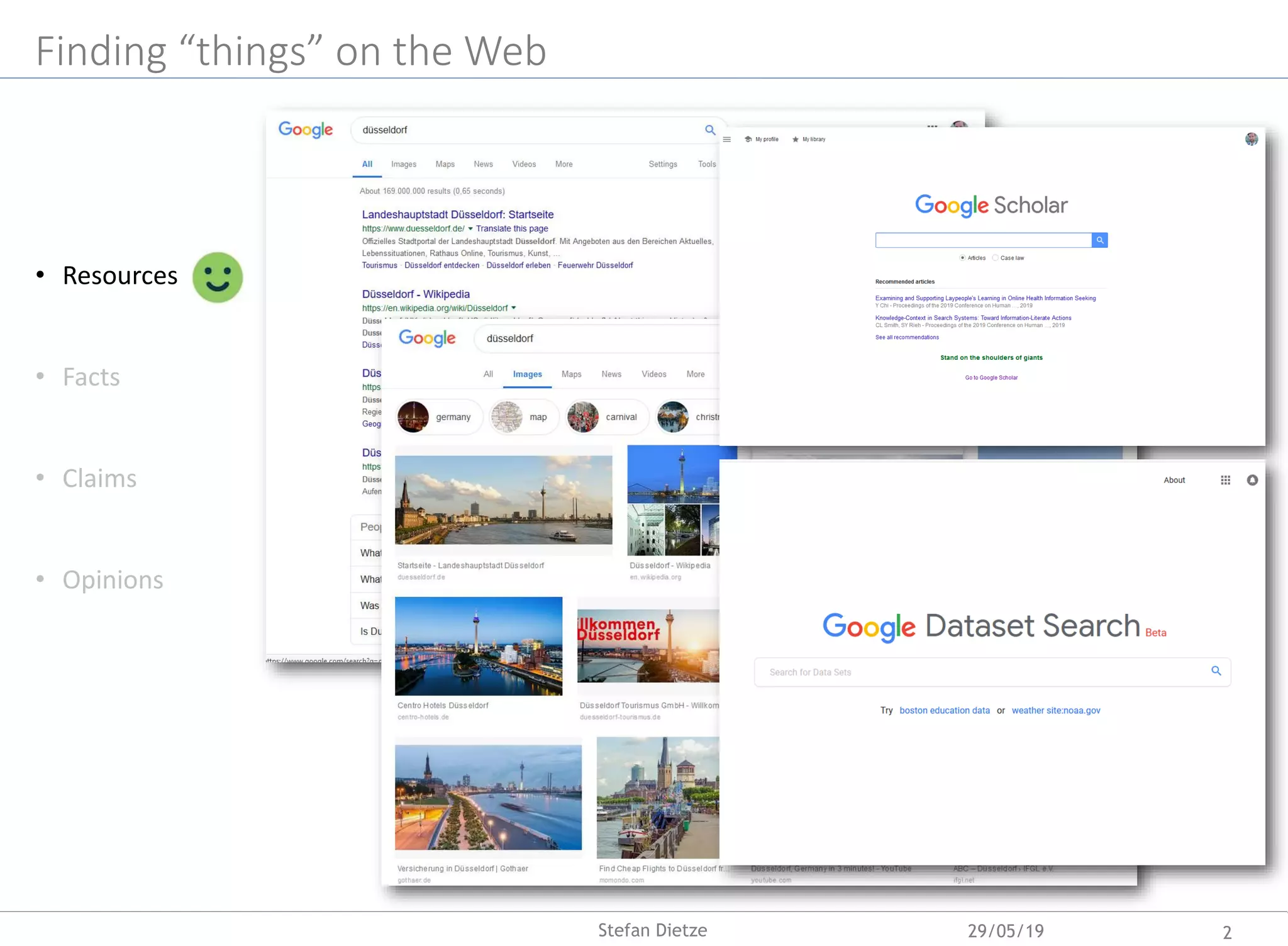
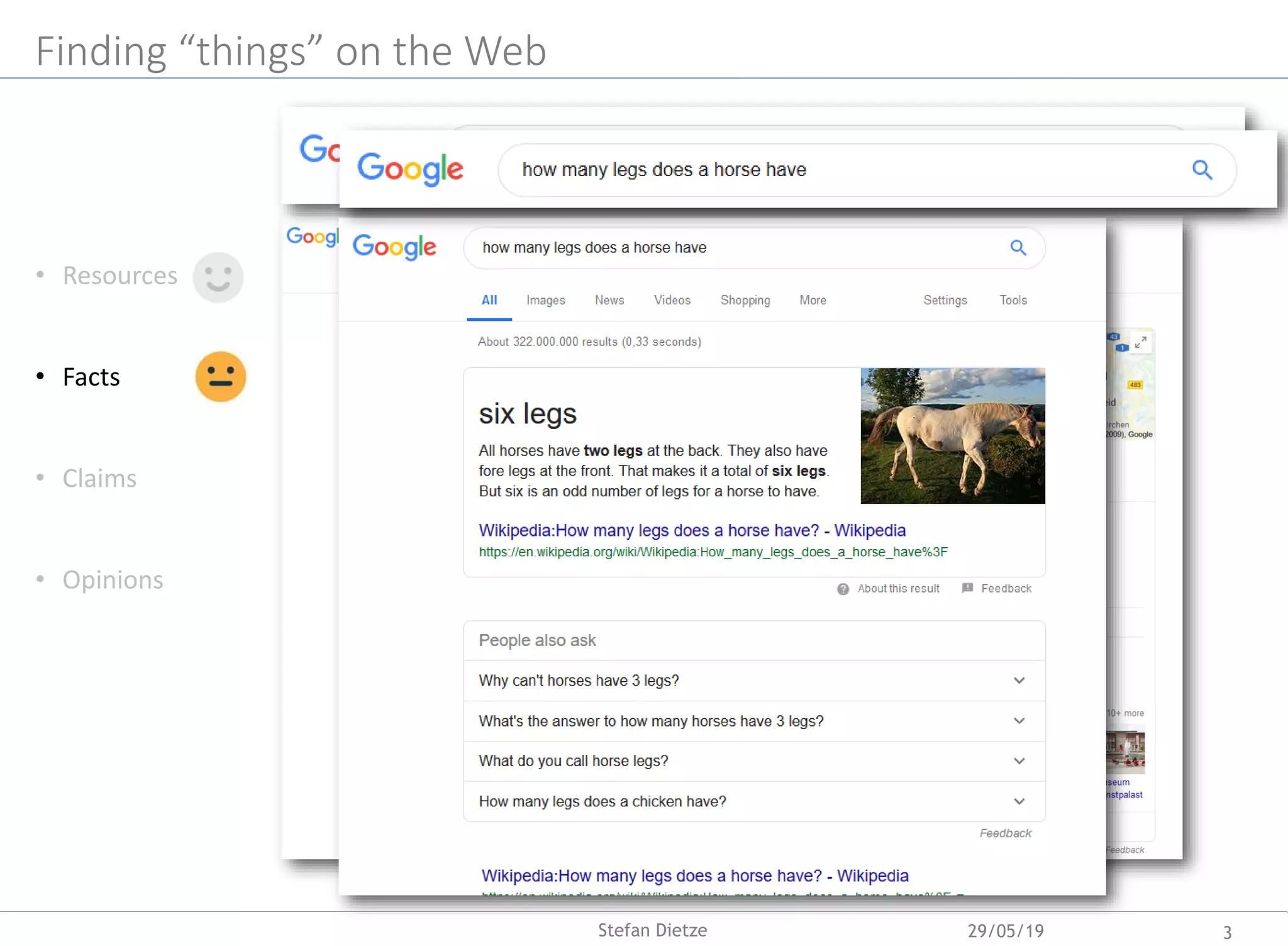
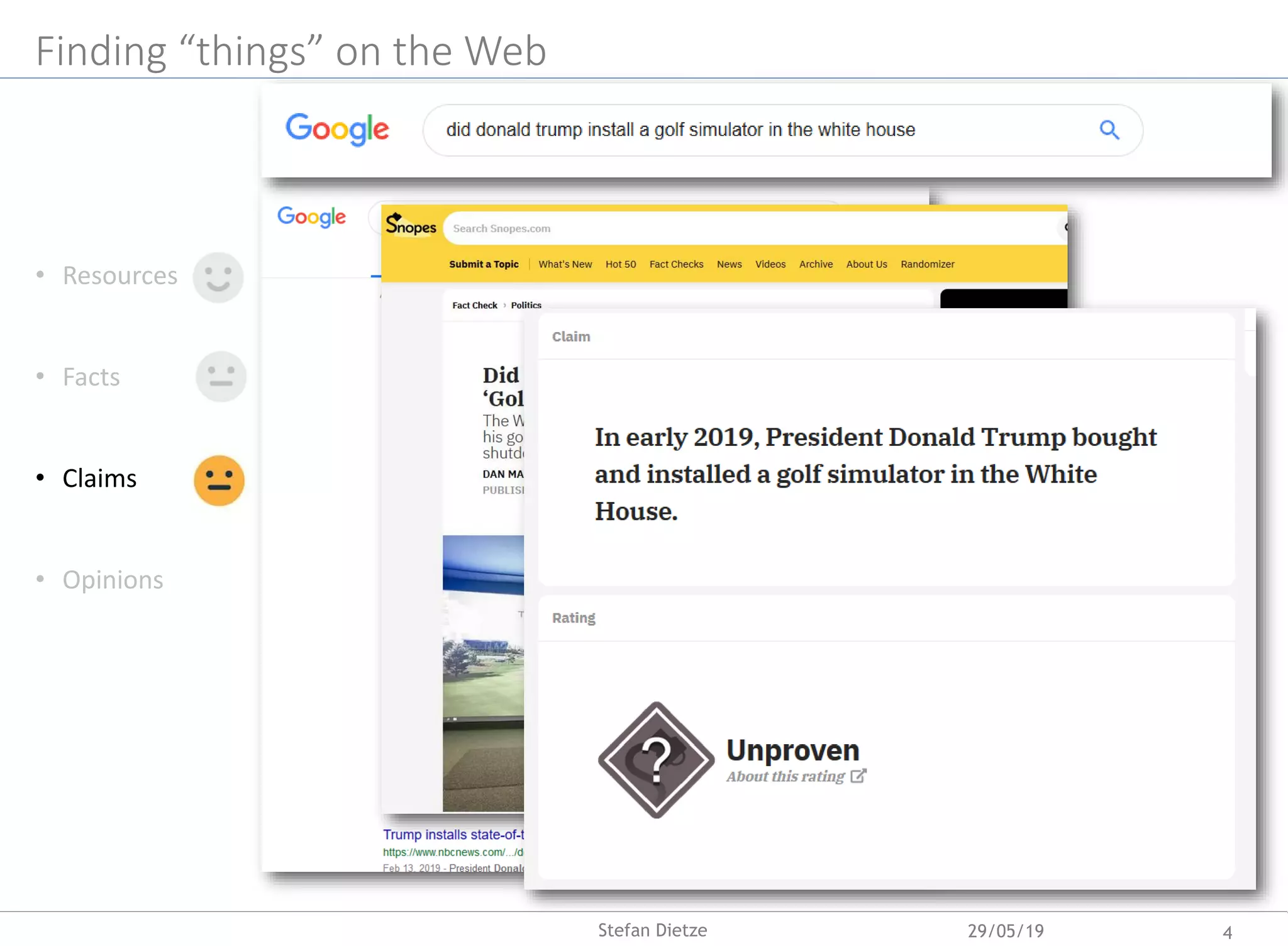
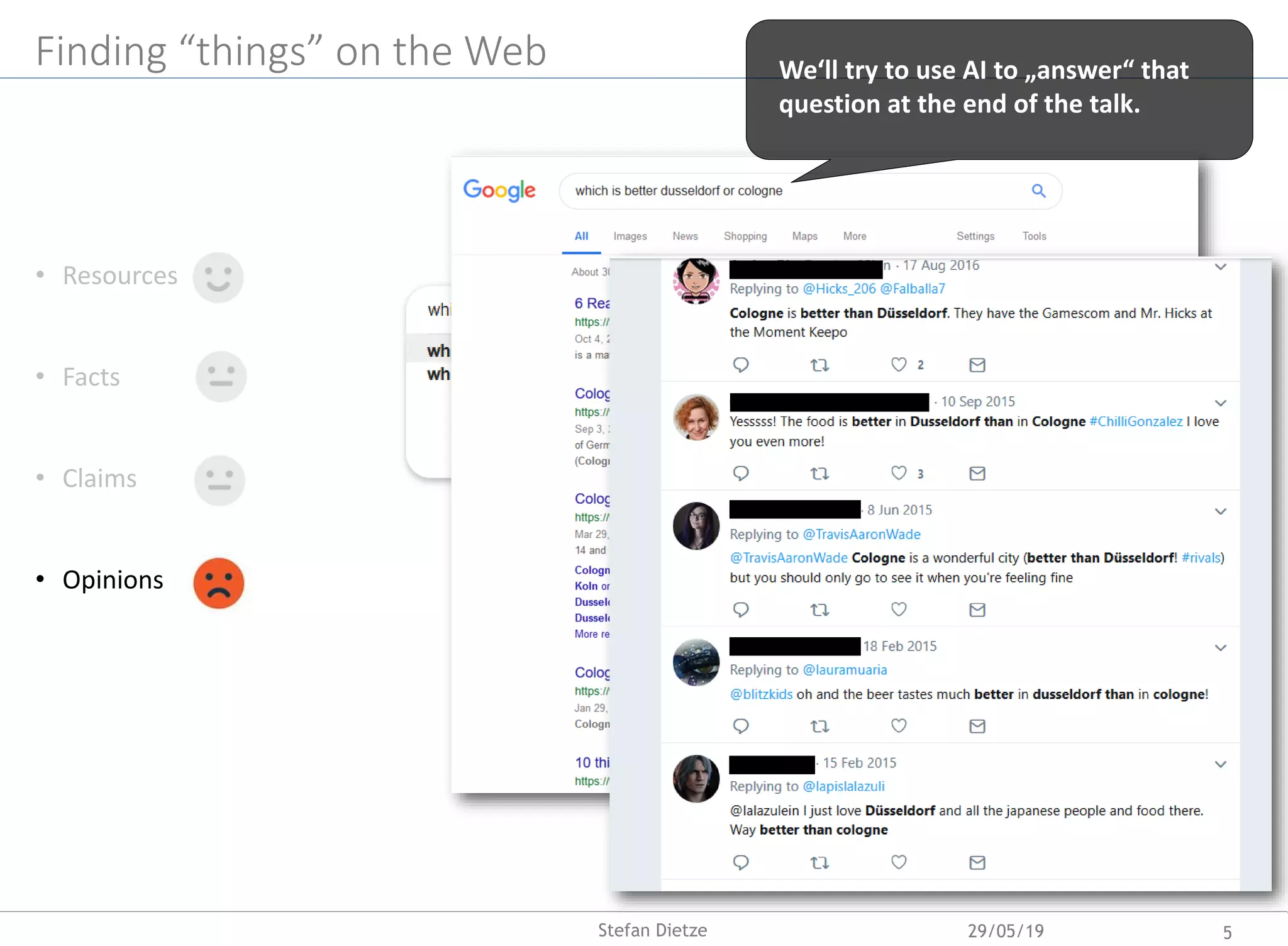
Download as PDF, PPTX



![Subsymbolic AI & deep learning for language understanding
Percentage of deep learning papers in major NLP conferences
(Source: Young et al., Recent Trends in Deep Learning Based Natural Language Processing)
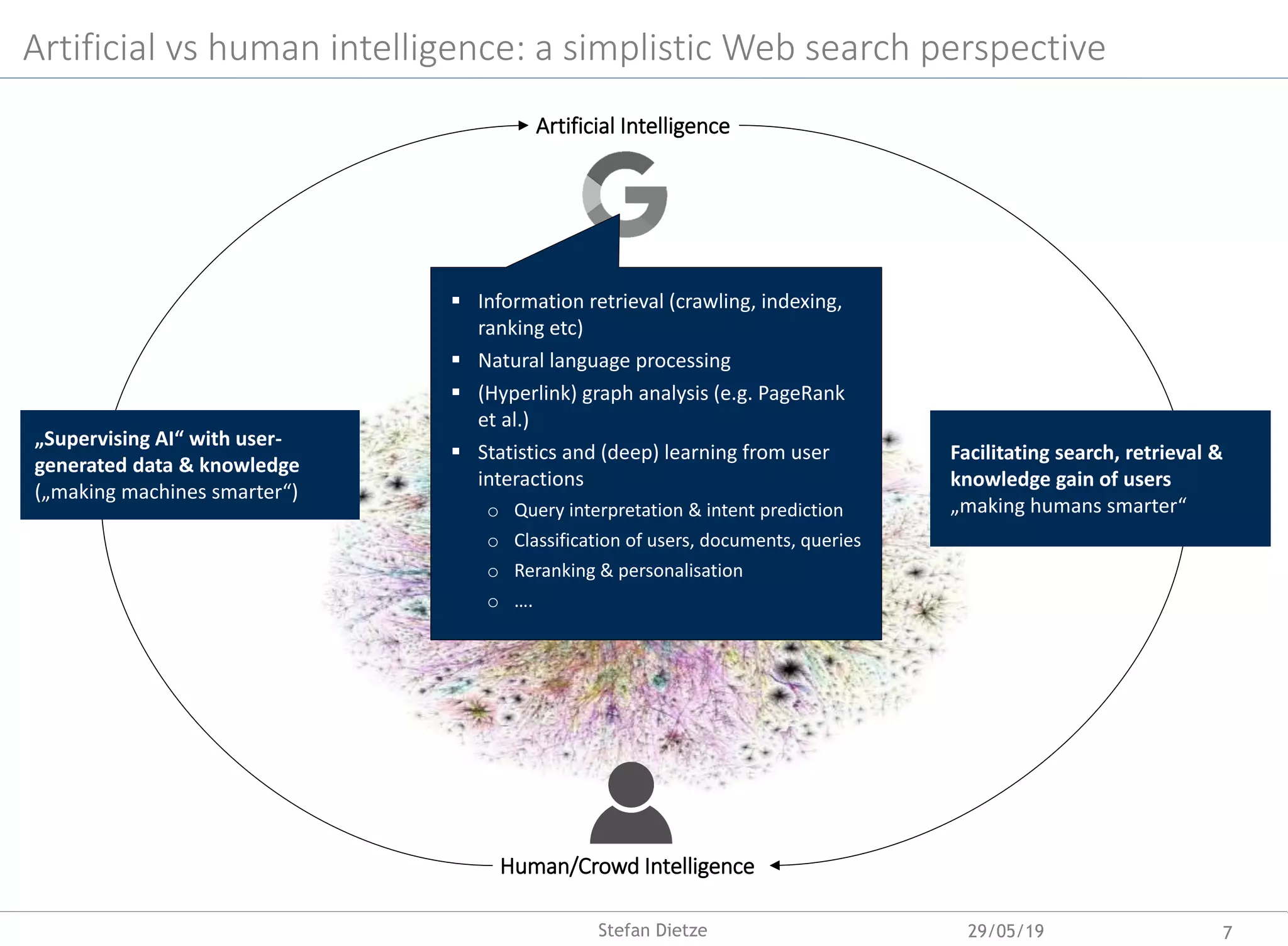
• Distributional semantics &
embeddings: predicting low-
dimensional vector representations
of words & text, e.g. Word2Vec
[Mikolov et al., 2013]
• Efficient RNN/CNN architectures in
encoder/decoder settings (e.g. for
machine translation) [Vaswani et al.,
2017]
• Pretraining language models for
