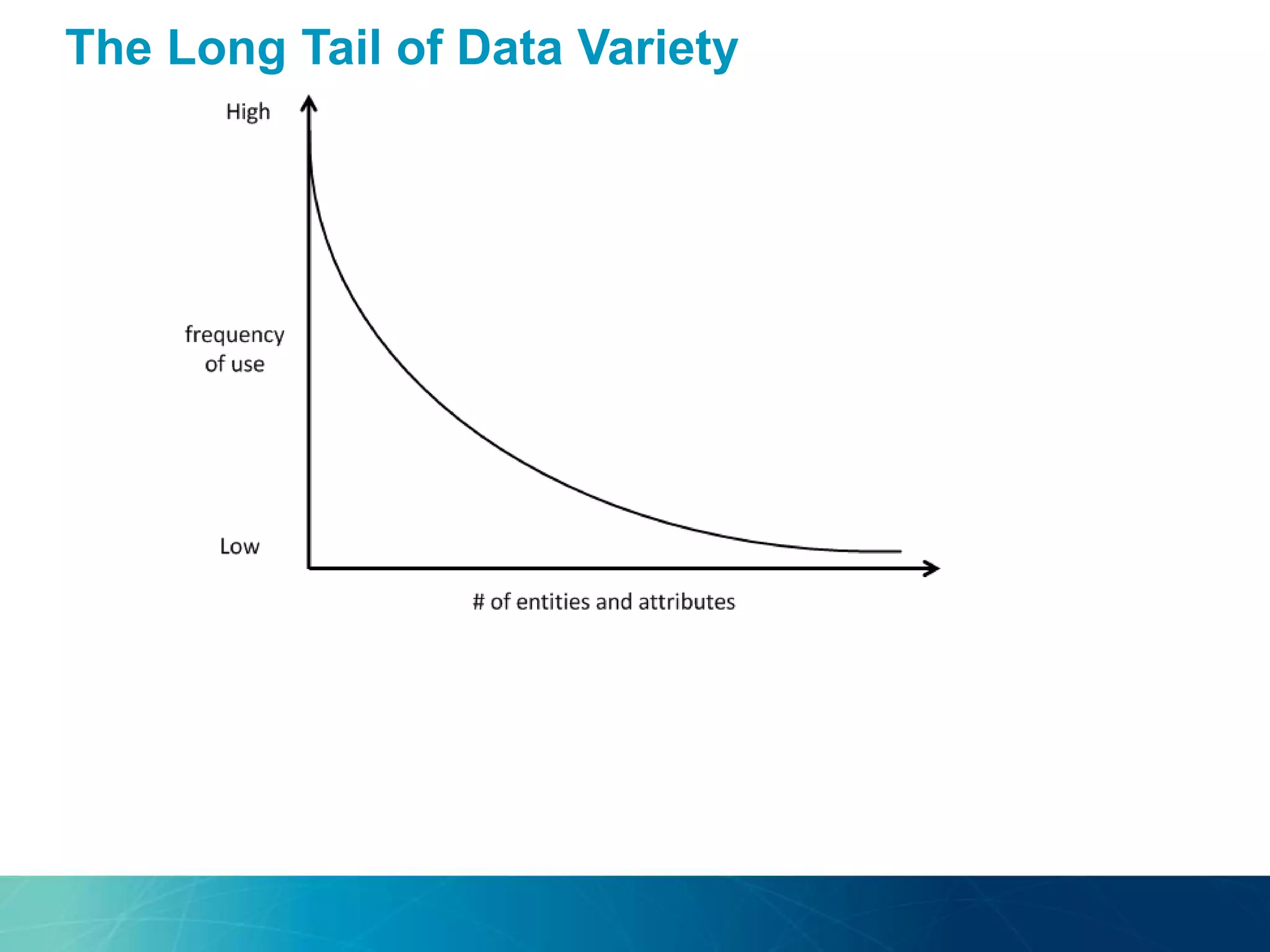
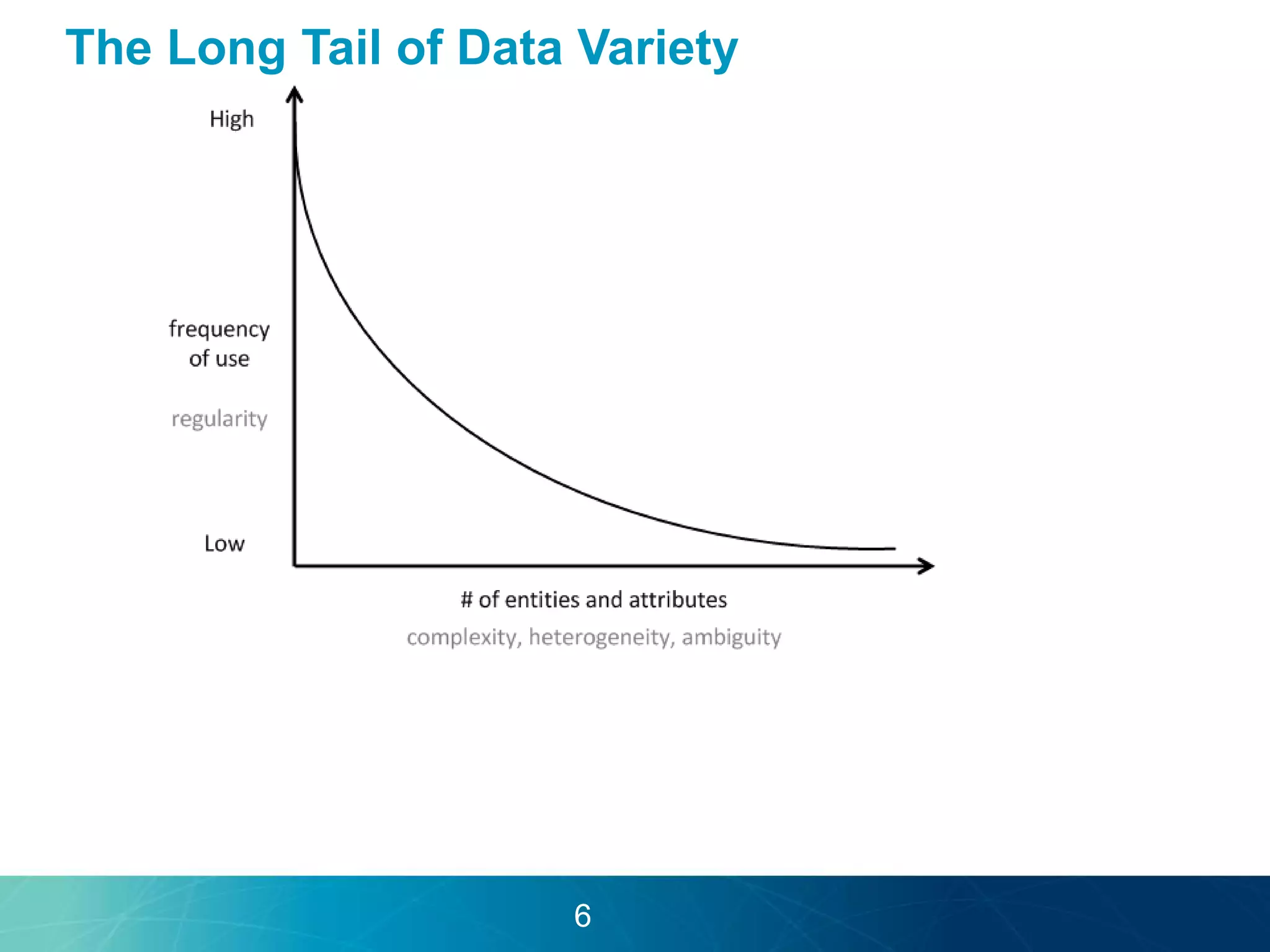
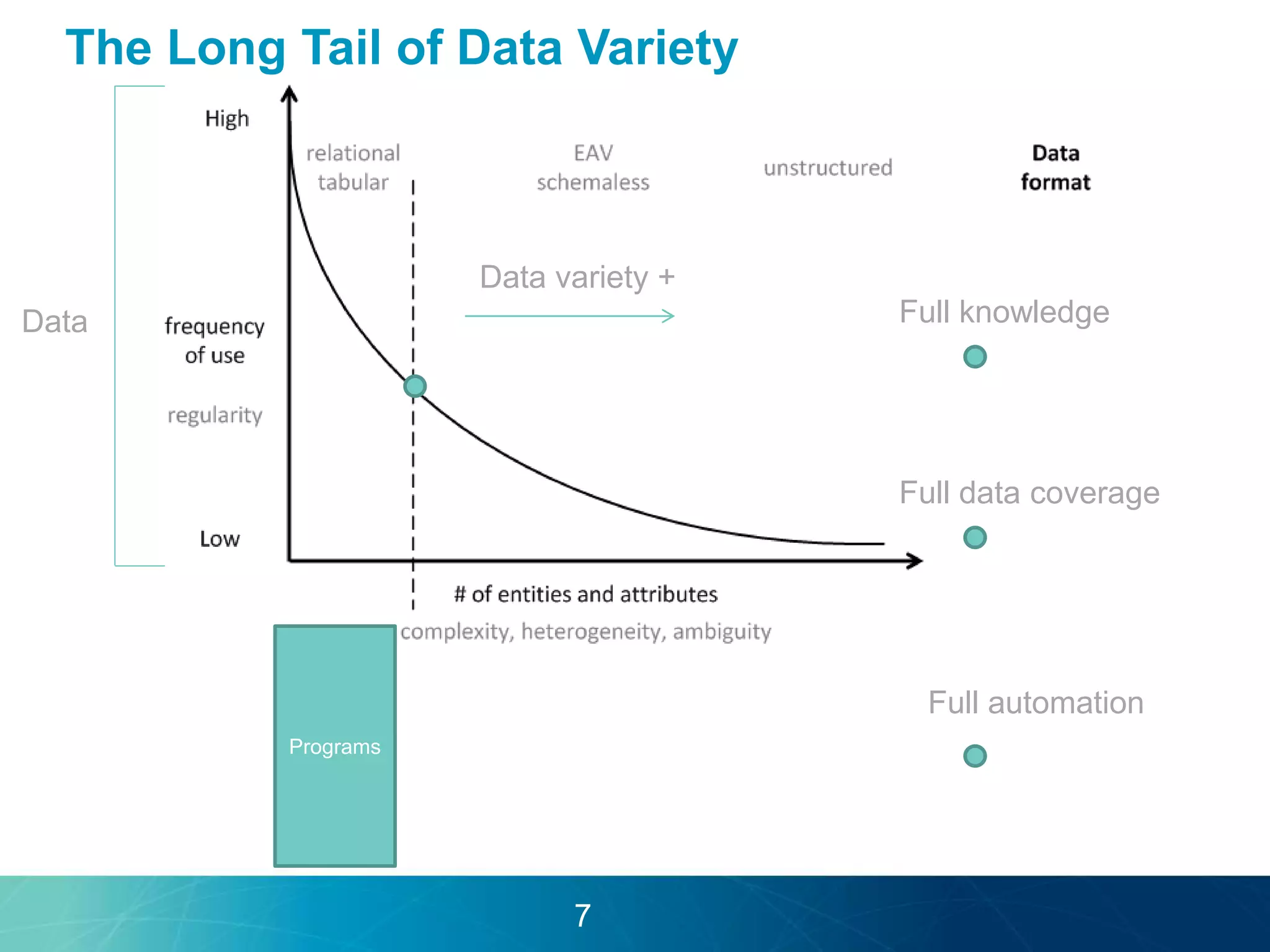
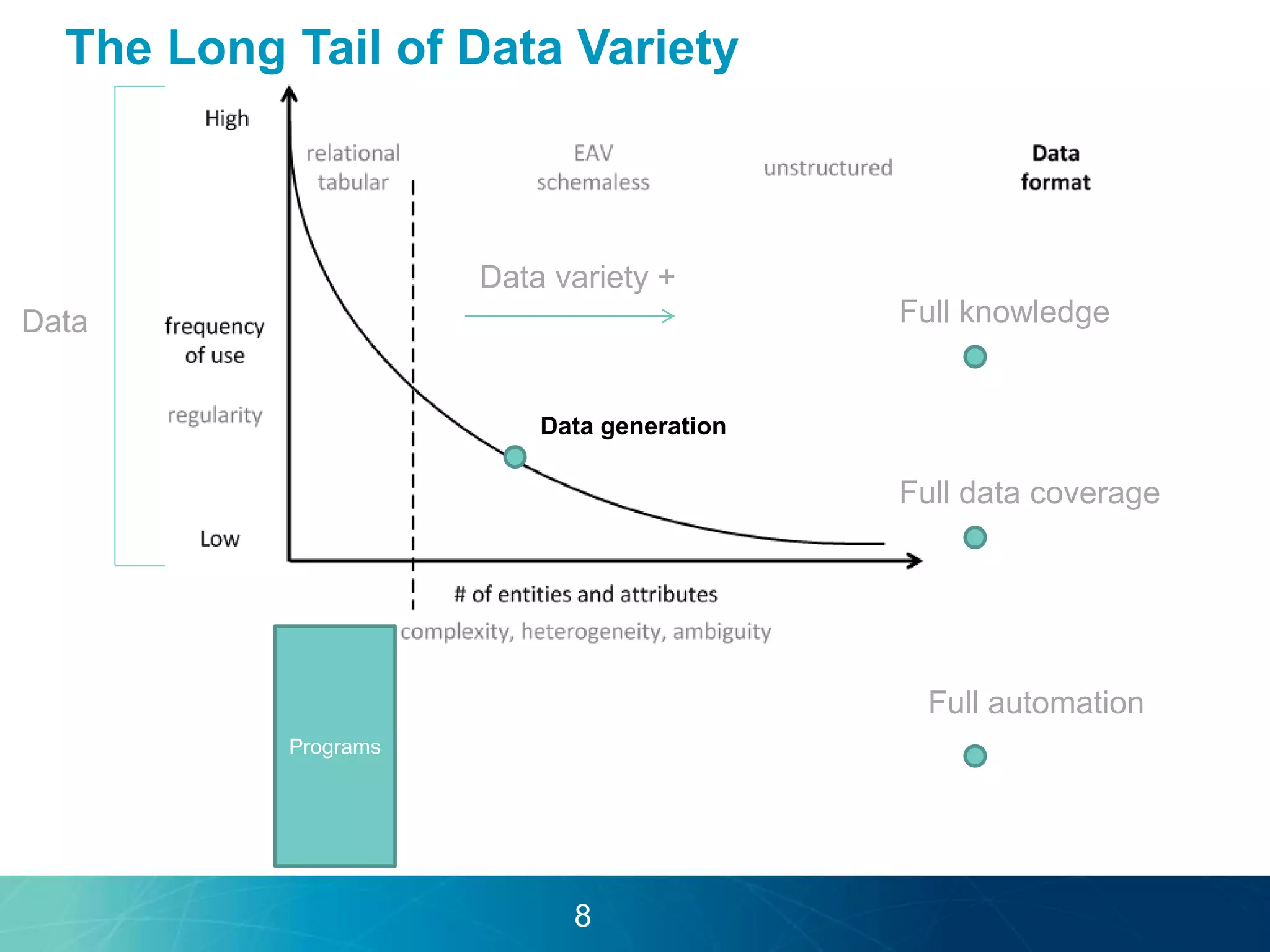

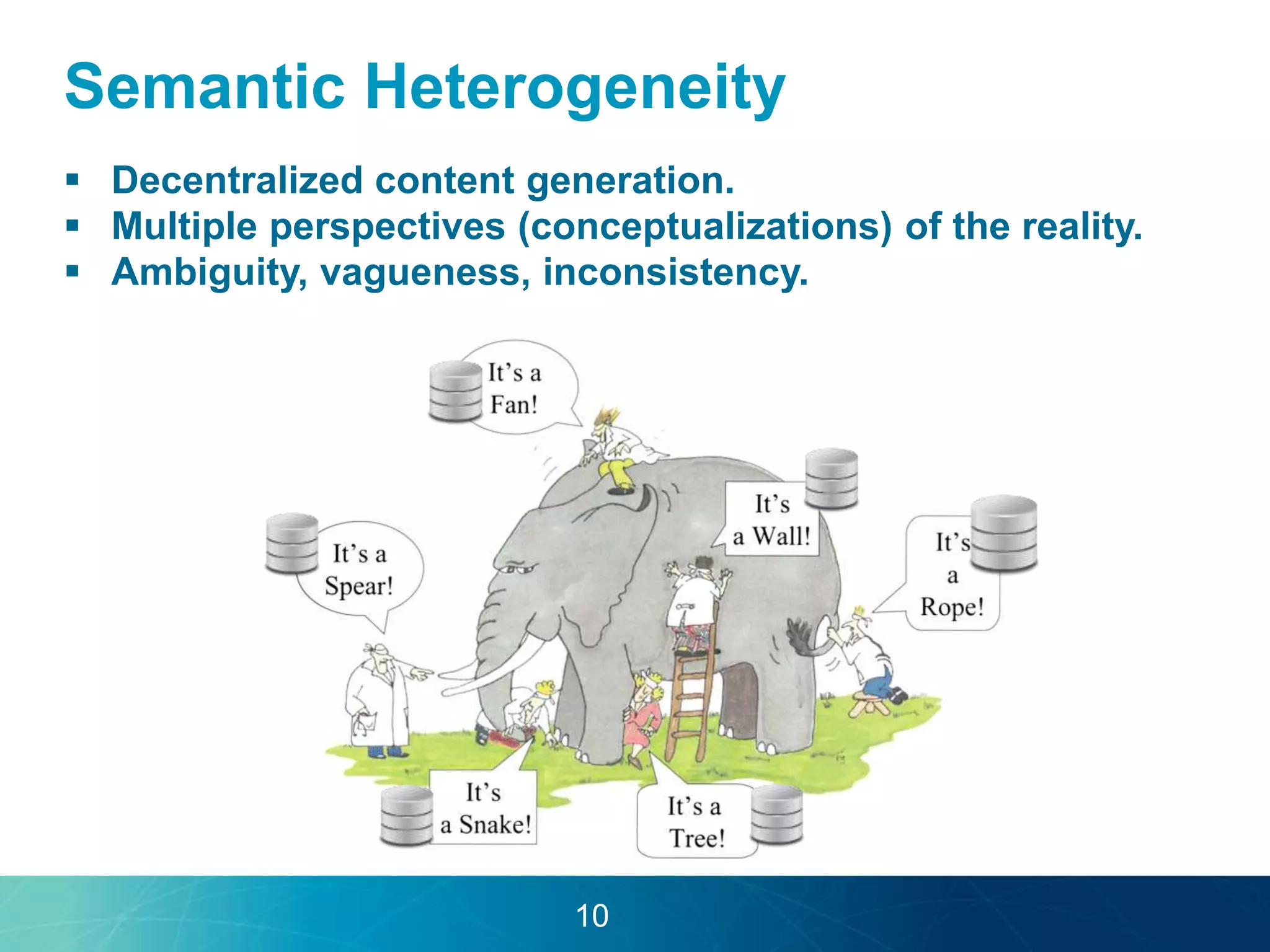
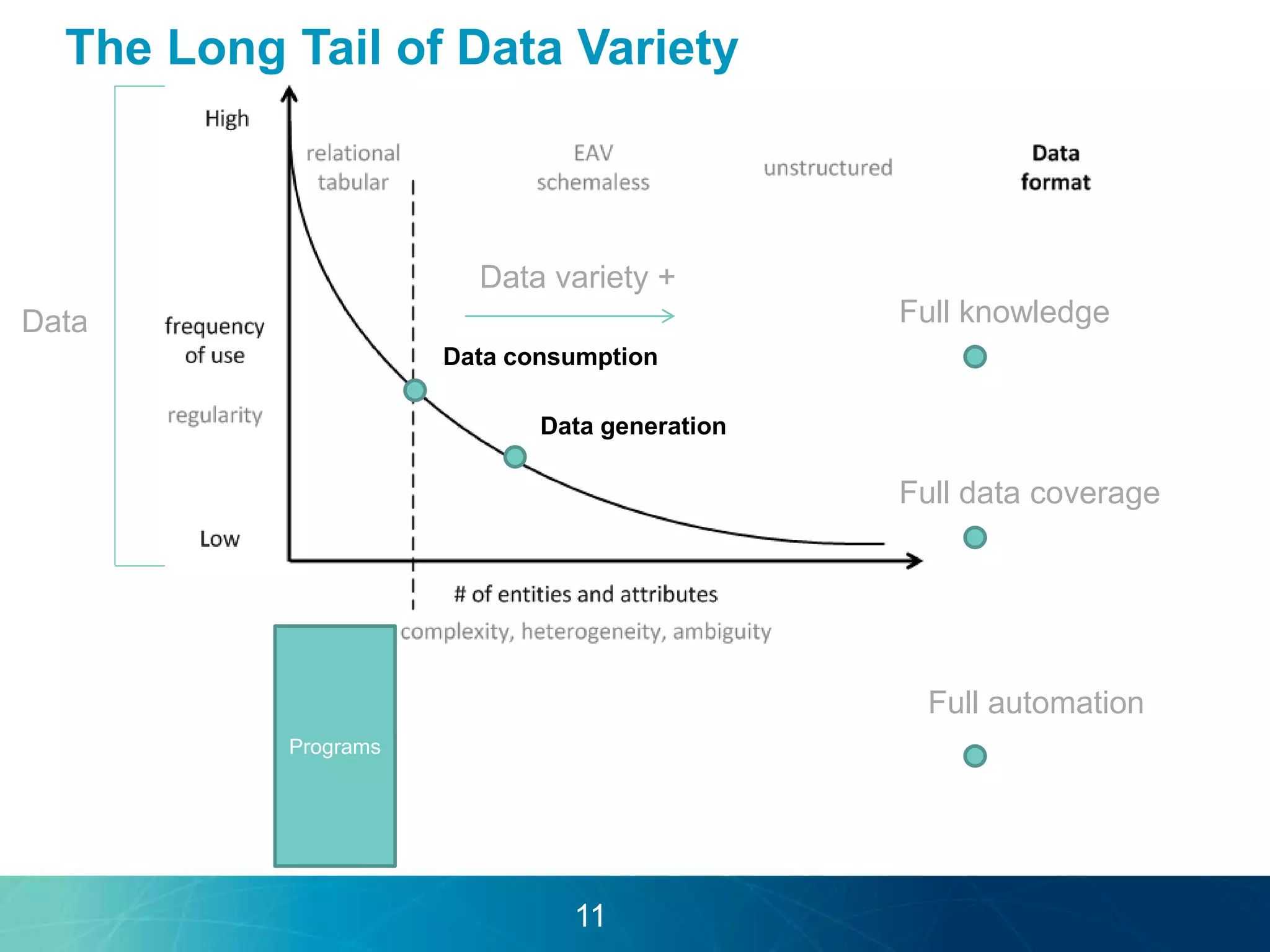

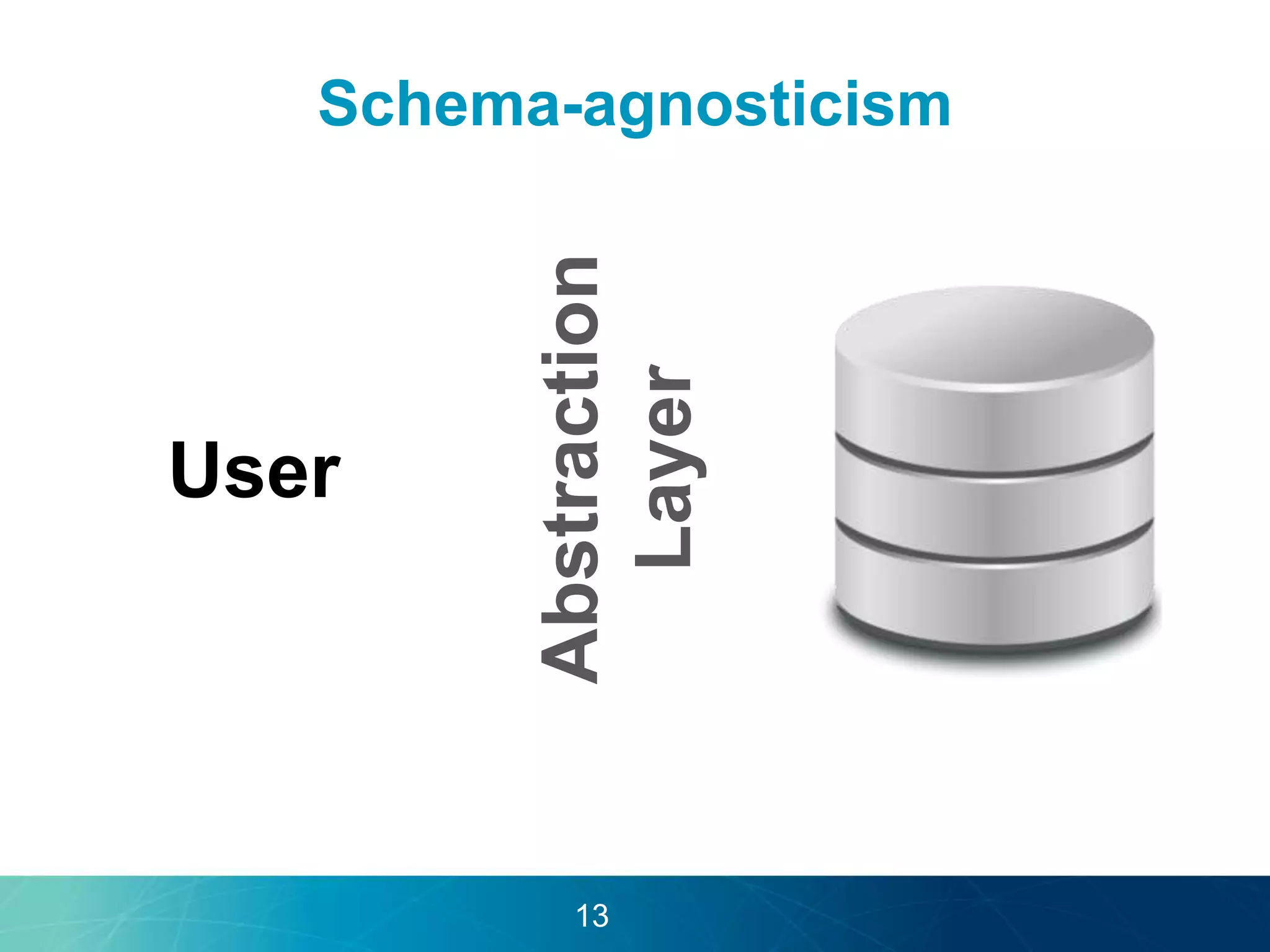