task-specific transfer learning, e.g.,
BERT - Bidirectional Encoder
Representations from Transformers
[Devlin et al., 2018]
T. Mikolov et al., Distributed Representations of Words and Phrases and their Compositionality, NIPS (2013)
J. Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018)
A. Vaswani et al. Attention is all you need, NIPS (2017)
29/05/19 11Stefan Dietze](https://image.slidesharecdn.com/inaugural-lecture-dietze-hhu-2019-190529042827/75/From-Web-Data-to-Knowledge-on-the-Complementarity-of-Human-and-Artificial-Intelligence-11-2048.jpg)
![Source: https://techcrunch.com/2016/03/24/microsoft-silences-its-new-a-i-bot-tay-after-twitter-users-teach-it-racism/
• Biases in human interactions can be learned and elevated by ML models
• Meaning / semantics are crucial to facilitate interpretation by/of machines & ML models
[N-word]
Learning without semantics
29/05/19 12Stefan Dietze](https://image.slidesharecdn.com/inaugural-lecture-dietze-hhu-2019-190529042827/75/From-Web-Data-to-Knowledge-on-the-Complementarity-of-Human-and-Artificial-Intelligence-12-2048.jpg)

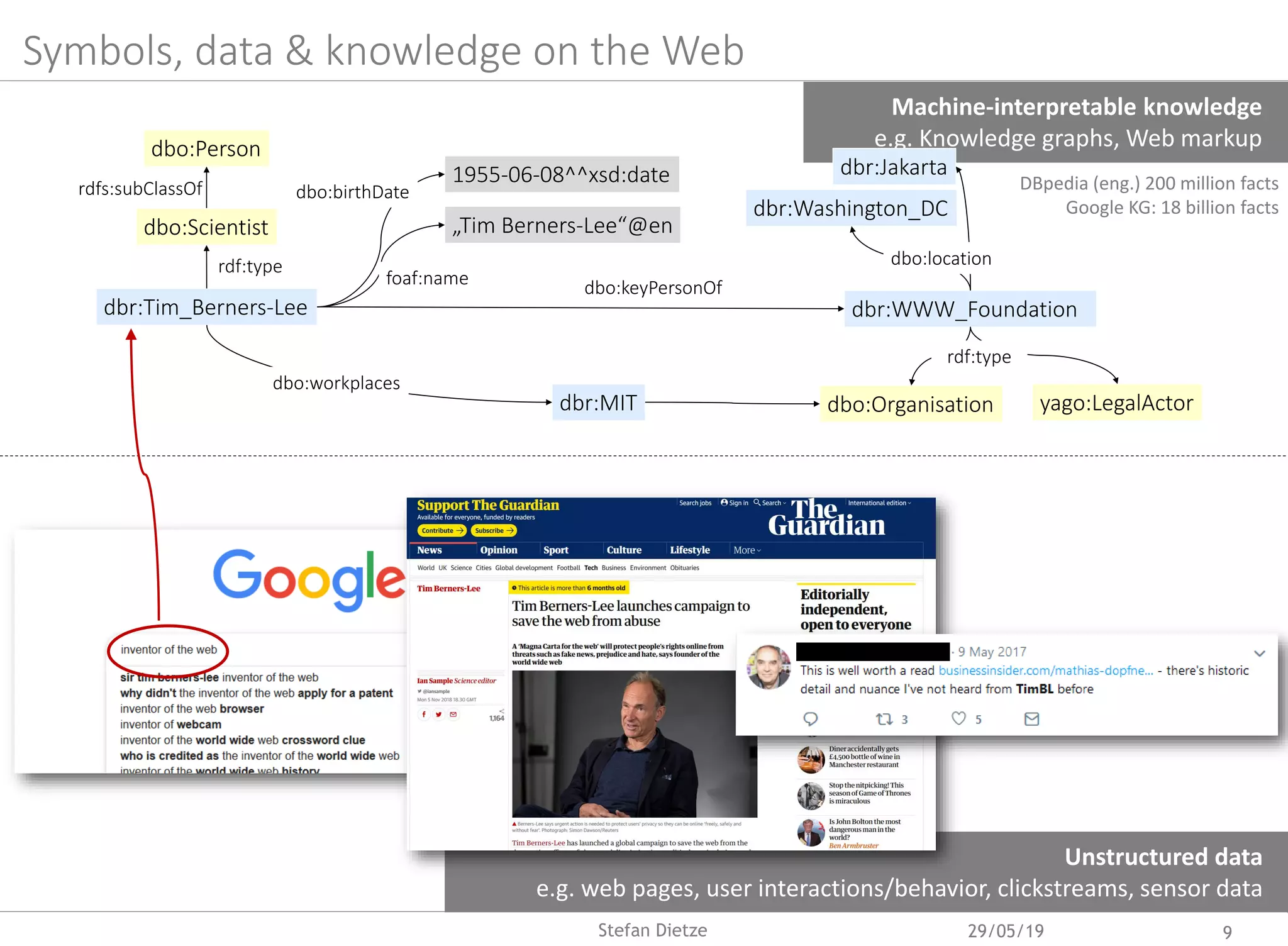
![Symbolic & subsymbolic AI: e.g. linking Web documents & KGs
Robust methods for named entity
disambiguation (NED), e.g. Ambiverse
[Hoffart et al., 2011], Babelfy [Ferragina et al., 2010],
TagMe [Moro et al., 2014]
Time- and corpus-specific entity
relatedness; prior probabilities and
meaning of entities change over time, e.g.