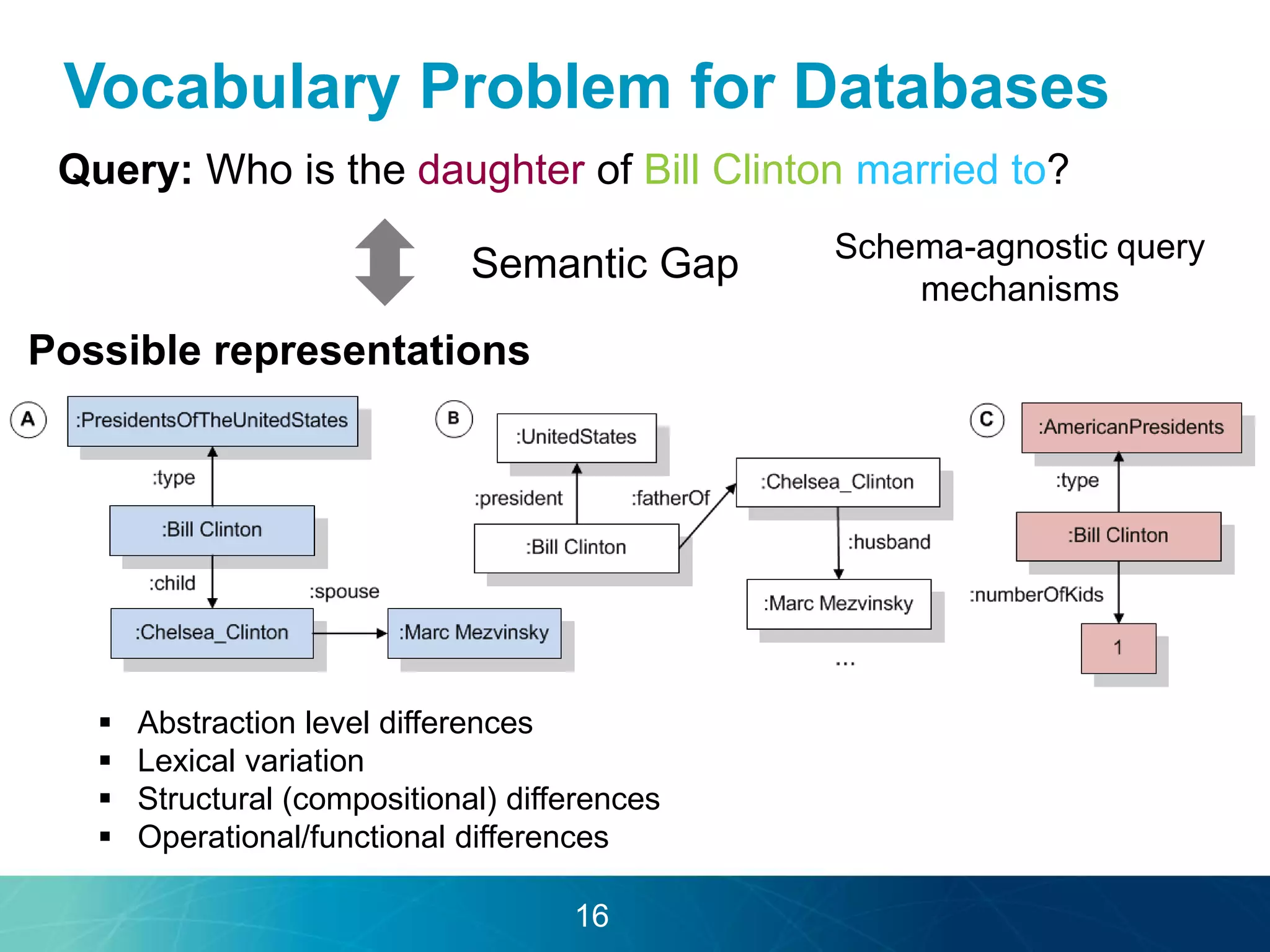







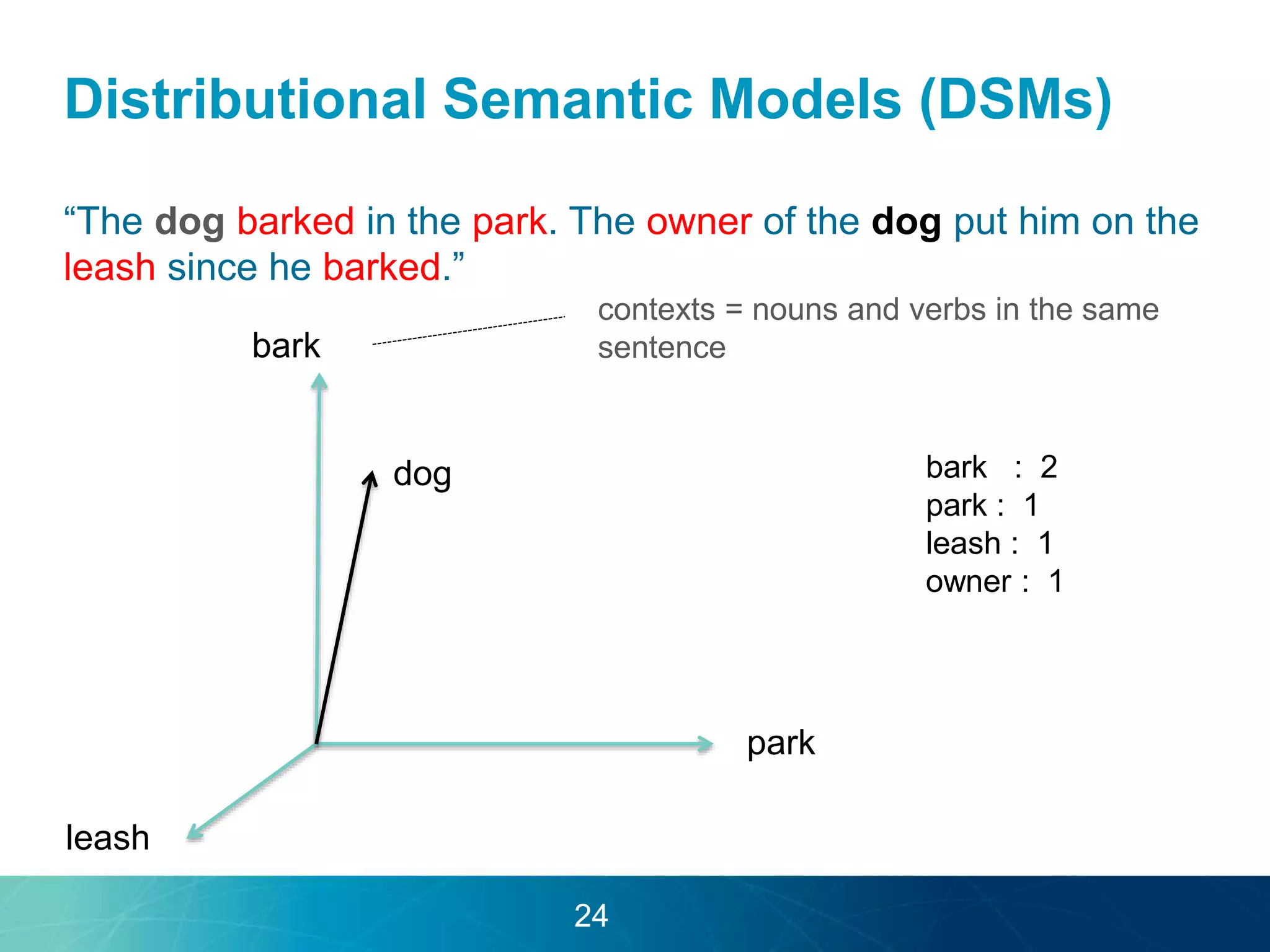
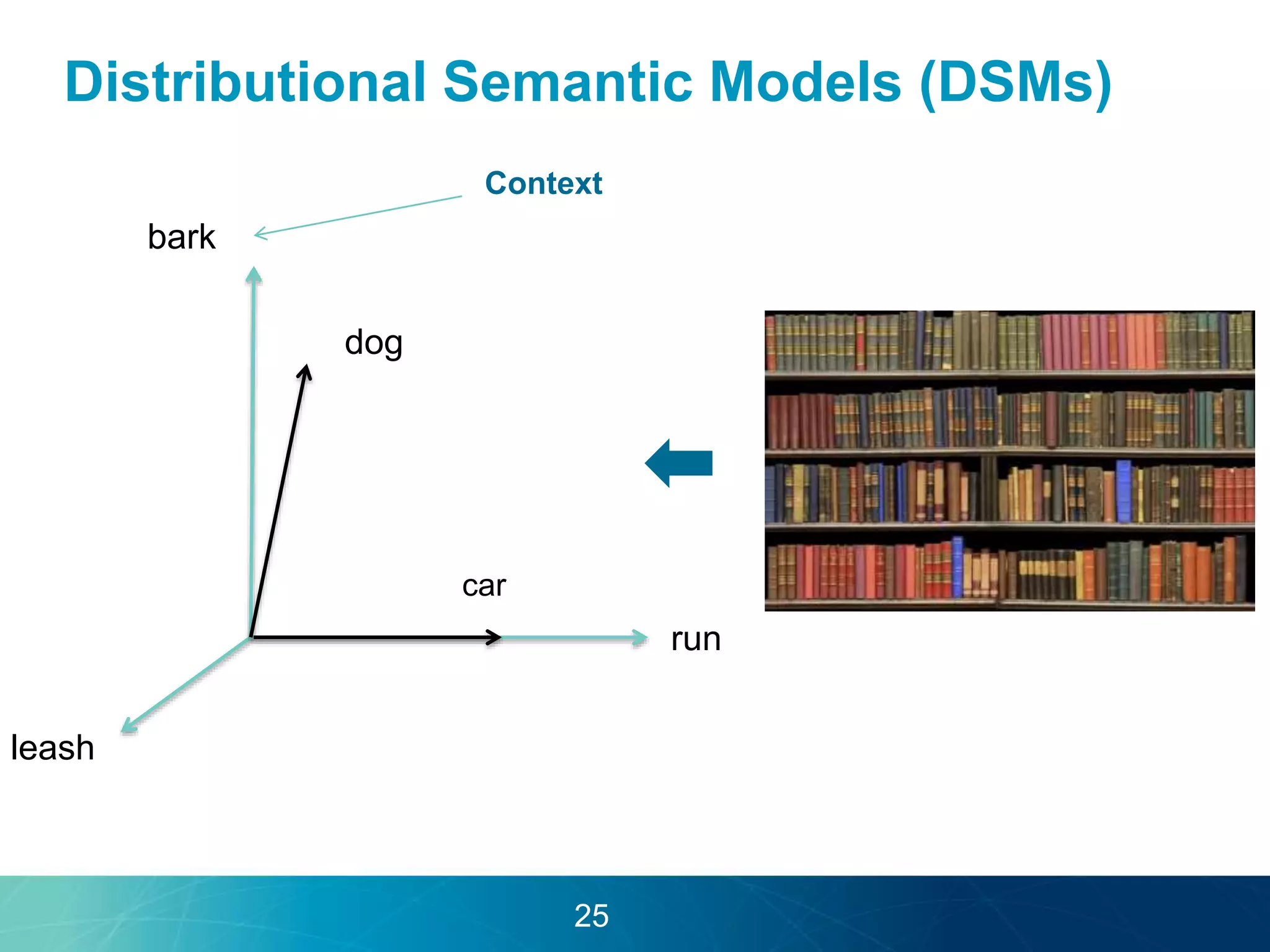



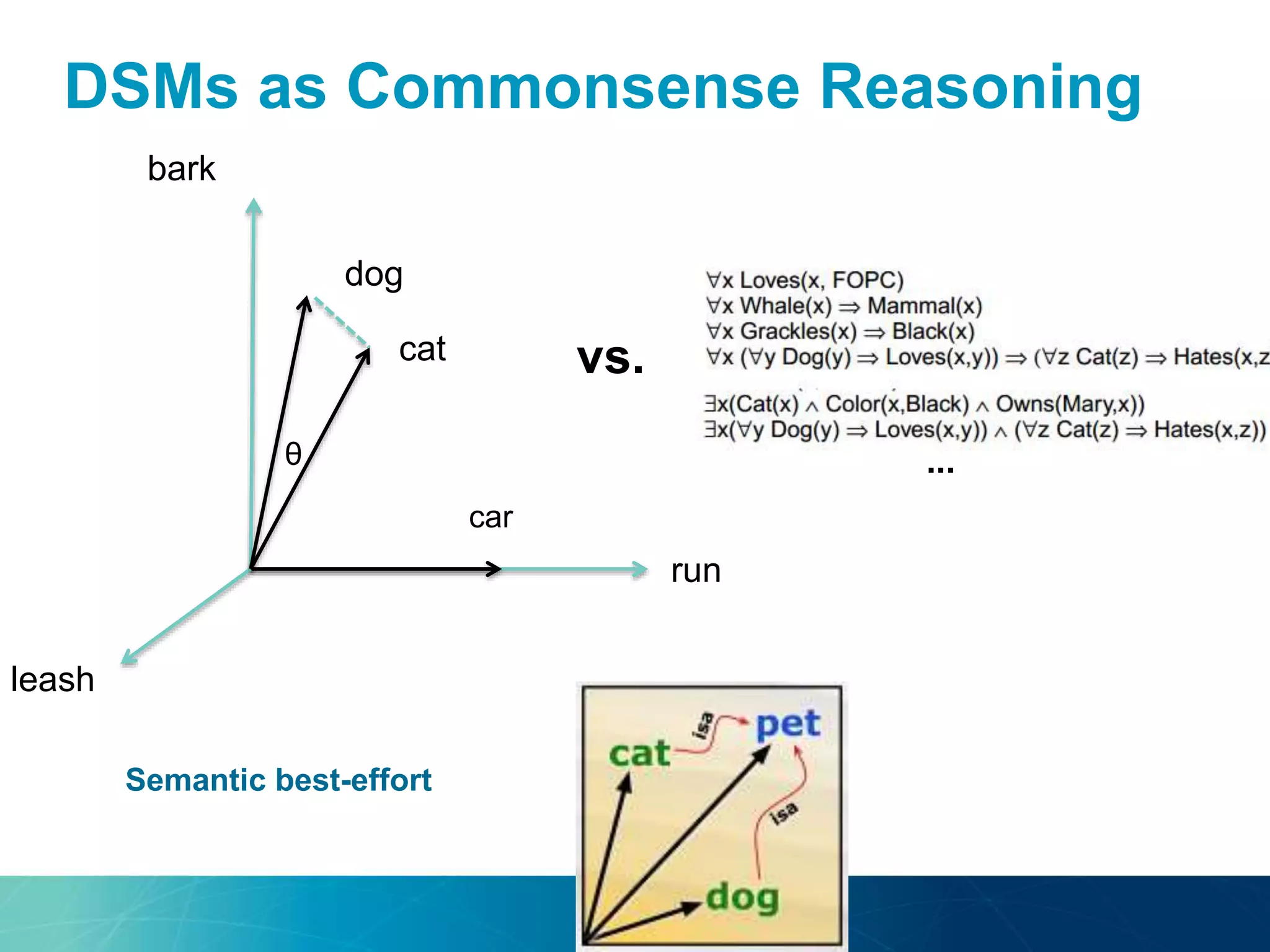

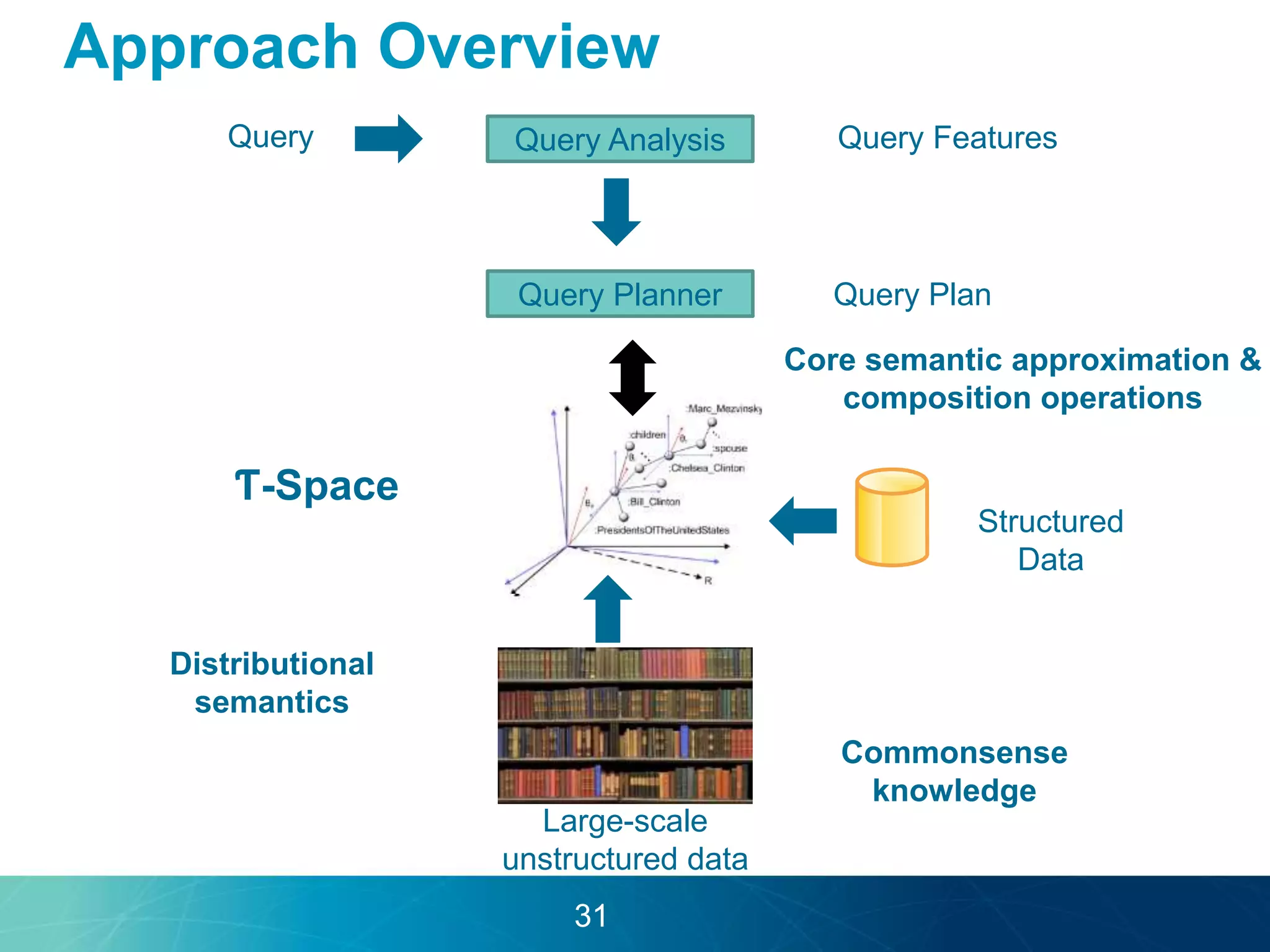
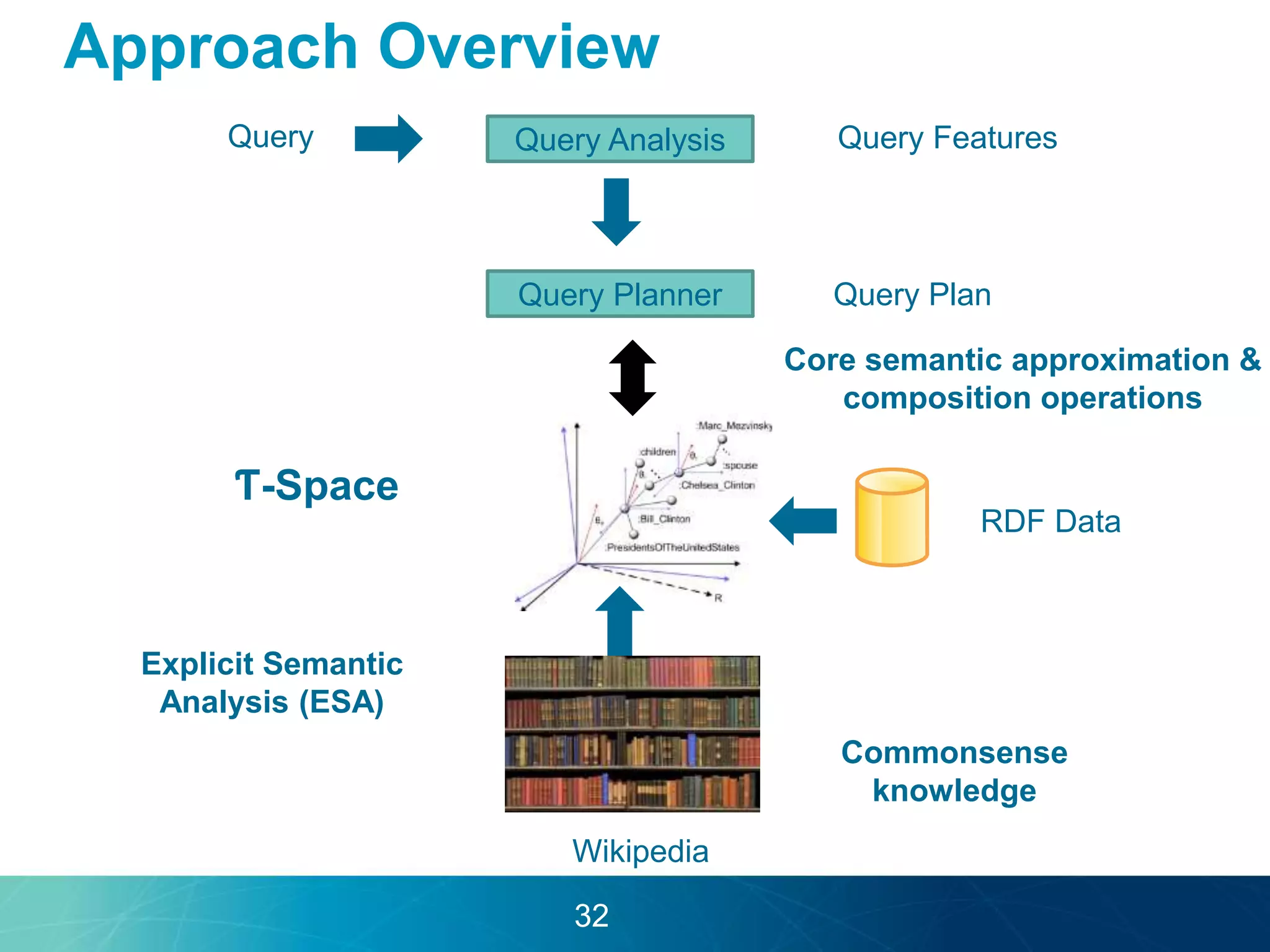