“Deutschland” during World Cup
[DL4KGS 2018]
Meta-EL: supervised ensemble learner
exploiting results of different NED systems
[SAC19, CIKM19]
o Considers features of terms,
mentions/occurrences,
dynamics/temporal drift etc
o Outperforms individual NED systems
across diverse documents/corpora
Problem:
“Completeness” & coverage of KGs?
Fafalios, P., Joao, R.S., Dietze, S., Same but Different: Distant
Supervision for Predicting and Understanding Entity Linking
Difficulty, ACM SAC19
Mohapatra, N., Iosifidis, V., Ekbal, A., Dietze, S., Fafalios, P., Time-
Aware and Corpus-Specific Entity Relatedness, DL4KGS at ESWC2018.
dbr:Tim_Berners-Lee
29/05/19 14](https://image.slidesharecdn.com/inaugural-lecture-dietze-hhu-2019-190529042827/75/From-Web-Data-to-Knowledge-on-the-Complementarity-of-Human-and-Artificial-Intelligence-14-2048.jpg)
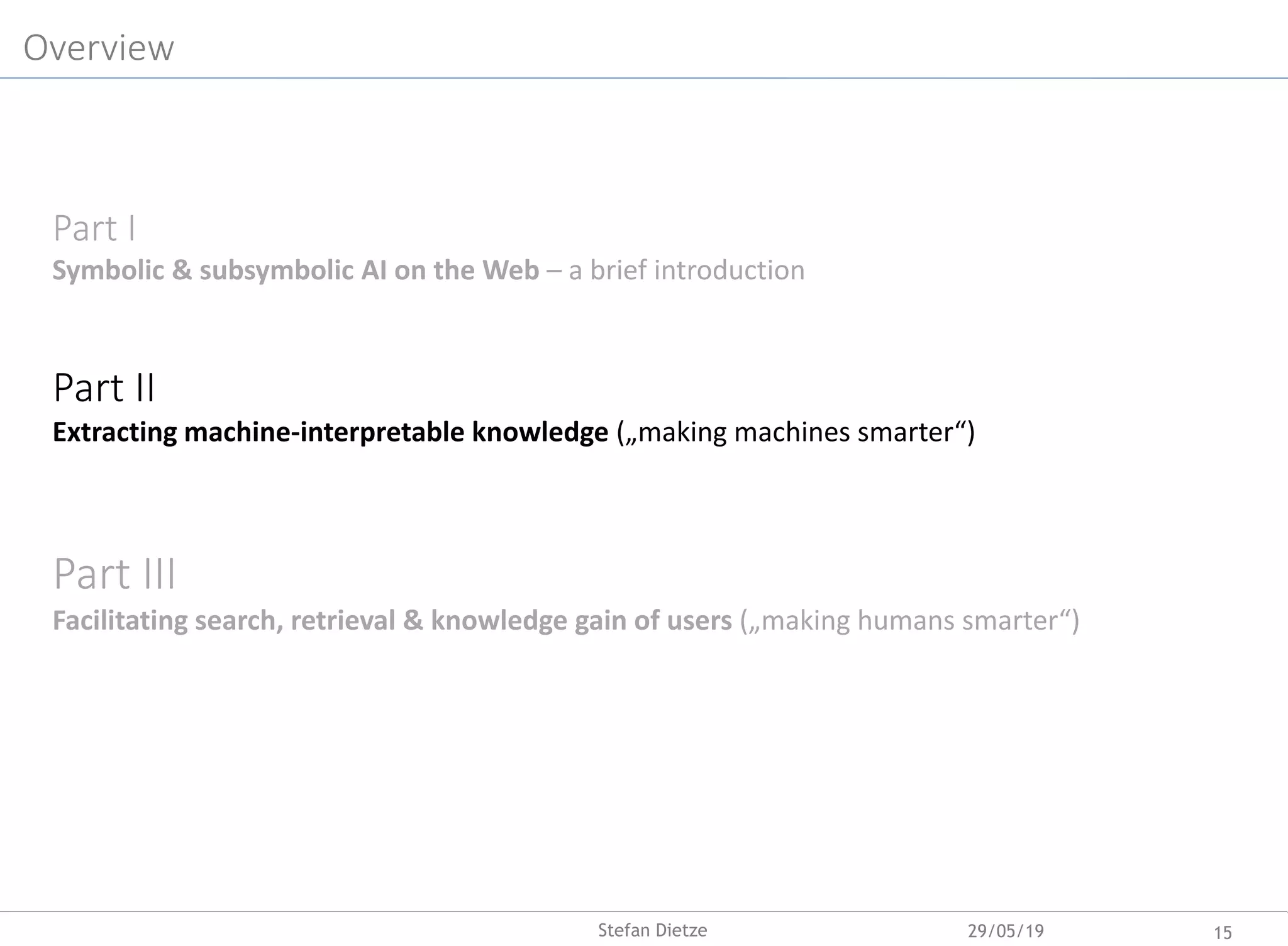
![Mining (long-tail) facts from the Web?
<„Tim Berners-Lee“ s:founderOf „Solid“>
Obtaining verified facts (or knowledge graph) for a
given entity?
Application of NLP (e.g. NER, relation extraction) at
Web-scale (Google index: 50 trn pages)?
Exploiting entity-centric embedded Web page markup
(schema.org), prevalent in roughly 40% off Web pages
(44 Bn „facts“ in Common Crawl 2016/3.2 Bn Web
pages)
Challenges
o Errors. Factual errors, annotation errors (see also
[Meusel et al, ESWC2015])
o Ambiguity & coreferences. e.g. 18.000 entity
descriptions of “iPhone 6” in Common Crawl 2016
& ambiguous literals (e.g. „Apple“>)
o Redundancies & conflicts vast amounts of
equivalent or conflicting statements
29/05/19 17Stefan Dietze](https://image.slidesharecdn.com/inaugural-lecture-dietze-hhu-2019-190529042827/75/From-Web-Data-to-Knowledge-on-the-Complementarity-of-Human-and-Artificial-Intelligence-17-2048.jpg)
![ 0. Noise: data cleansing (node URIs, deduplication etc)
1.a) Scale: Blocking (BM25 entity retrieval) on markup index
1.b) Relevance: supervised coreference resolution
2.) Quality & redundancy: data fusion through supervised fact classification (SVM, knn, RF, LR, NB), diverse
feature set (authority, relevance etc), considering source- (eg PageRank), entity-, & fact-level
KnowMore: data fusion on markup
1. Blocking &
coreference
resolution
2. Fusion / Fact selection
New Query Entities
BBC Audio, type:(Organization)
Chapman & Hall, type:(Publisher)
Put Out More Flags, type:(Book)
(supervised)
Entity Description
author Evelyn Waugh
priorWork Put Out More Flags
ISBN 978031874803074
copyrightHolder Evelyn Waugh
releaseDate 1945
… …
Query Entity
Brideshead Revisited,
type:(Book)
Candidate Facts
node1 publisher Chapman & Hall
node1 releaseDate 1945
node1 publishDate 1961
node2 country UK
node2 publisher Black Bay Books
node3 country US
node3 copyrightHolder Evelyn Waugh
… …. ….
Web page
markup
Web crawl
(Common Crawl,
44 bn facts)
approx. 5000 facts for „Brideshead Revisited“
(compare: 125.000 facts for „iPhone6“)
Yu, R., [..], Dietze, S., KnowMore-Knowledge Base
Augmentation with Structured Web Markup, Semantic
Web Journal 2019 (SWJ2019)
Tempelmeier, N., Demidova, S., Dietze, S., Inferring
Missing Categorical Information in Noisy and Sparse
Web Markup, The Web Conf. 2018 (WWW2018)
20 correct/non-redundant
facts for „Brideshead Rev.“
18Stefan Dietze
Fusion performance
Baselines: BM25, CBFS [ESWC2015], PreRecCorr [Pochampally
et. al., ACM SIGMOD 2014], strong variance across types
Knowledge Graph Augmentation
Experiments on books, movies, products
New facts (wrt DBpedia, Wikidata, Freebase):
On average 60% - 70% of all facts for books & movies new
(across KBs)
100% new facts for long-tail entities (e.g. products)
Additional experiments on learning new categorical features
(e.g. product categories or movie genres) [WWW2018]](https://image.slidesharecdn.com/inaugural-lecture-dietze-hhu-2019-190529042827/75/From-Web-Data-to-Knowledge-on-the-Complementarity-of-Human-and-Artificial-Intelligence-18-2048.jpg)
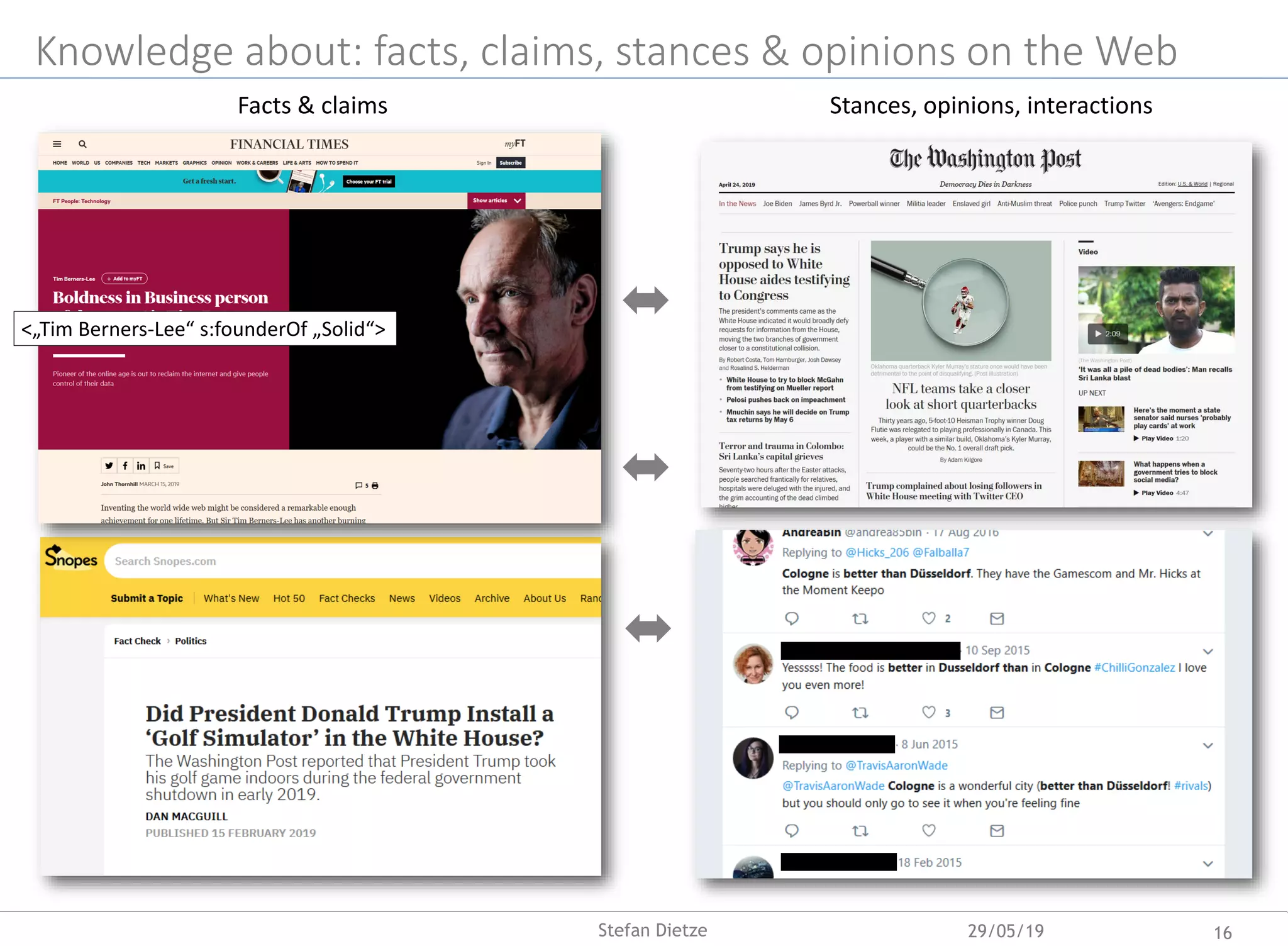
![Beyond facts: claims, opinions and misinformation on the Web
Investigations into misinformation and opinion forming
received massive attention across a wide range of
disciplines and industries (e.g. [Vousoughi et al. 2018])
Insights, mostly (computational) social sciences, e.g.