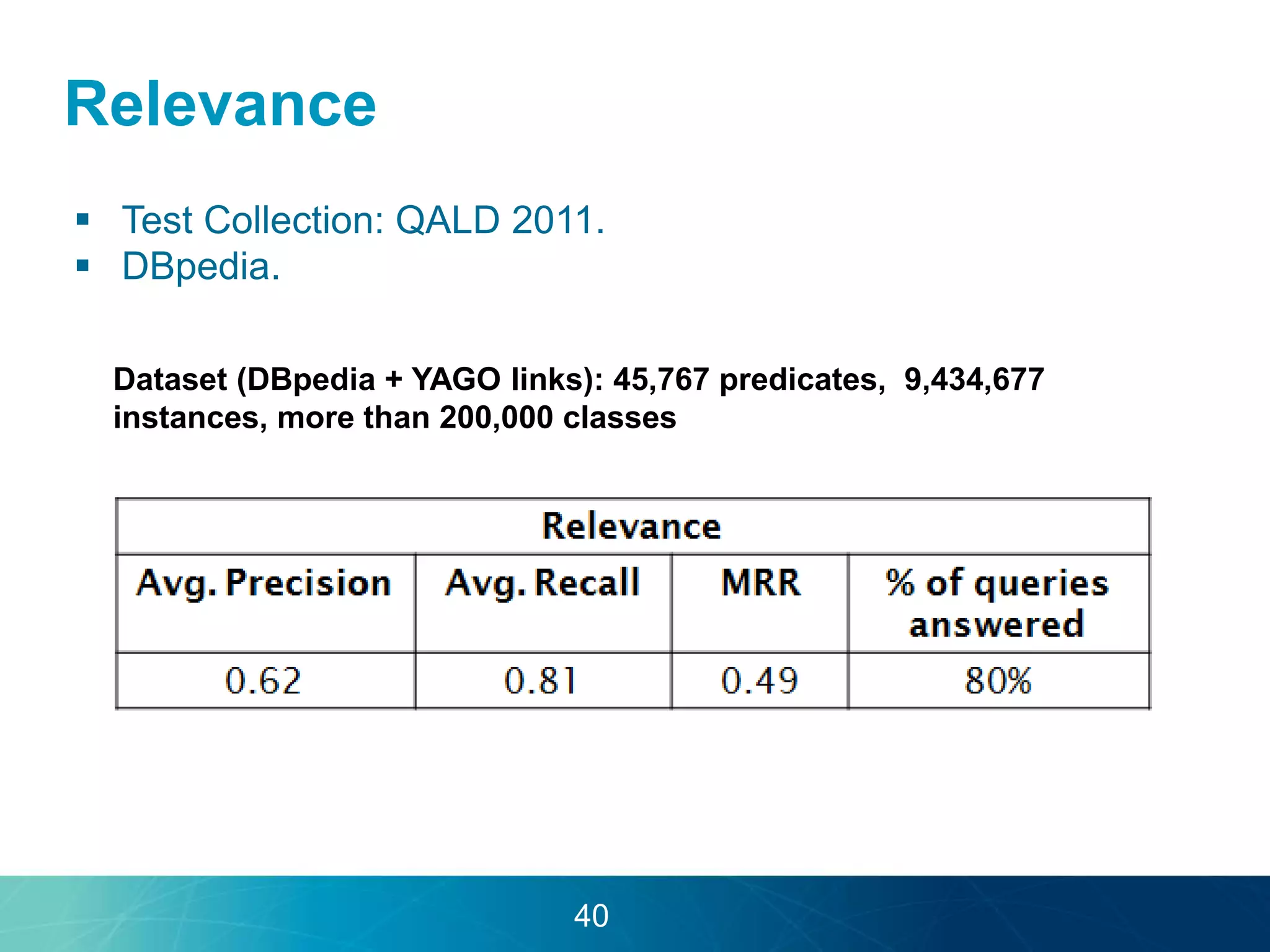





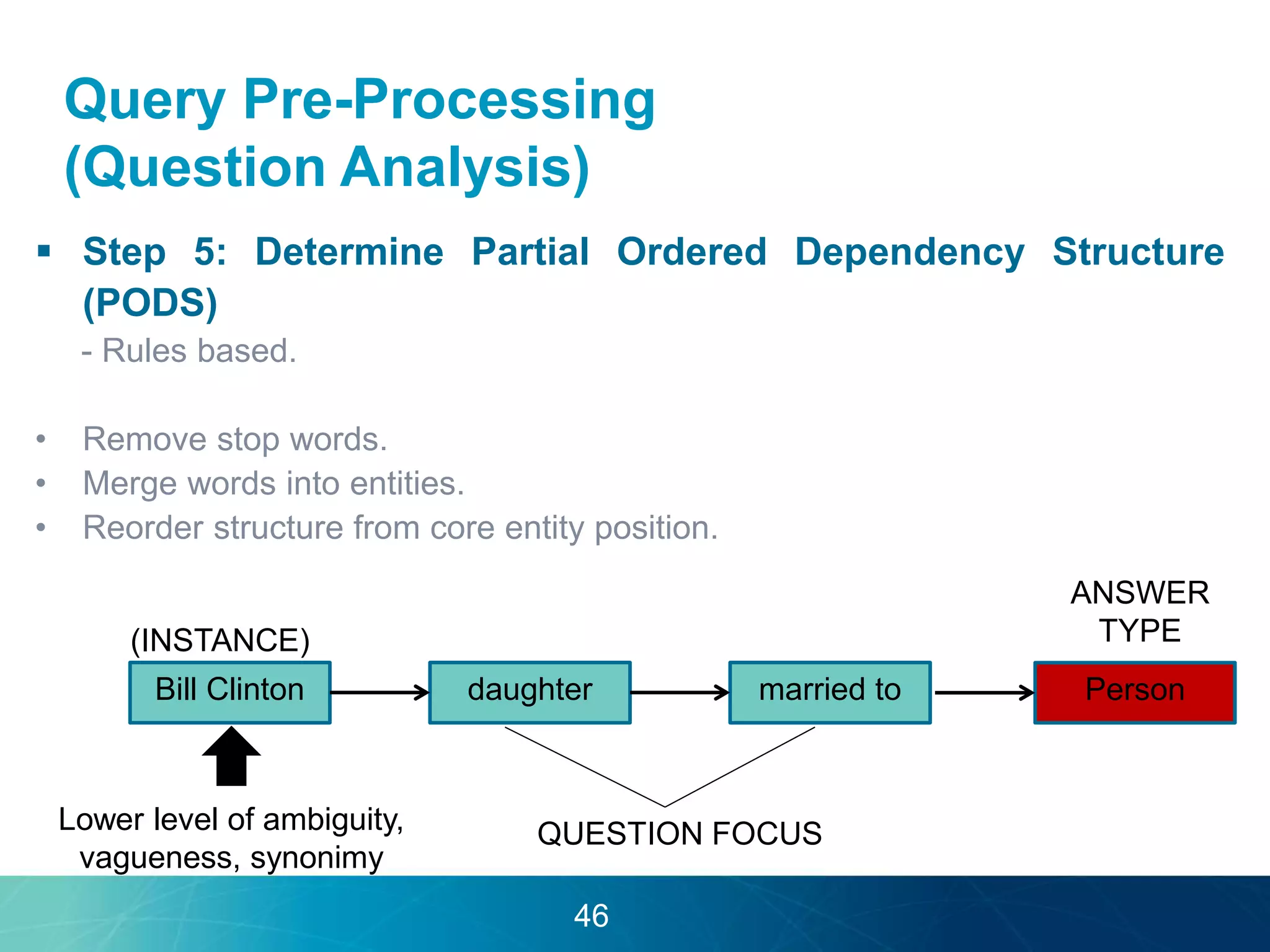
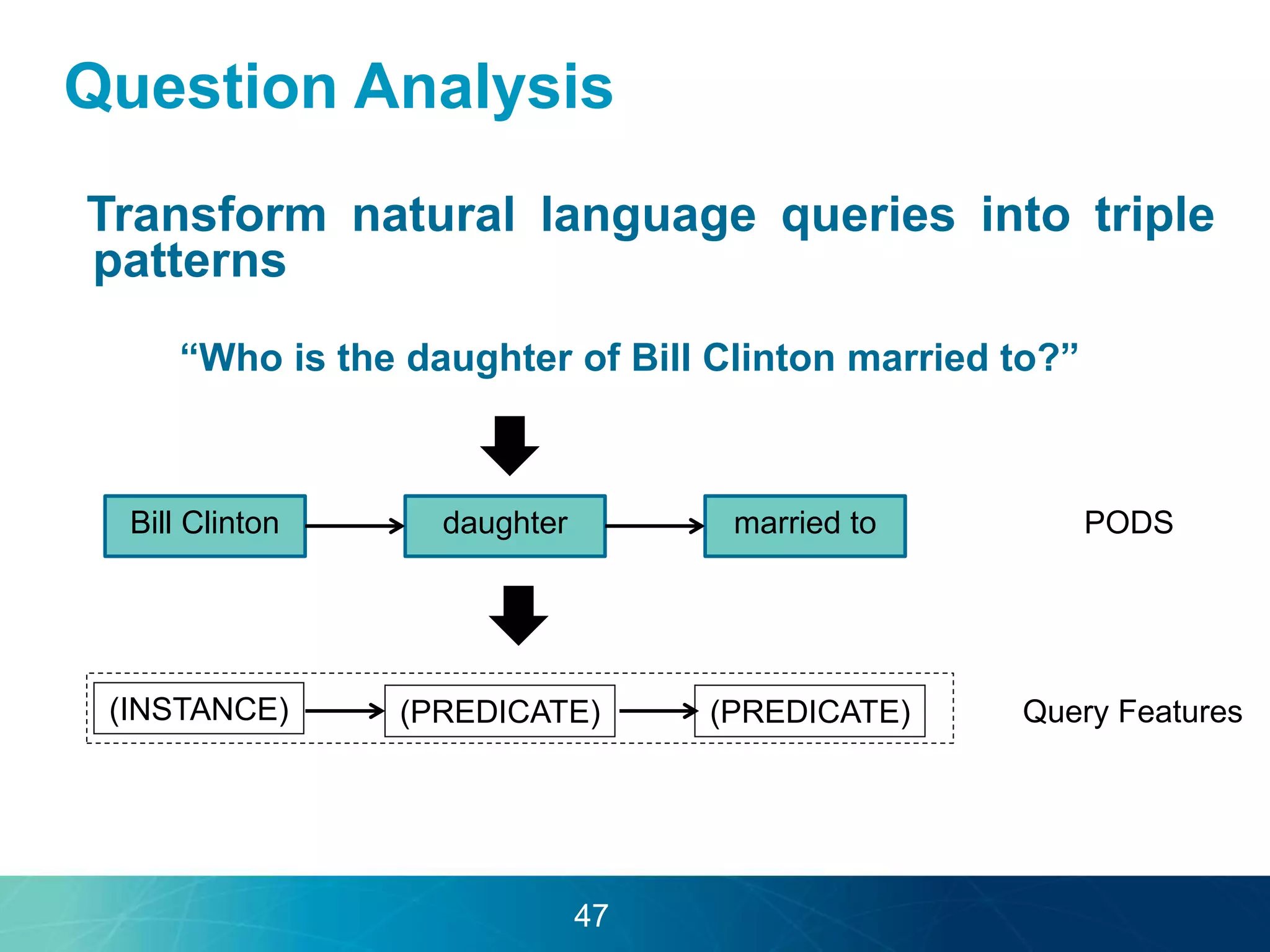
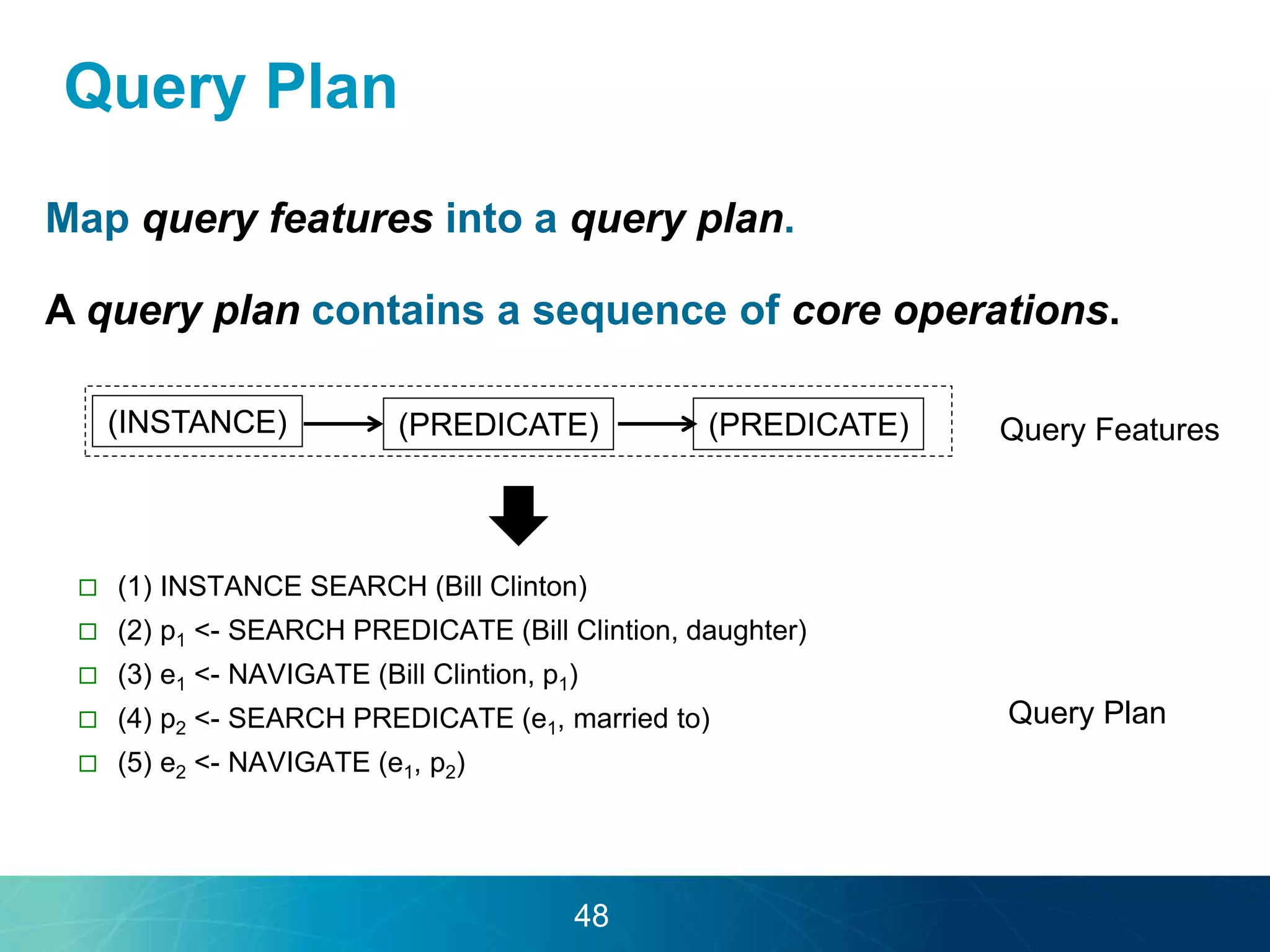
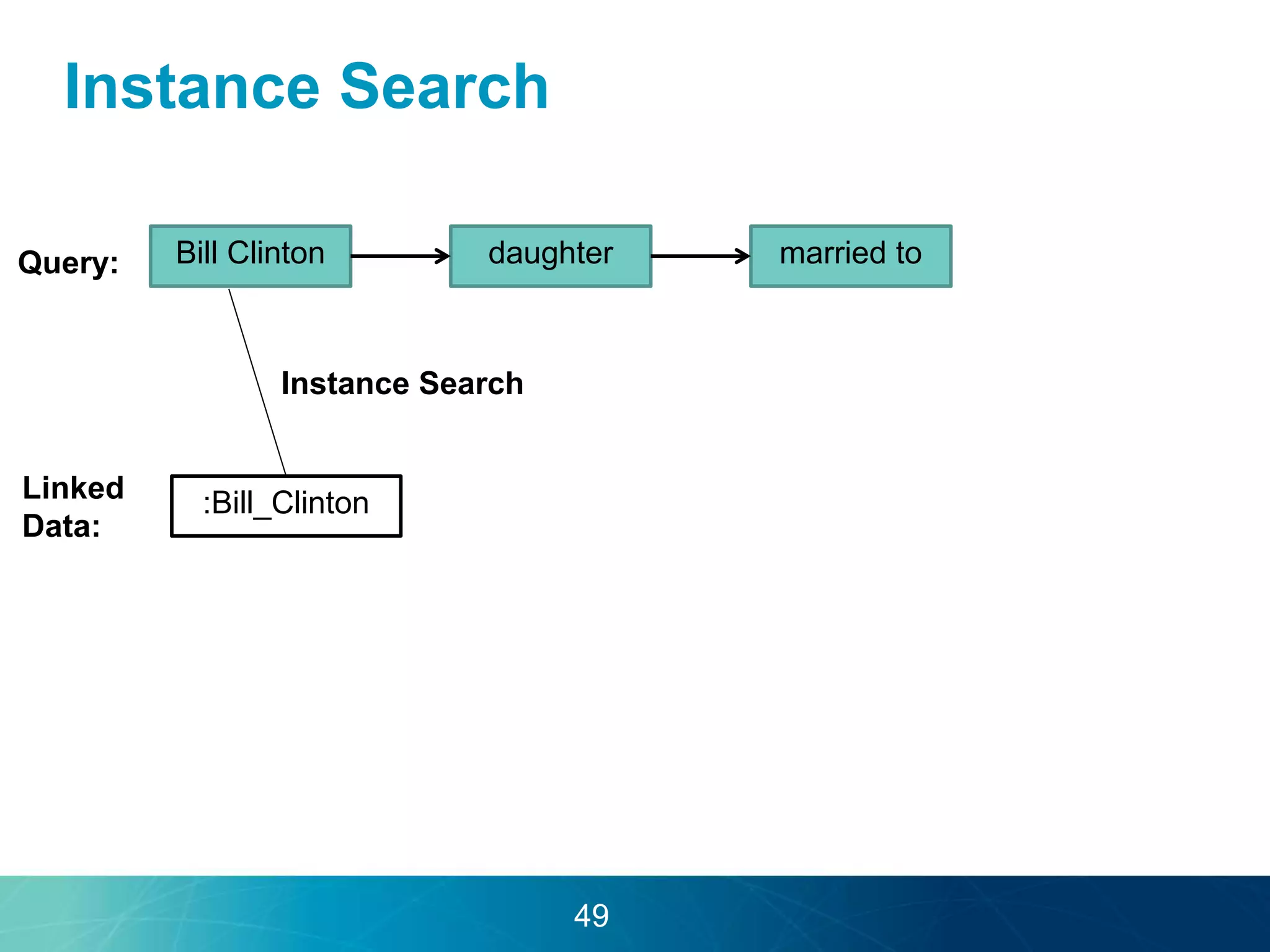
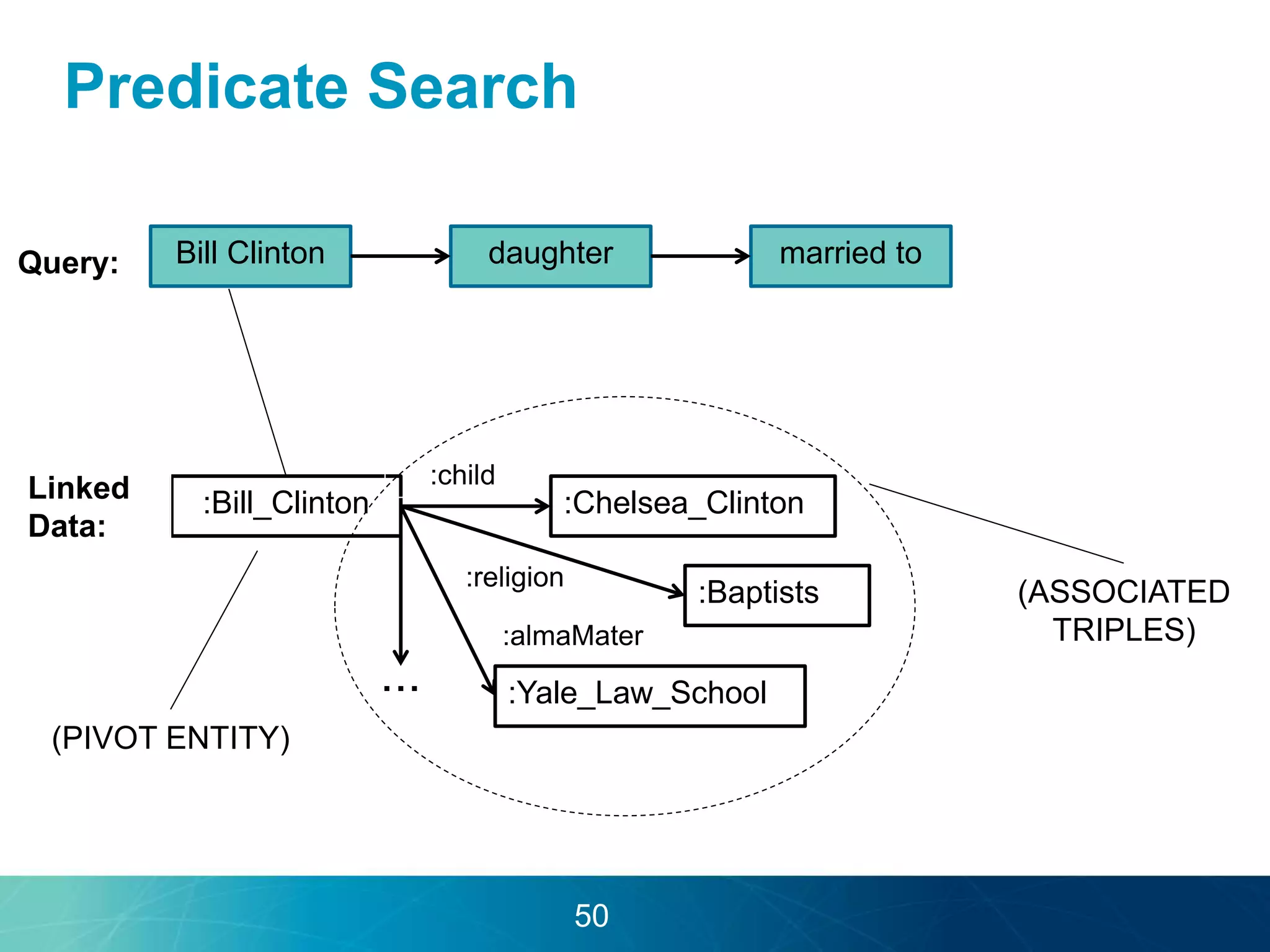
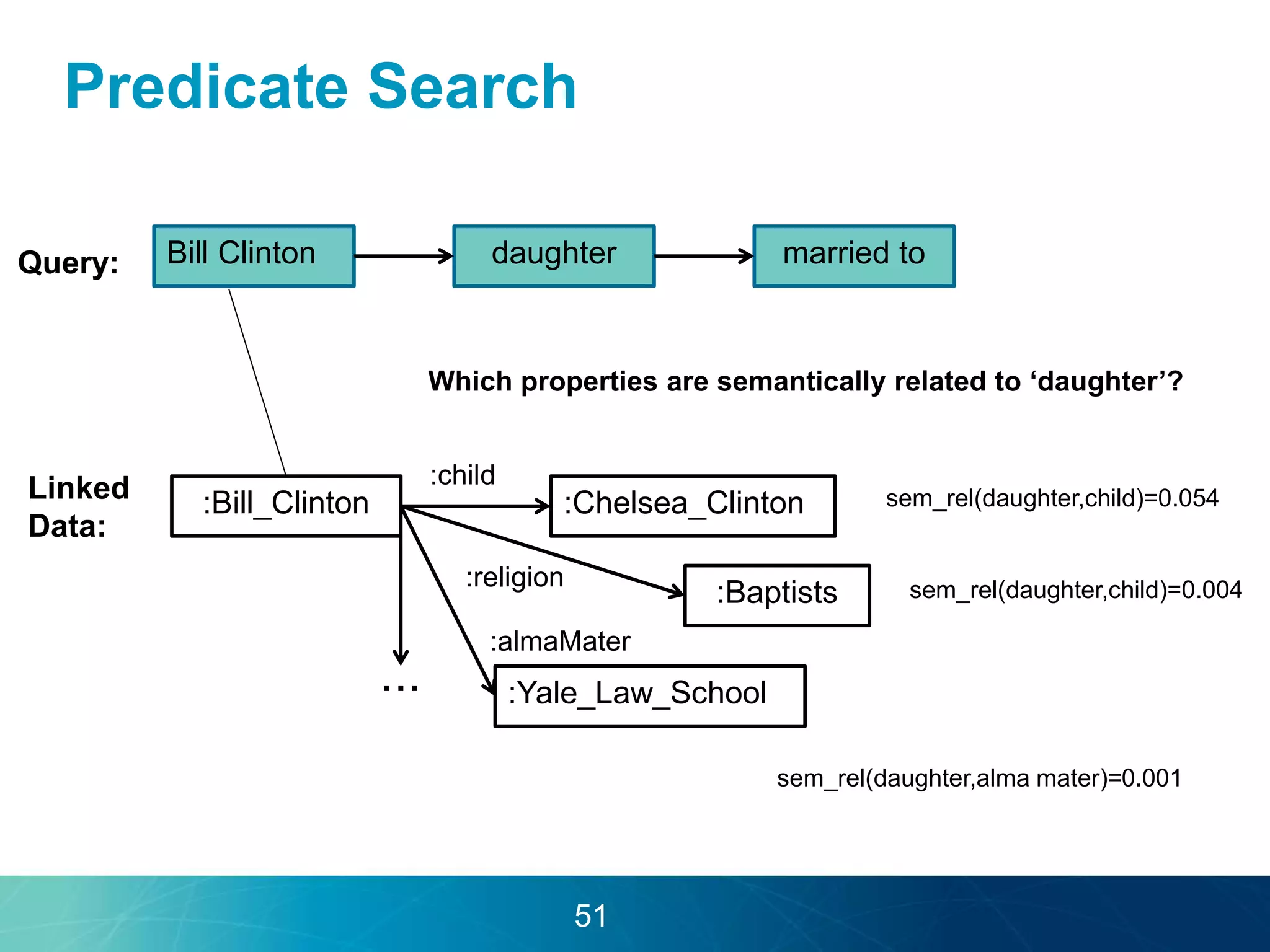