o Spreading of claims and misinformation
o Effect of biased and fake news on public opinions
o Reinforcement of biases and echo chambers
Methods, mostly in computer science, e.g. for
o Claim/fact detection and verification („fake news
detection“), e.g. CLEF 2018 Fact Checking Lab
(http://alt.qcri.org/clef2018-factcheck/)
o Stance detection, e.g. Fake News Challenge (FNC)
http://www.fakenewschallenge.org/
Some recent work
o Large-scale public research corpora for
replicating/improving methods/insights
o TweetsKB: 9 Bn annotated tweets
o ClaimsKG: 30 K annotated claims & truth ratings
o ML models for stance detection of Web documents
(towards given claims)
19Stefan Dietze](https://image.slidesharecdn.com/inaugural-lecture-dietze-hhu-2019-190529042827/75/From-Web-Data-to-Knowledge-on-the-Complementarity-of-Human-and-Artificial-Intelligence-19-2048.jpg)

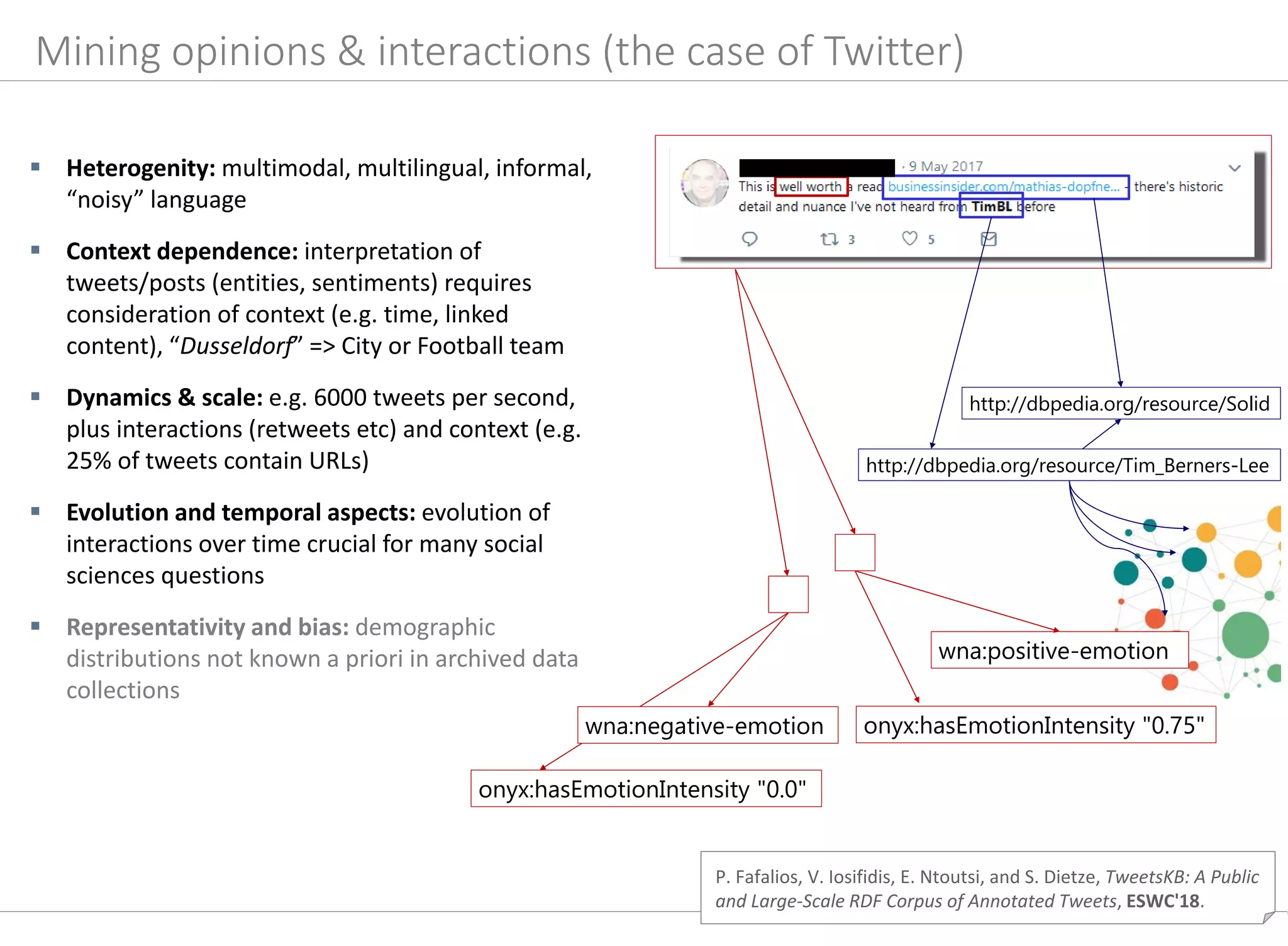
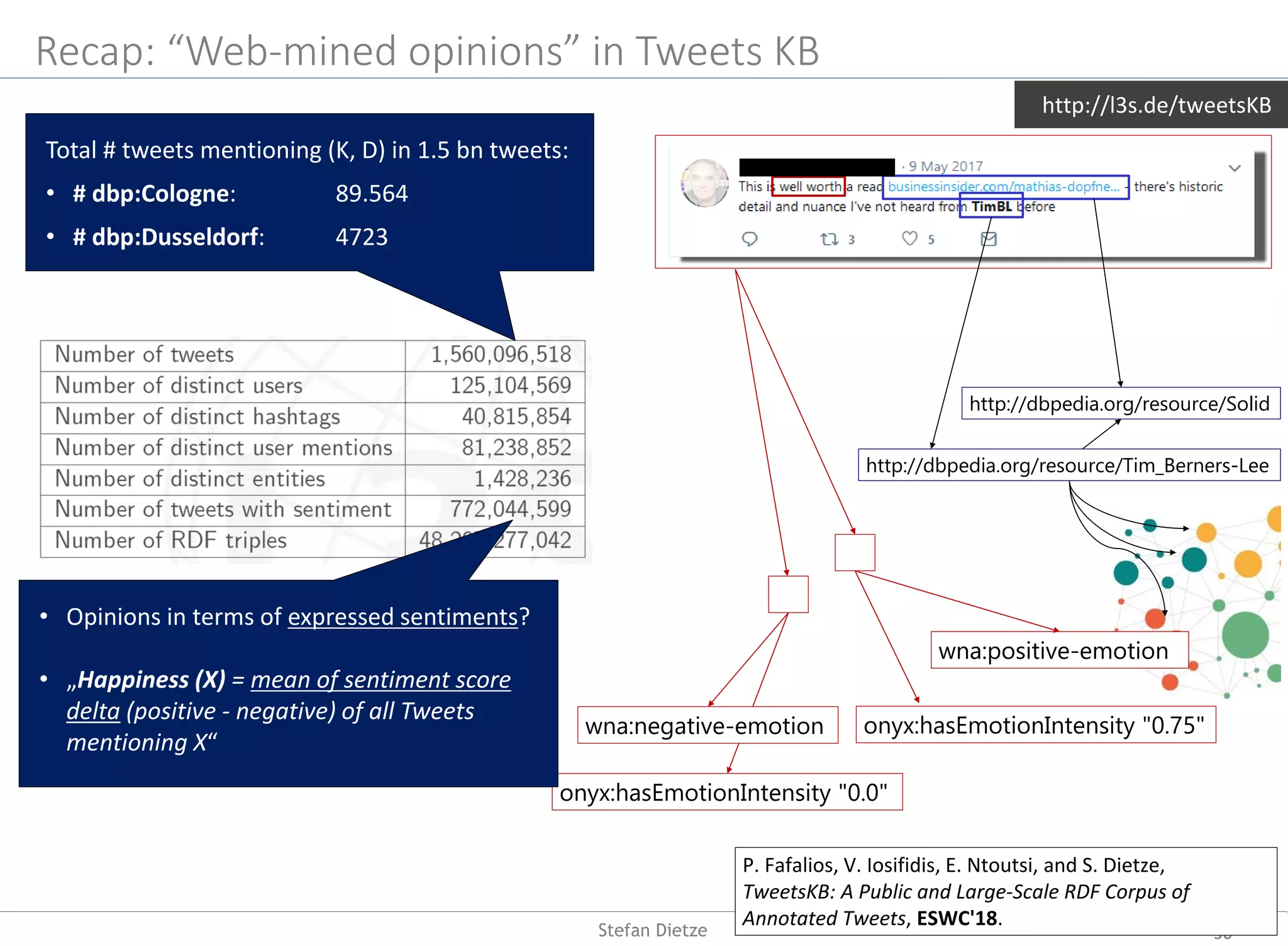
![P. Fafalios, V. Iosifidis, E. Ntoutsi, and S. Dietze, TweetsKB: A Public
and Large-Scale RDF Corpus of Annotated Tweets, ESWC'18.
Mining knowledge about opinions & interactions: TweetsKB
http://l3s.de/tweetsKB
Harvesting & archiving of 9 Bn tweets over 5 years
(permanent collection from Twitter 1% sample since
2013)
Information extraction pipeline (distributed via Hadoop
Map/Reduce)
o Entity linking with knowledge graph/DBpedia
(Yahoo‘s FEL [Blanco et al. 2015])