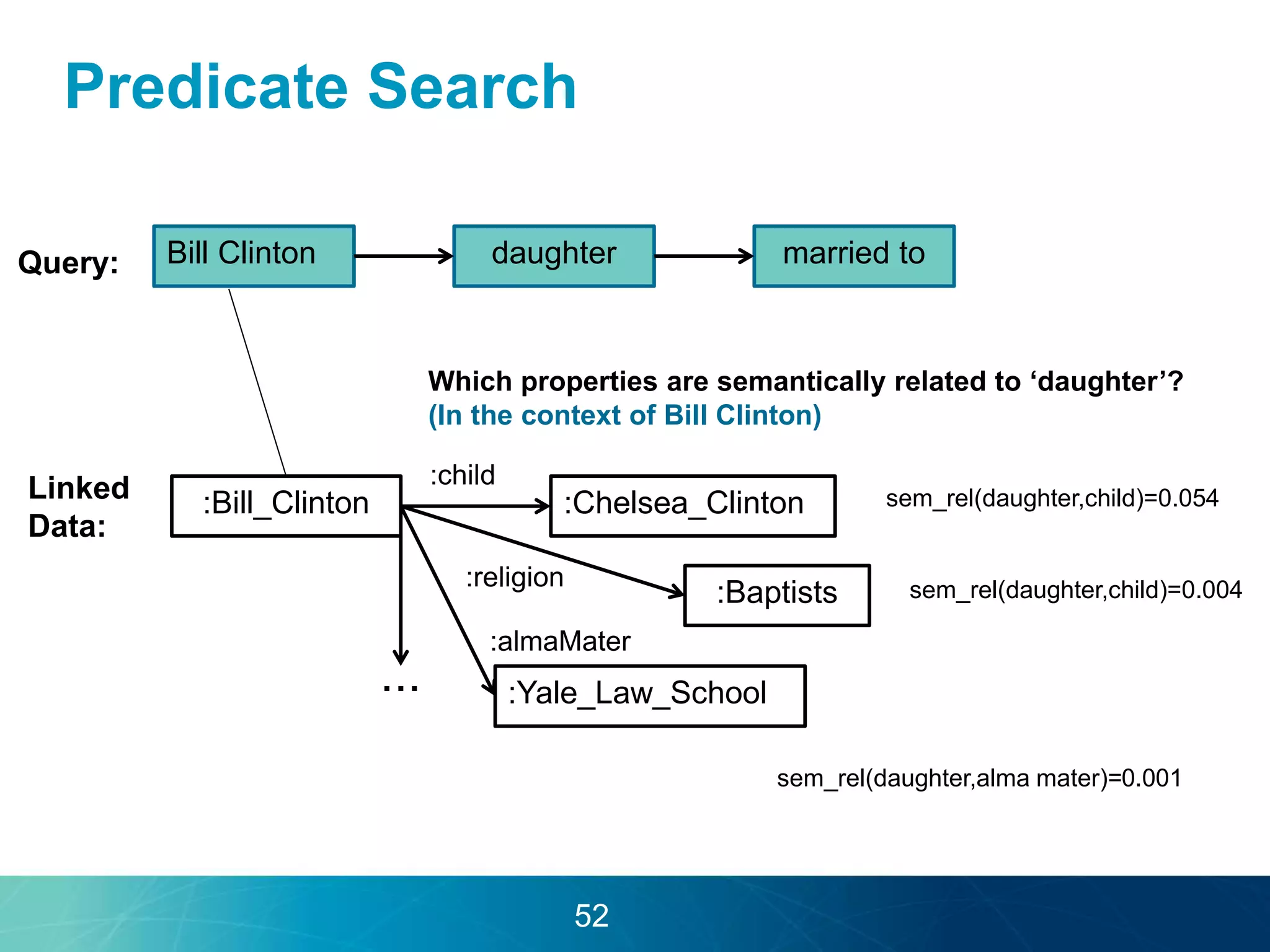
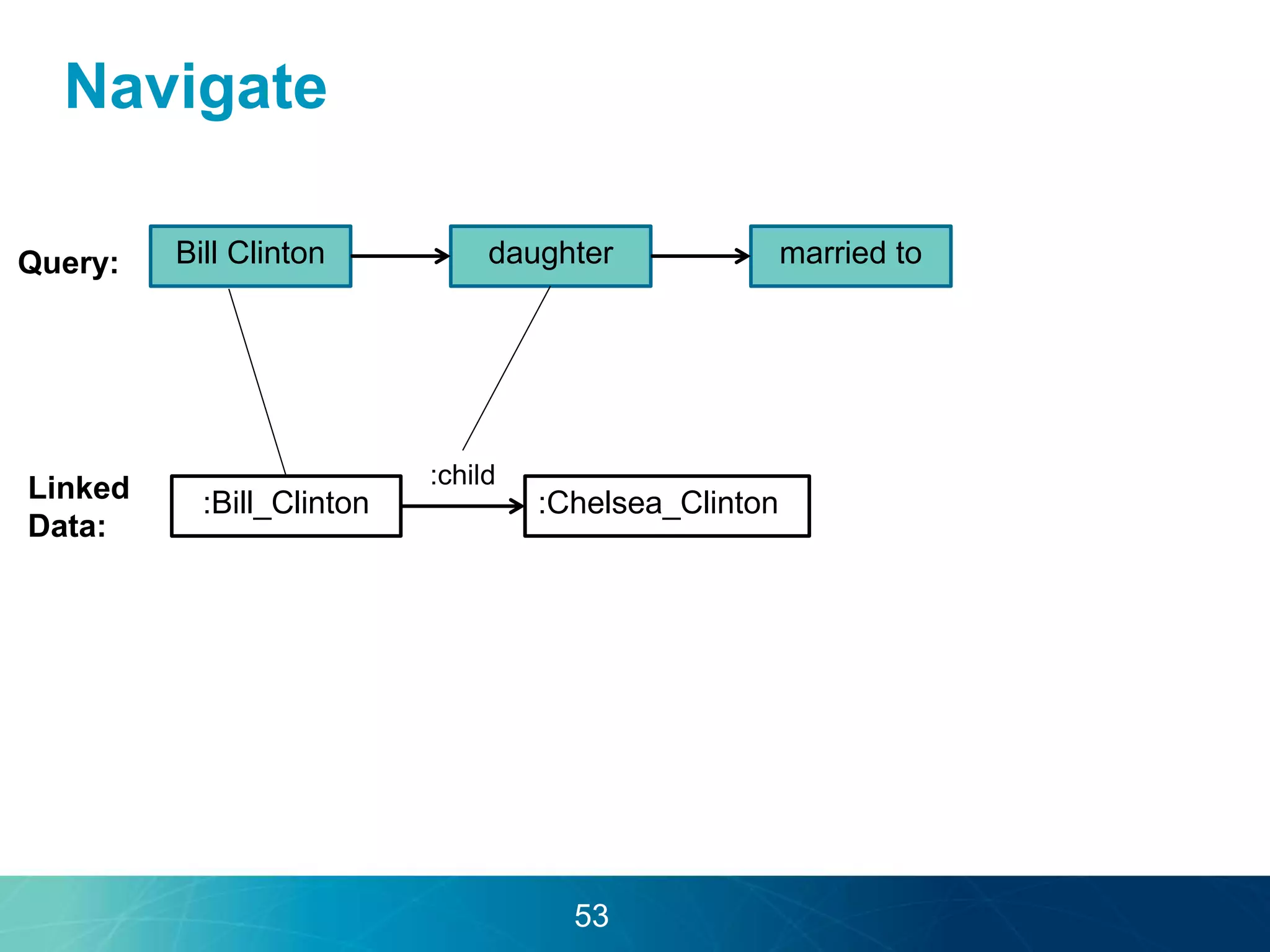
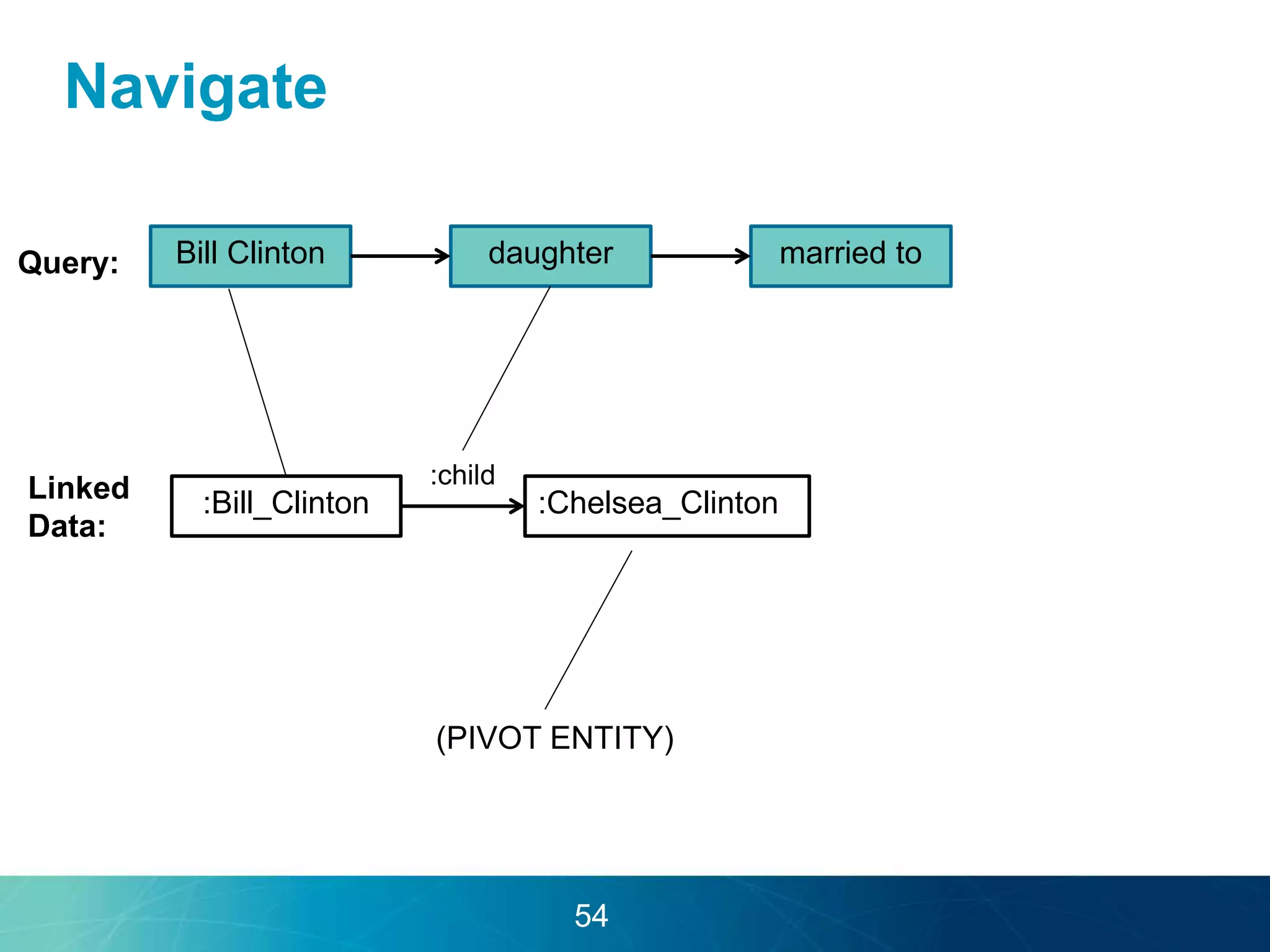
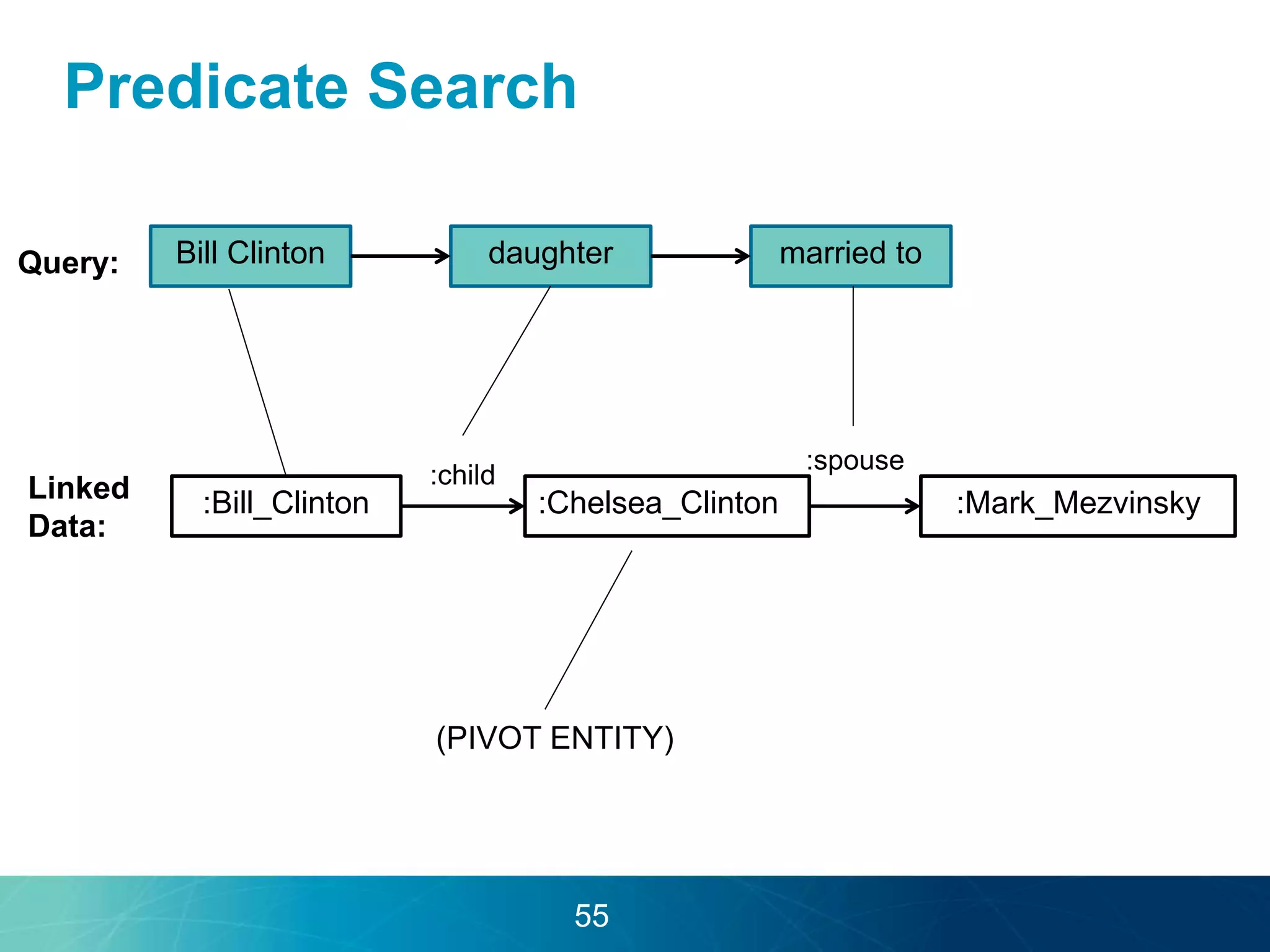





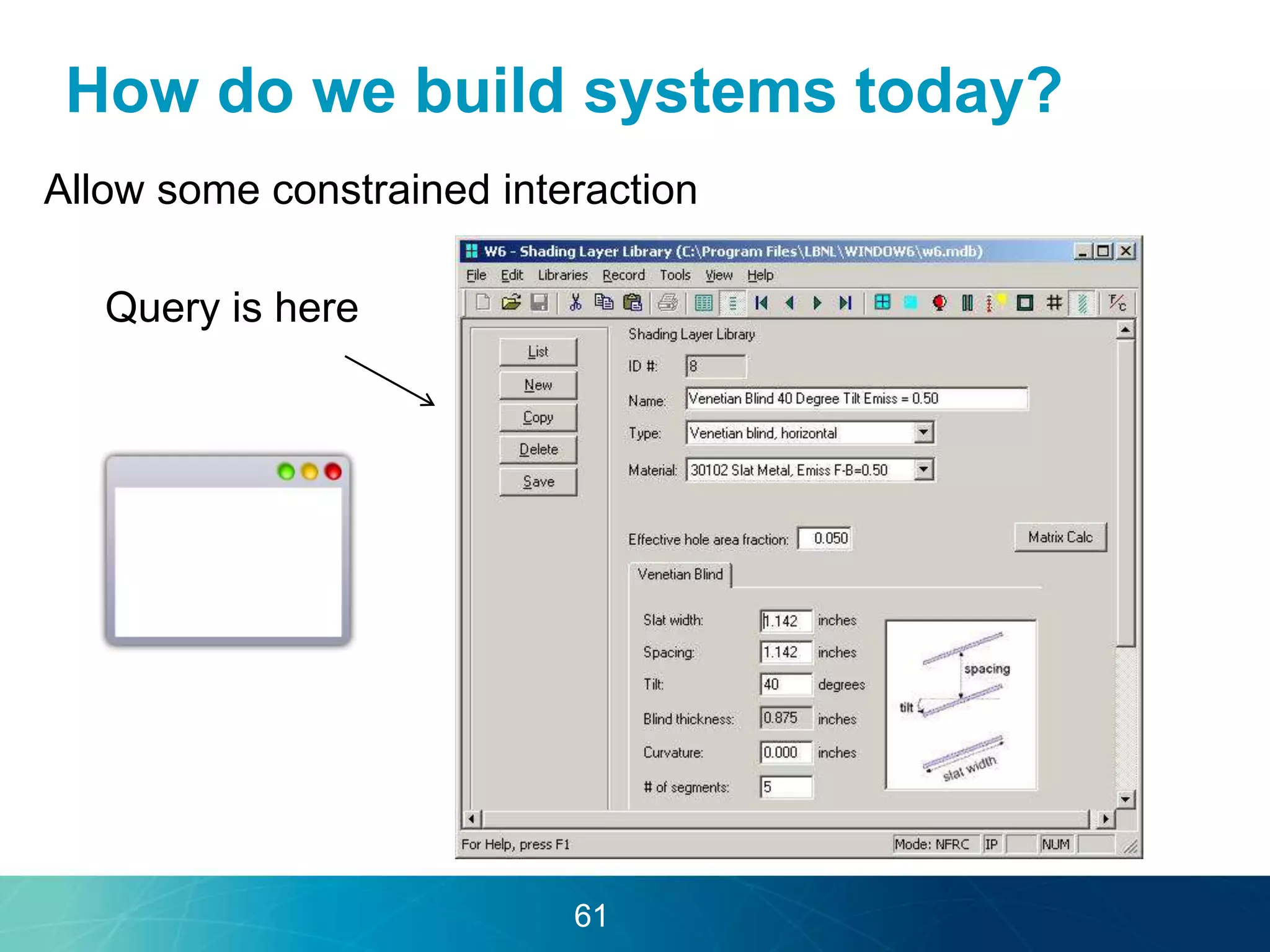

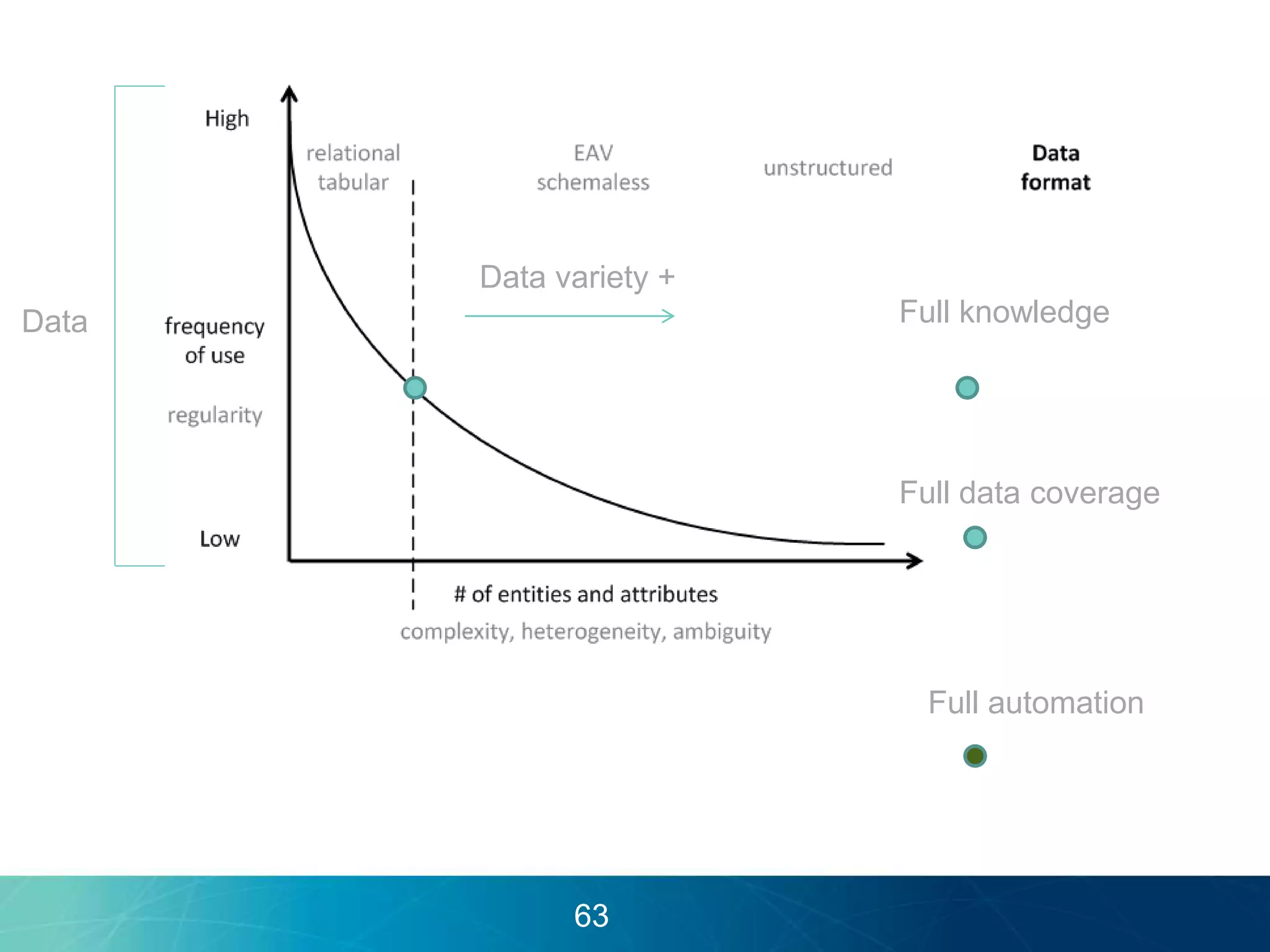
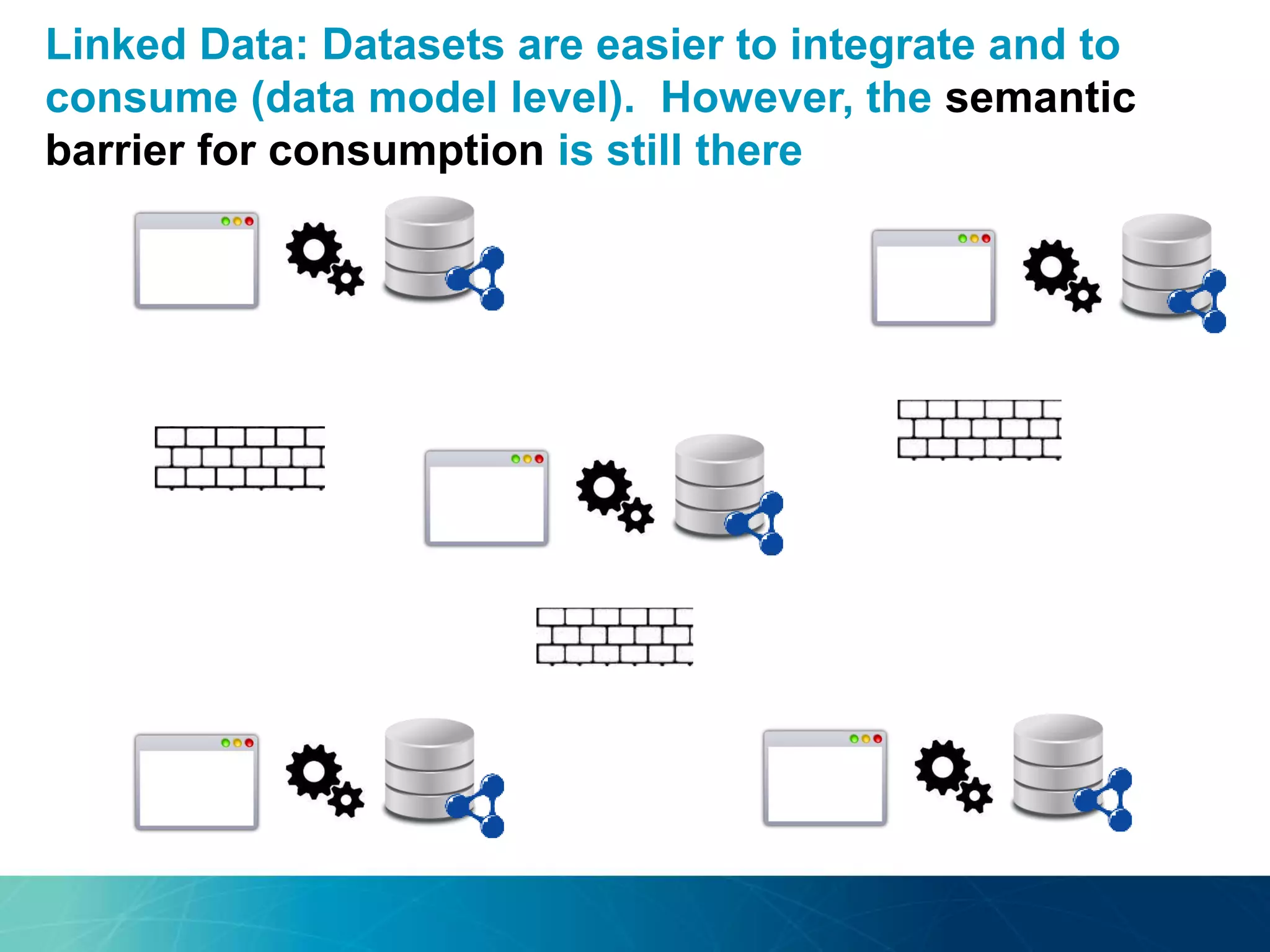