(“president”/“potus”/”trump” =>
dbp:DonaldTrump), to disambiguate text and use
background knowledge (eg US politicians?
Republicans?), high precision (.85), low recall (.39)
o Sentiment analysis/annotation using SentiStrength
[Thelwall et al., 2012], F1 approx. .80
o Extraction of metadata and lifting into established
schemas (SIOC, schema.org), publication using W3C
standards (RDF/SPARQL)
Use cases
Aggregating sentiments towards topics/entities, e.g. about
CDU vs SPD politicians in particular time period
Temporal analytics: evolution of popularity of entities/topics
over time (e.g. for detecting events or trends, such as rise of
populist parties)
Twitter archives as general corpus for understanding temporal
entity relatedness (e.g. “austerity” & “Greece” 2010-2015)
Limitations
Bias & representativity: demographic distributions of users
(not known a priori and not representative)
Cf. use case at the end of the talk
-0.40000
-0.30000
-0.20000
-0.10000
0.00000
0.10000
0.20000
0.30000
0.40000
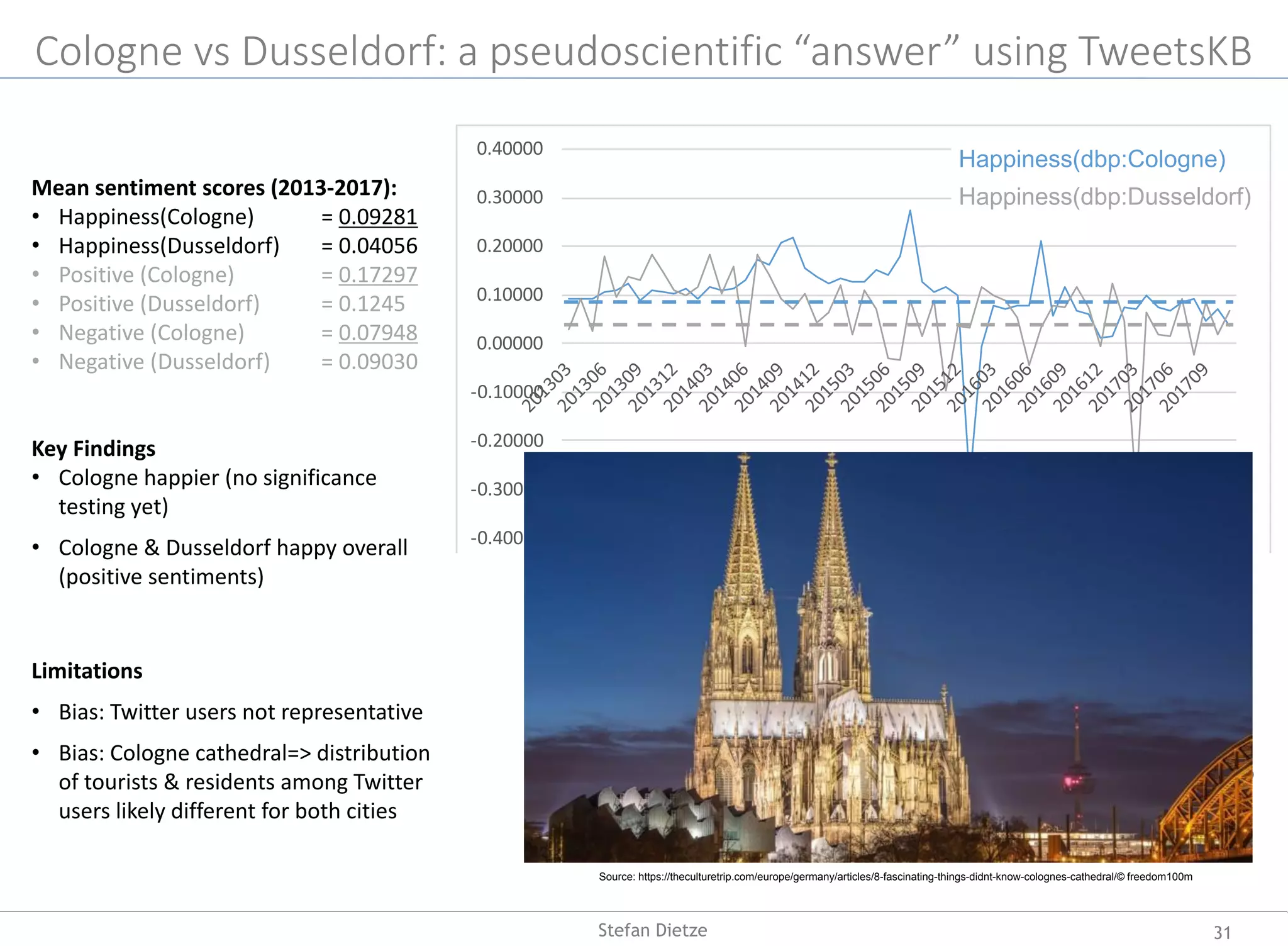
Cologne Düsseldorf](https://image.slidesharecdn.com/inaugural-lecture-dietze-hhu-2019-190529042827/75/From-Web-Data-to-Knowledge-on-the-Complementarity-of-Human-and-Artificial-Intelligence-22-2048.jpg)
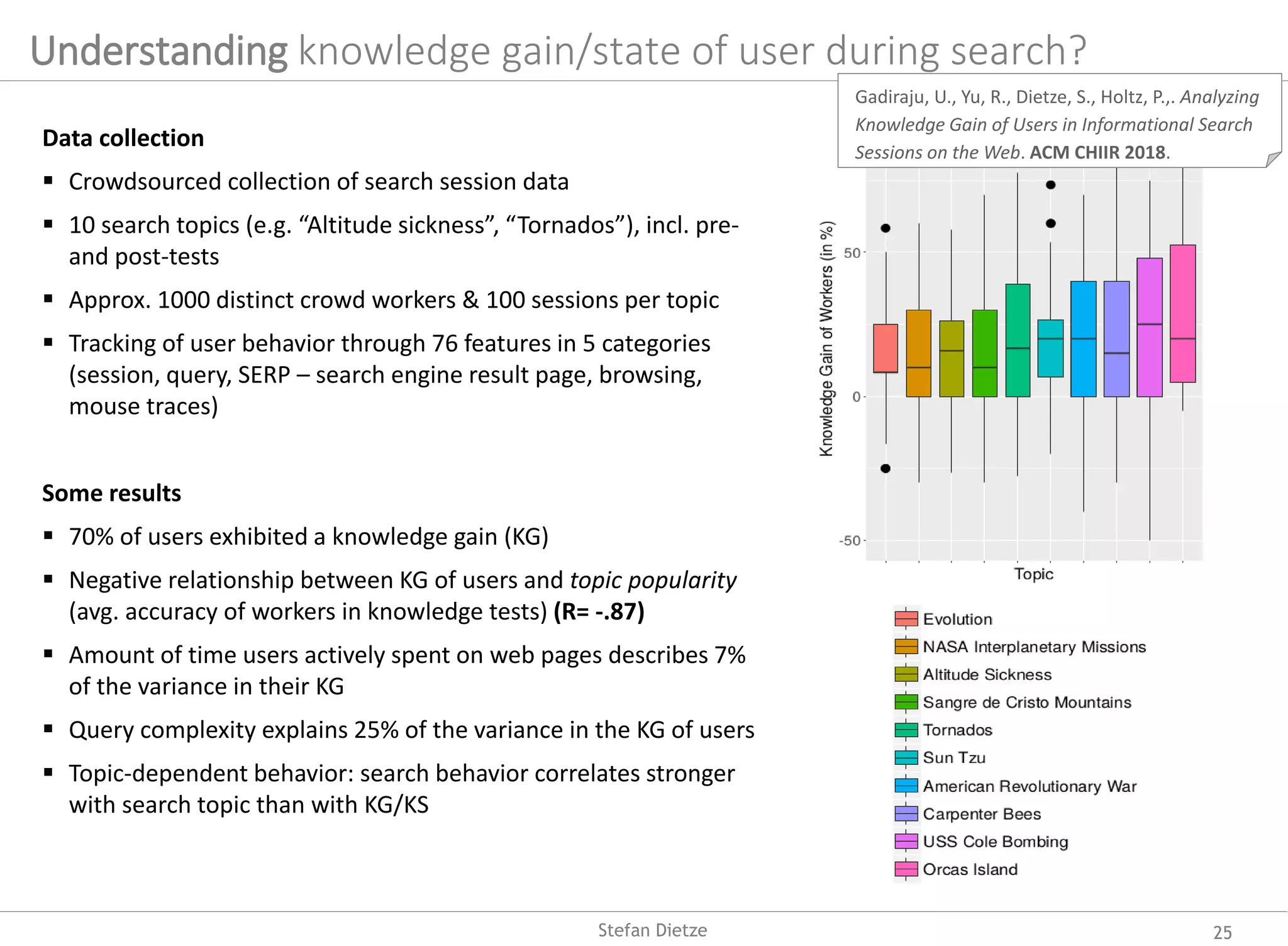
![Knowledge (gain) while searching the Web (“Search As Learning”)?
Challenges & results
Detecting coherent search missions?
Detecting learning throughout search?
detecting “informational” search missions (as
opposed to “transactional” or “navigational”
missions [Broder, 2002])
o Search mission classification with average F1
score 75%
How competent is the user? –
Predict/understand knowledge state of users
based on in-session behavior/interactions
How well does a user achieve his/her learning
goal/information need? - Predict knowledge gain
throughout search missions
o Correlation of user behavior (queries,
browsing, mouse traces, etc) & user
knowledge gain/state in search [CHIIR18]
o Prediction of knowledge gain/state through
supervised models [SIGIR18]
24Stefan Dietze](https://image.slidesharecdn.com/inaugural-lecture-dietze-hhu-2019-190529042827/75/From-Web-Data-to-Knowledge-on-the-Complementarity-of-Human-and-Artificial-Intelligence-24-2048.jpg)
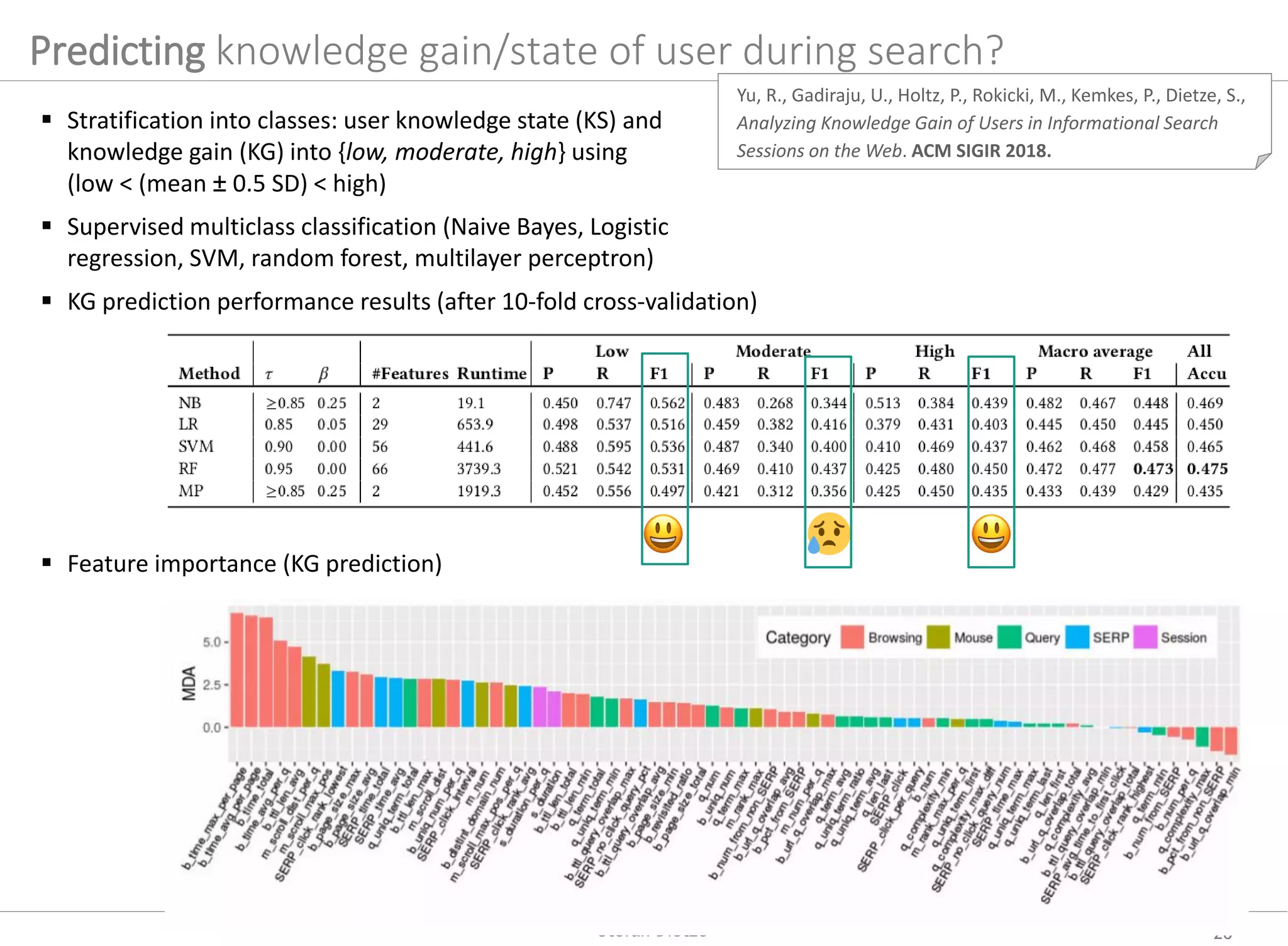
![Yu, R., Gadiraju, U., Holtz, P., Rokicki, M., Kemkes, P., Dietze, S.,
Analyzing Knowledge Gain of Users in Informational Search
Sessions on the Web. ACM SIGIR 2018.
Predicting knowledge gain/state of user during search?
29/05/19 27Stefan Dietze
Stratification into classes: user knowledge state (KS) and
knowledge gain (KG) into {low, moderate, high} using
(low < (mean ± 0.5 SD) < high)
Supervised multiclass classification (Naive Bayes, Logistic
regression, SVM, random forest, multilayer perceptron)
KG prediction performance results (after 10-fold cross-validation)
Feature importance (KG prediction)
Shortcomings & future work
Lab studies to obtain more reliable data (controlled
environment, longer sessions) & additional features (eye-
tracking)
Resource features (complexity, analytic/emotional
language, multimodality etc) as additional signals
[CIKM2019, under review]
Improving ranking/retrieval in Web search or other
archives
(SALIENT project, Leibniz Cooperative Excellence)](https://image.slidesharecdn.com/inaugural-lecture-dietze-hhu-2019-190529042827/75/From-Web-Data-to-Knowledge-on-the-Complementarity-of-Human-and-Artificial-Intelligence-27-2048.jpg)
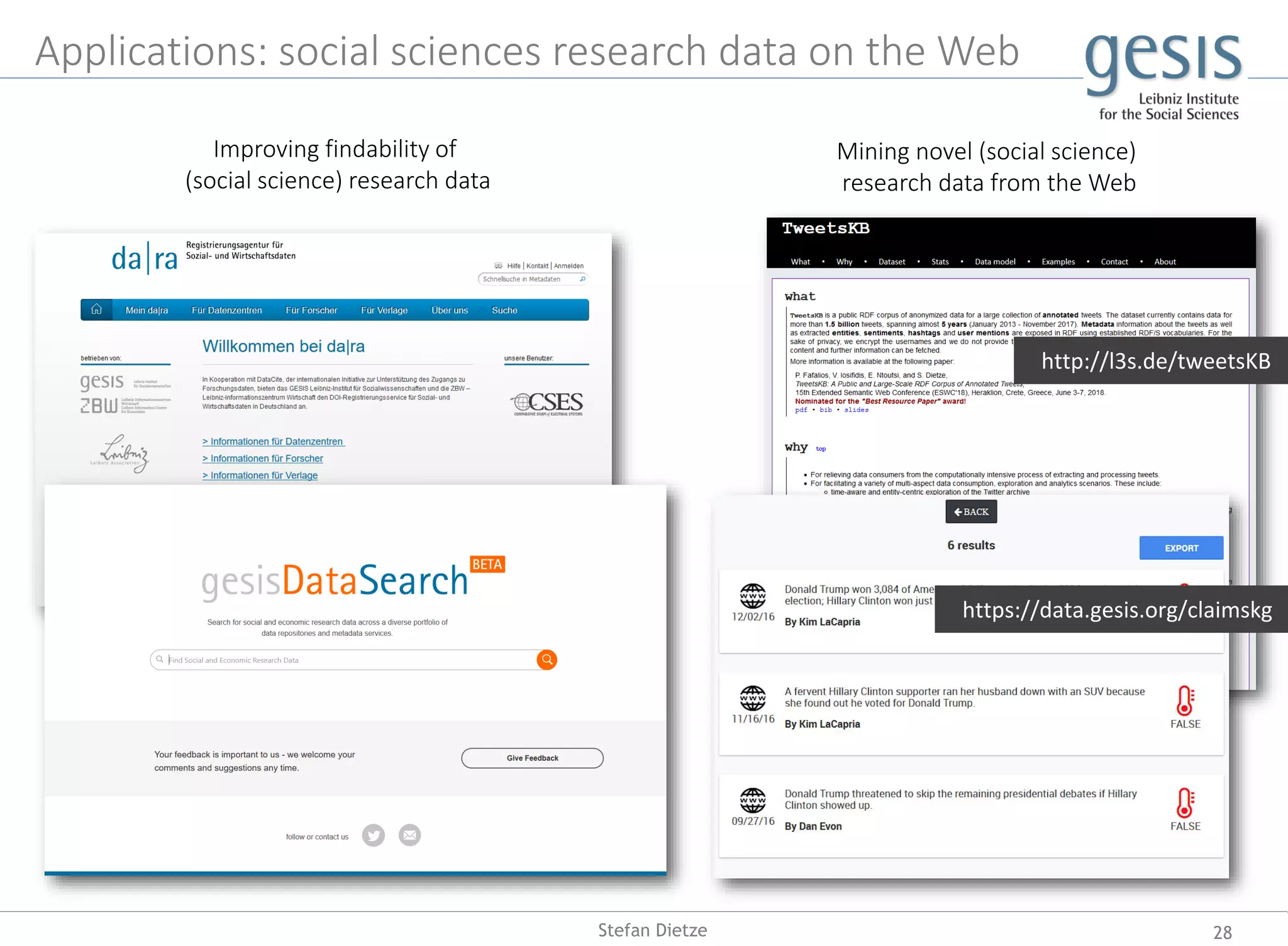



Prof. Dr. Stefan Dietze's inaugural lecture discusses the integration of human and artificial intelligence in enhancing web search and knowledge retrieval. He explores the roles of symbolic and subsymbolic AI, the extraction of machine-interpretable knowledge, and the challenges of misinformation and opinion formation online. The lecture emphasizes the importance of understanding user interactions and knowledge gain during web searching.









































































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)