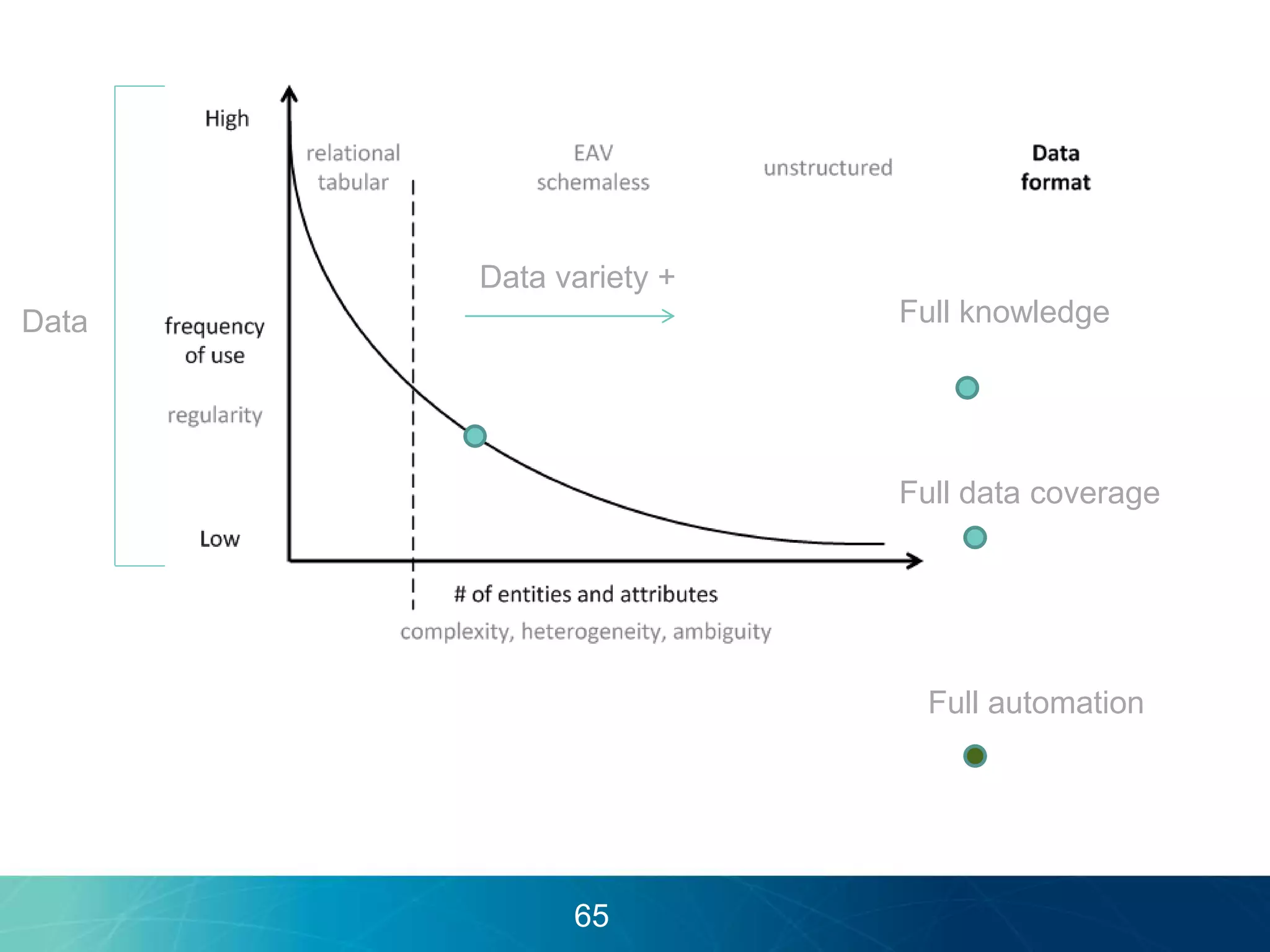
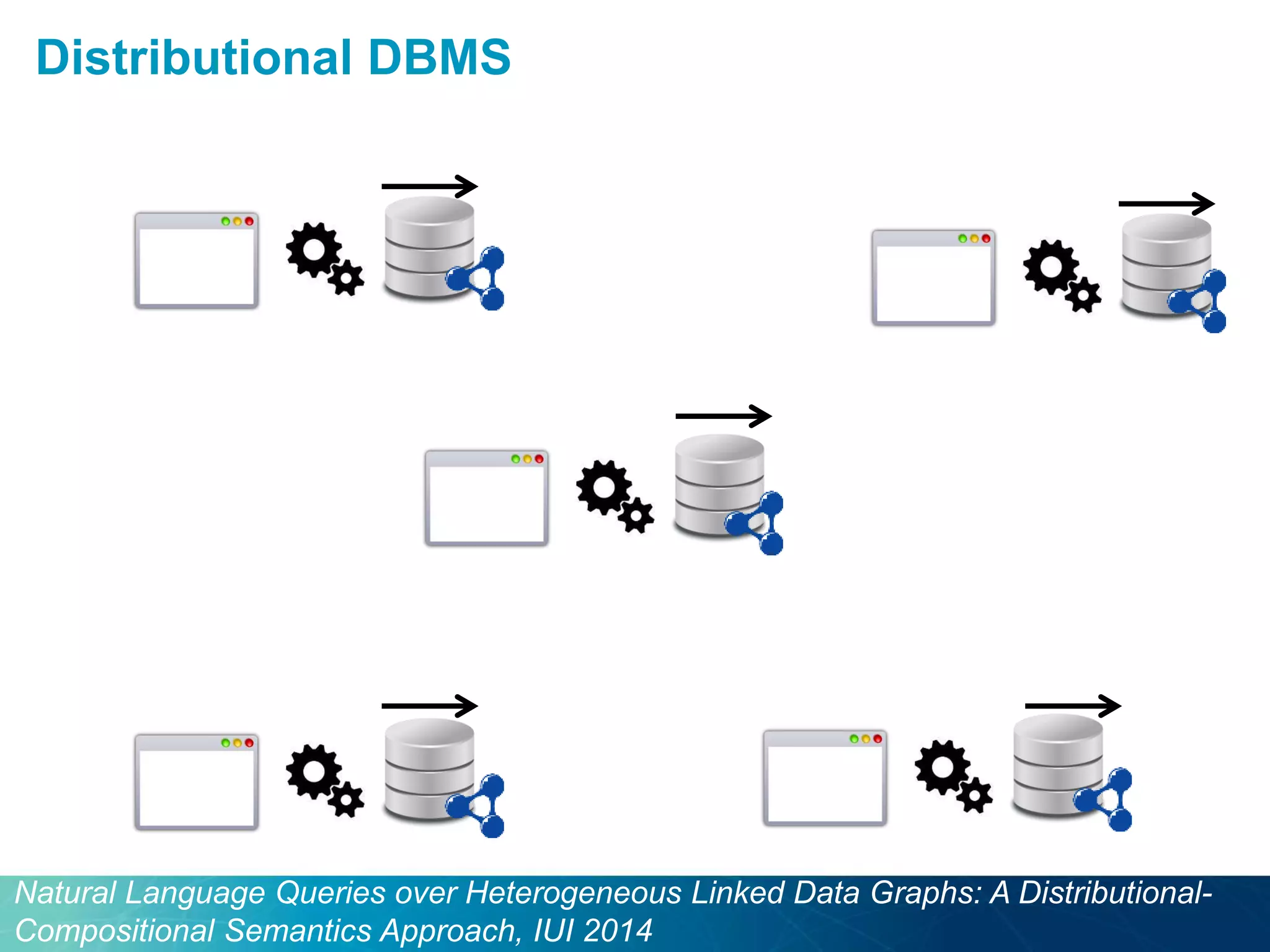
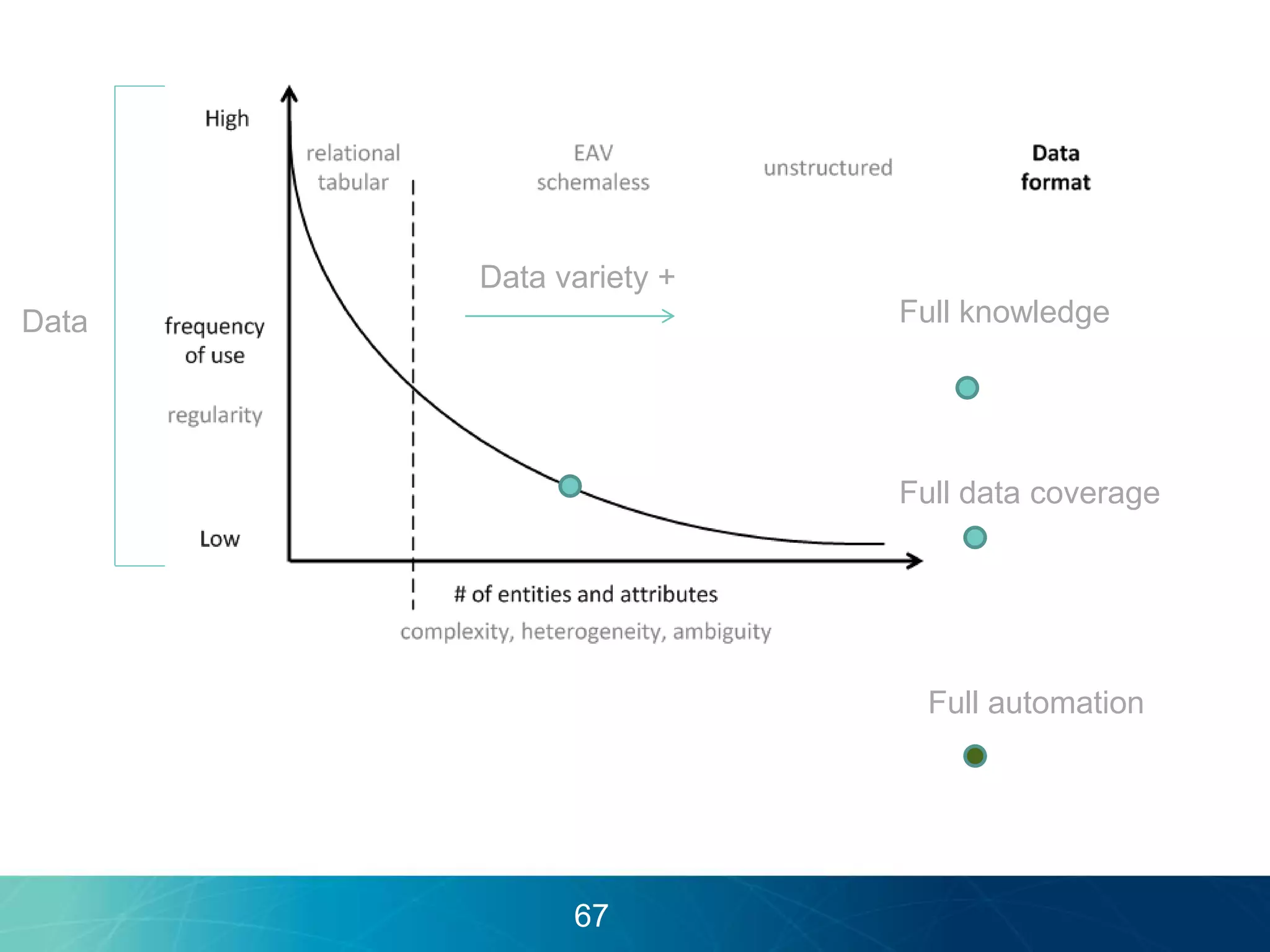

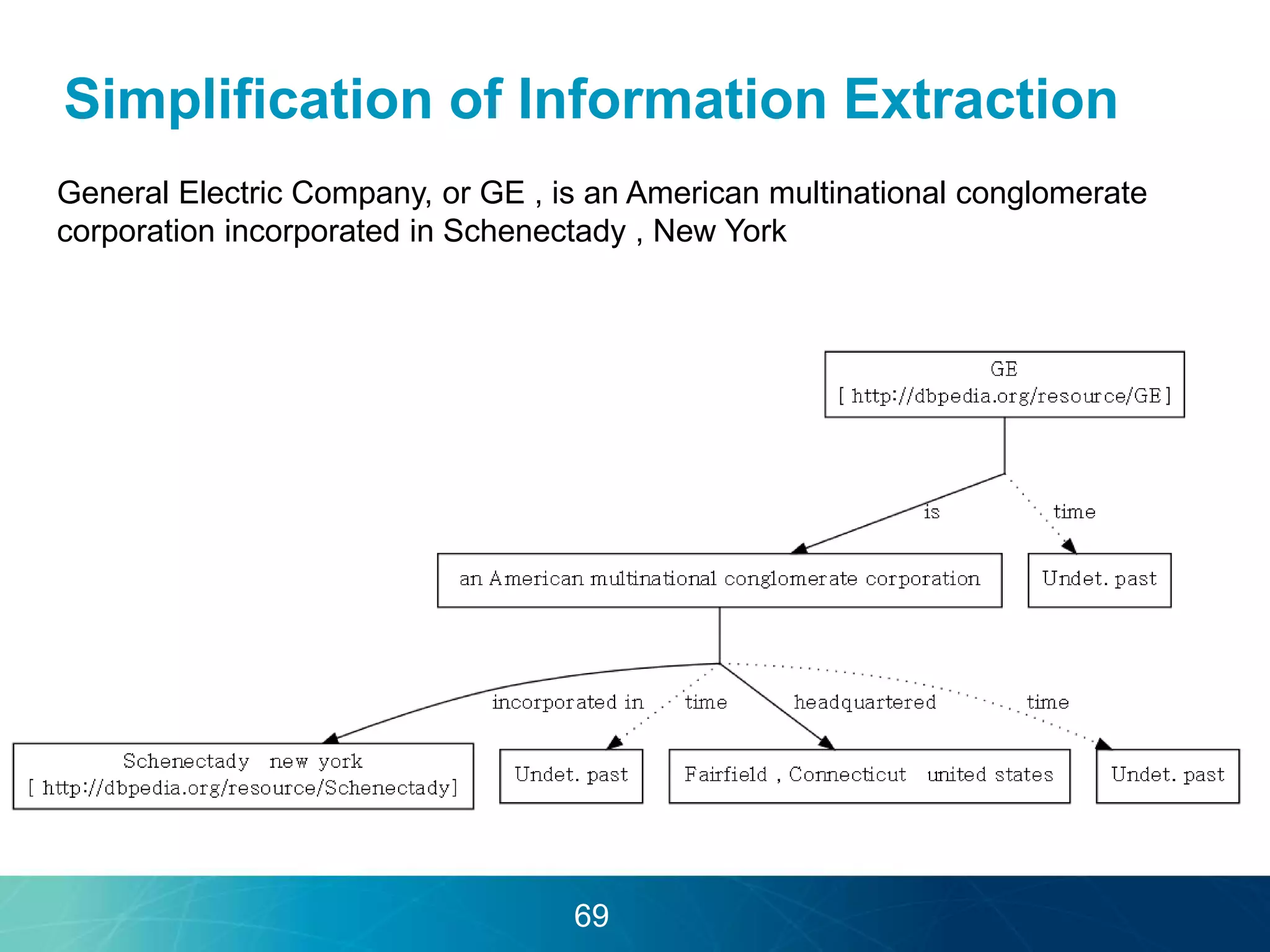
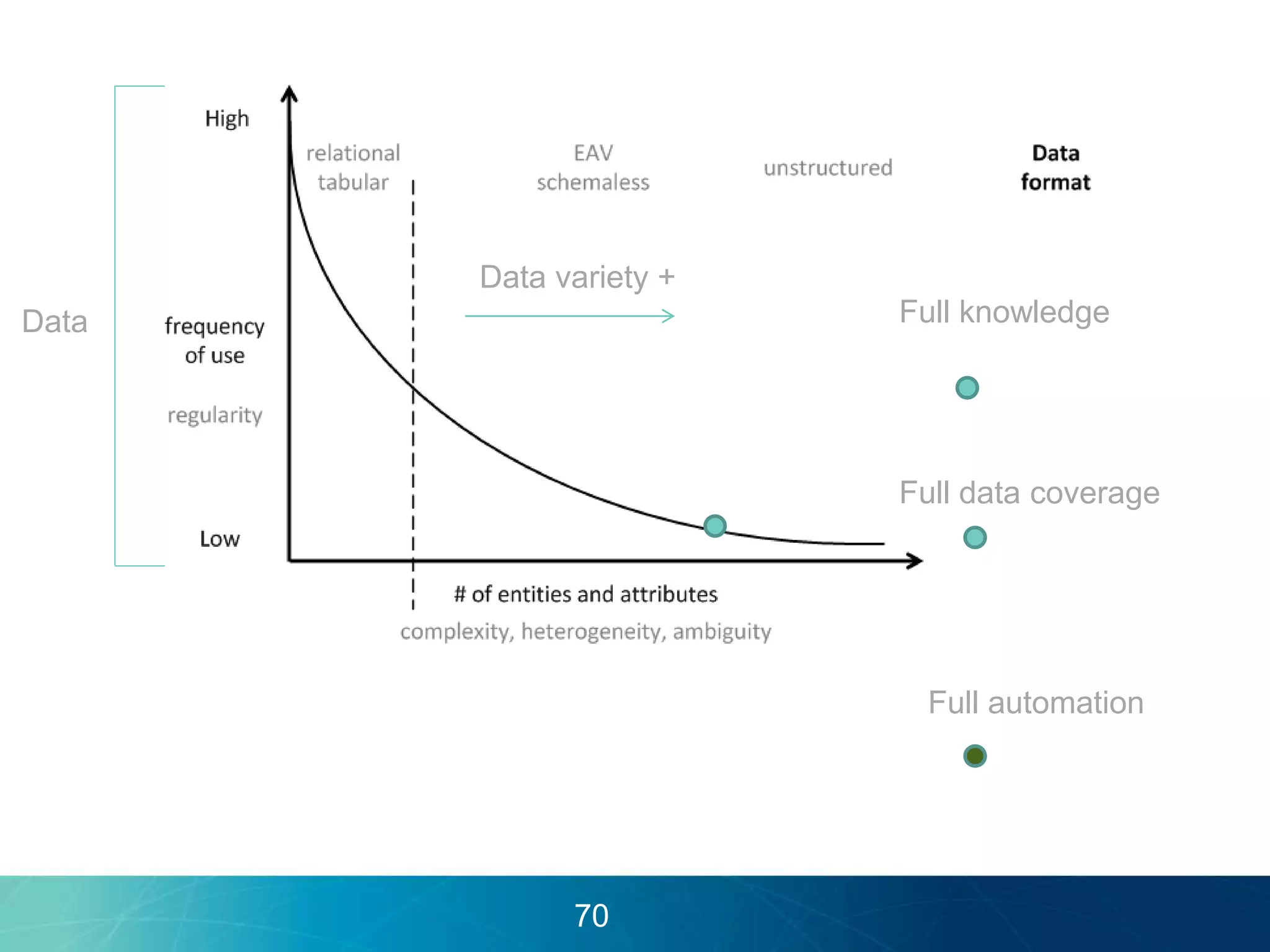
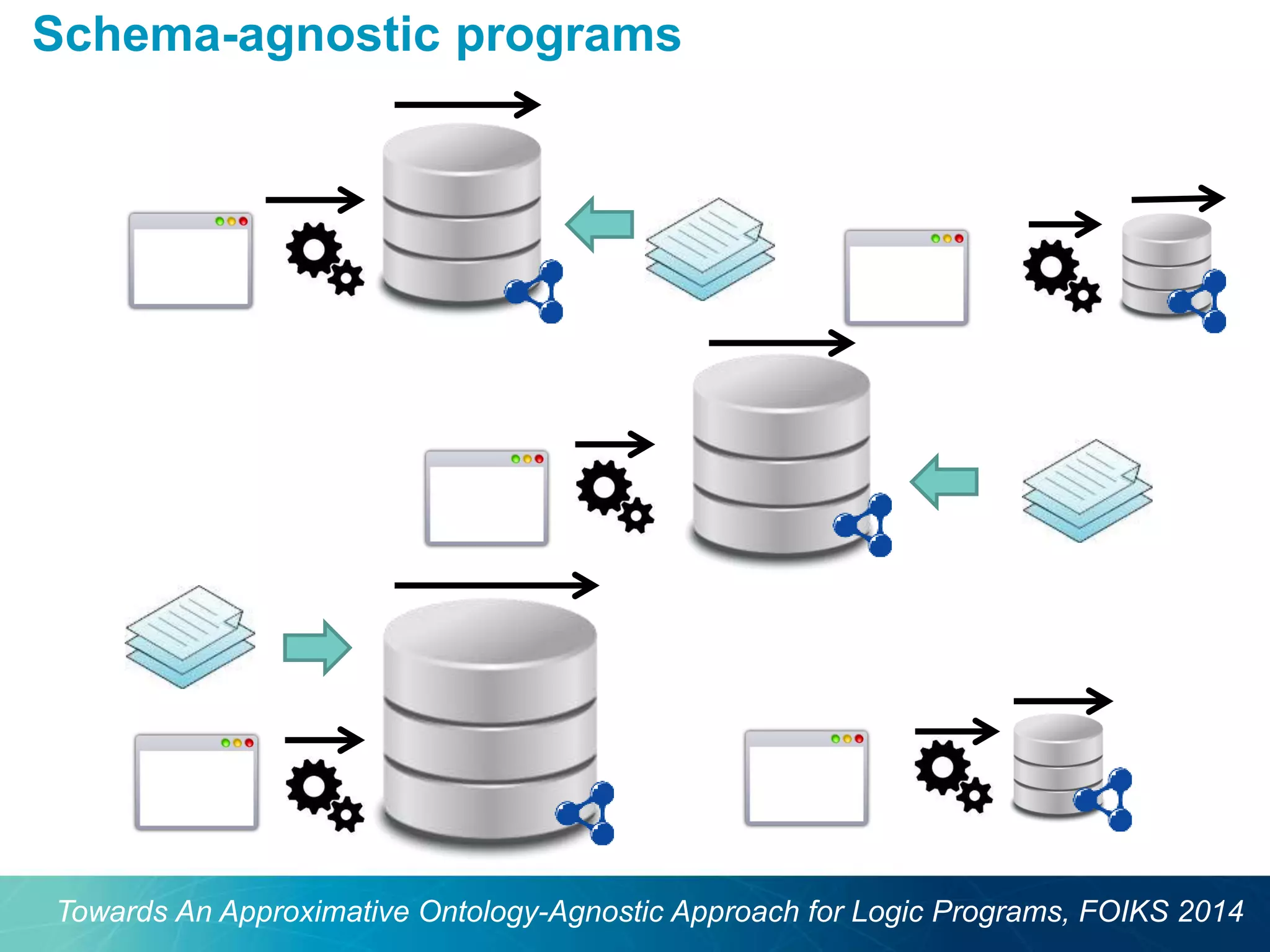
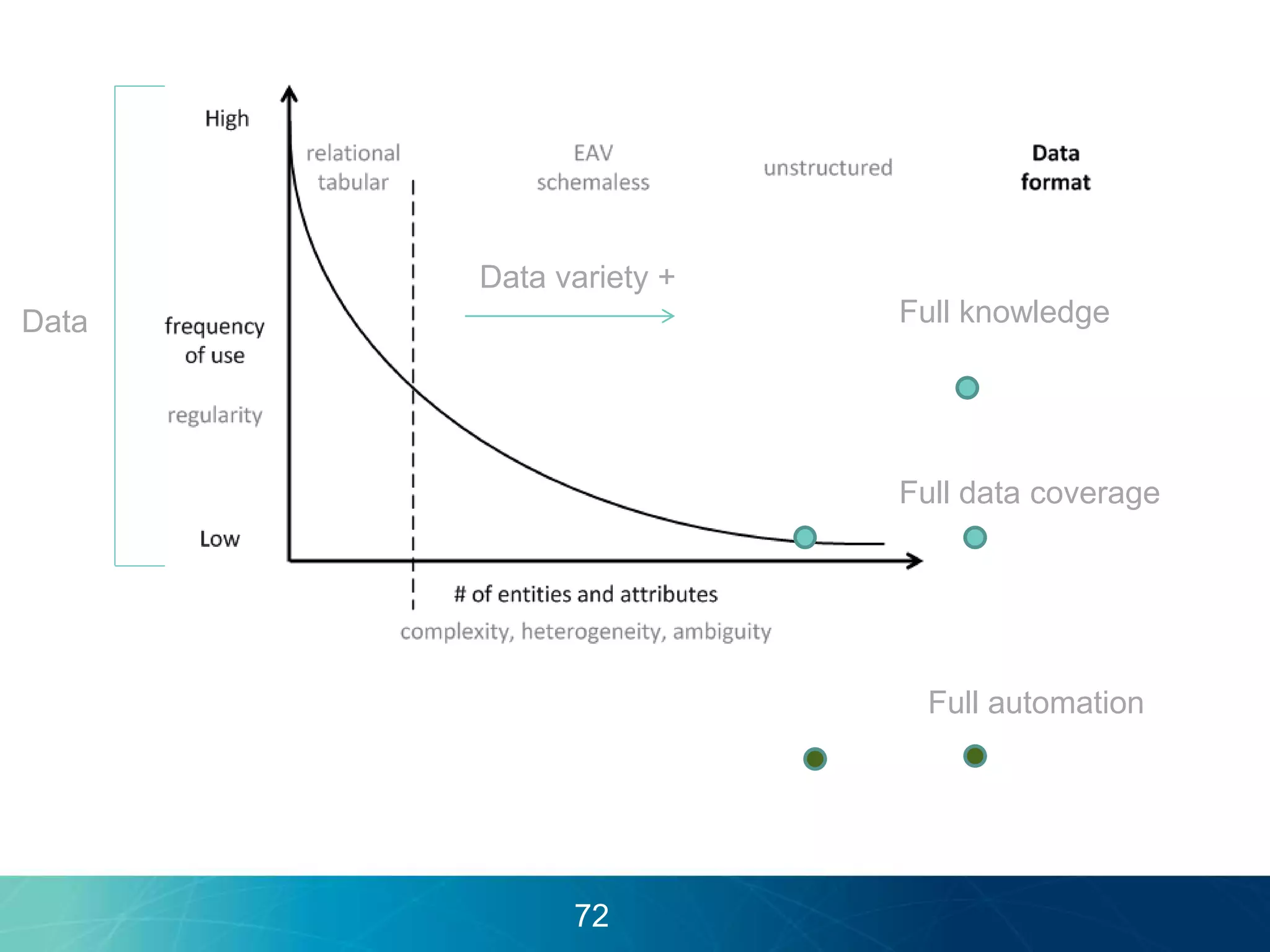
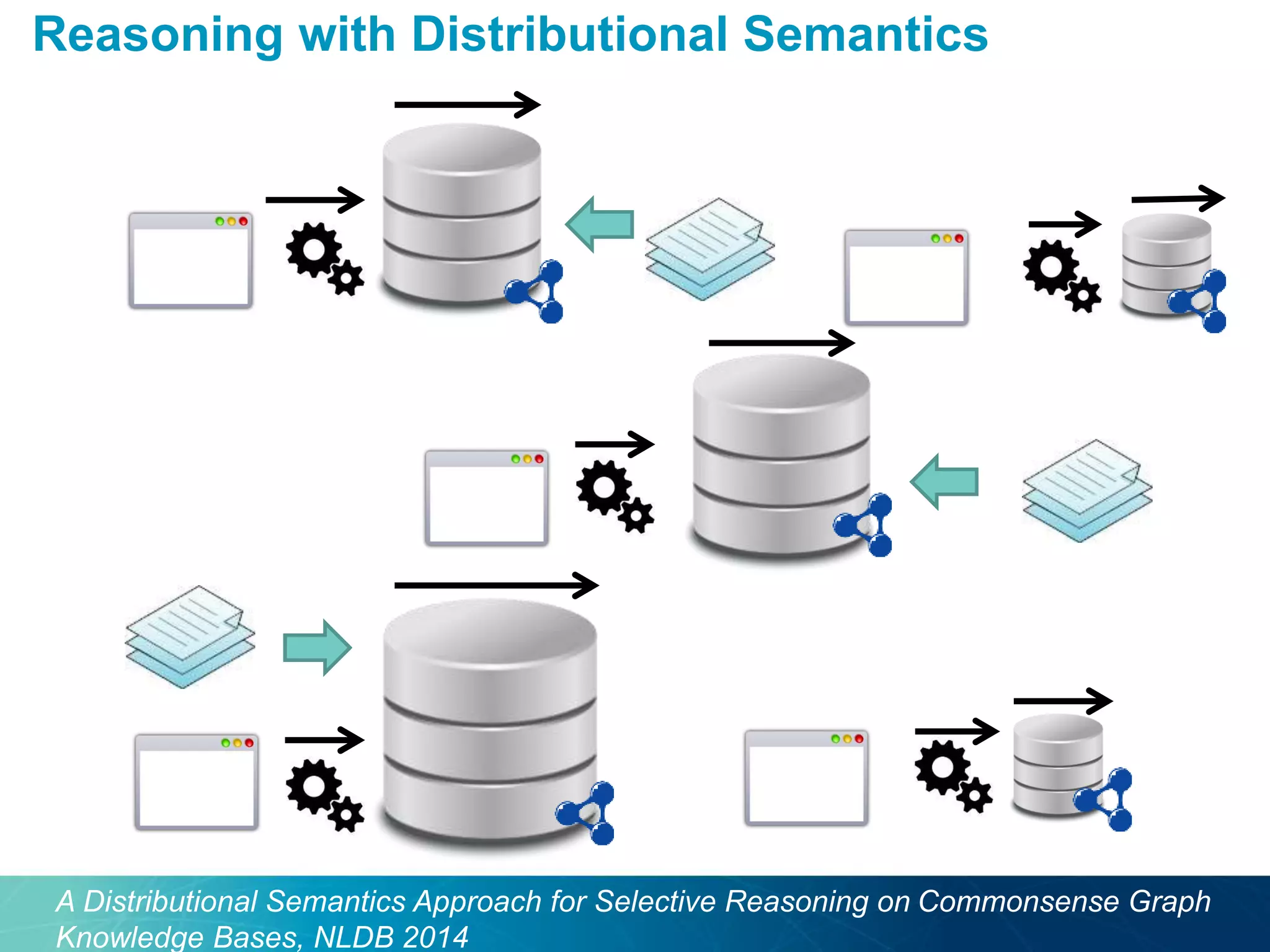
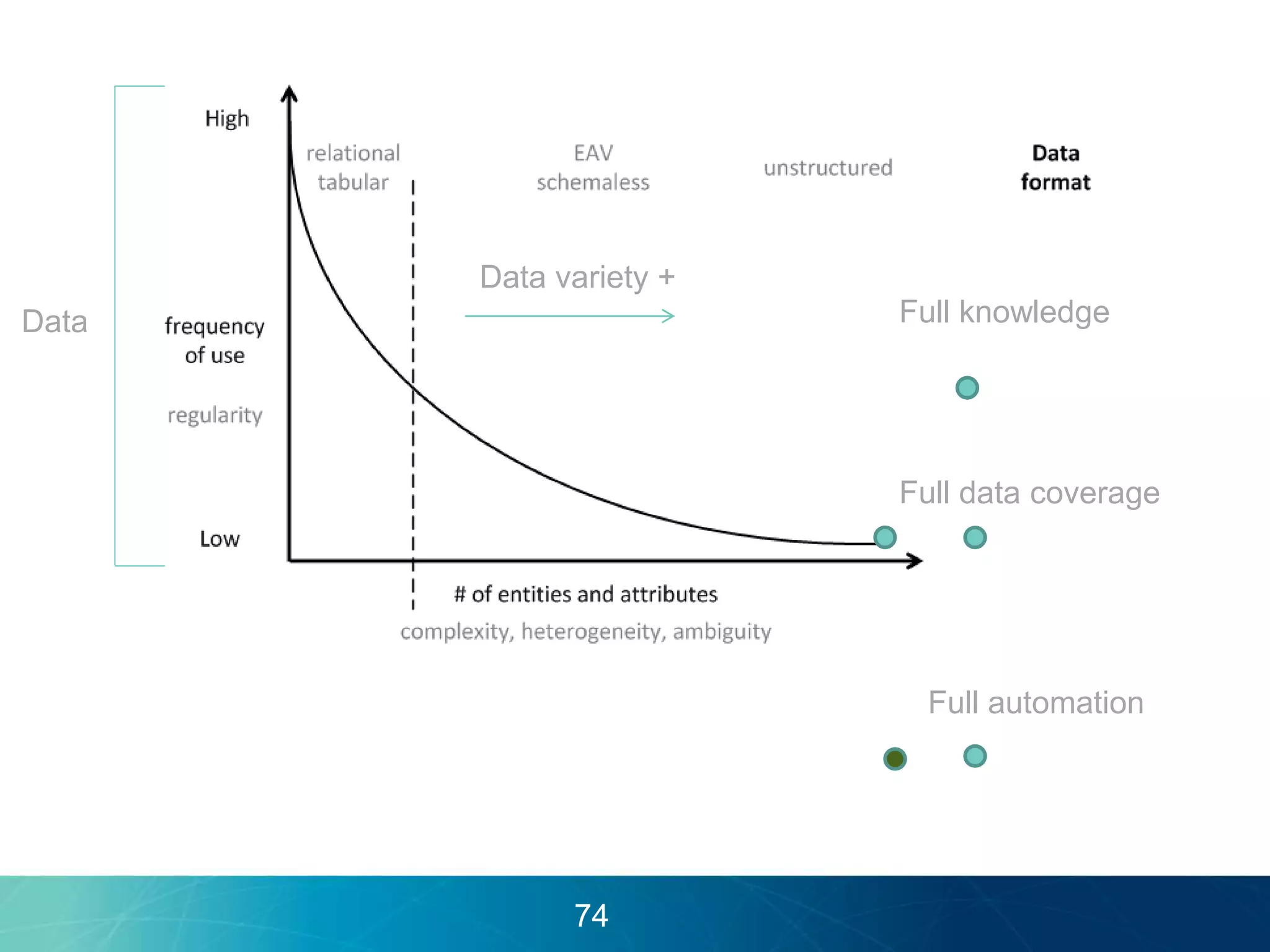




The document discusses the evolution of database technologies towards schema-agnosticism and the challenges posed by semantic heterogeneity in a schema-less world. It highlights the role of distributional semantic models in querying complex, unstructured data through natural language interfaces, with a case study of the Treo QA system as an example. The takeaway emphasizes that existing semantic technologies can address major data management issues, with schema-agnosticism serving as a key approach in leveraging the variety and complexity of data.















































![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)









![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




