Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Y-h Taguchi
PDF, PPTX
625 views
Integrating different data types by regularized unsupervised multiple kernel learning with application to cancer subtype discovery
ISMB/ECCB2015読み会でのプレゼンテーション(日本語)
Science
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 10
2
/ 10
3
/ 10
4
/ 10
5
/ 10
6
/ 10
7
/ 10
8
/ 10
9
/ 10
10
/ 10
More Related Content
PDF
[DL輪読会]Grasping Field: Learning Implicit Representations for Human Grasps
by
Deep Learning JP
ODP
Ml ch7
by
Ryo Higashigawa
PDF
Arithmer R3 Introduction
by
Arithmer Inc.
PDF
Anomaly Detection by Latent Regularized Dual Adversarial Networks
by
ぱんいち すみもと
PDF
RUPC2017:M問題
by
Takumi Yamashita
PPTX
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PPT
Jokyokai
by
Taiji Suzuki
PDF
ICLR2020の異常検知論文の紹介 (2019/11/23)
by
ぱんいち すみもと
[DL輪読会]Grasping Field: Learning Implicit Representations for Human Grasps
by
Deep Learning JP
Ml ch7
by
Ryo Higashigawa
Arithmer R3 Introduction
by
Arithmer Inc.
Anomaly Detection by Latent Regularized Dual Adversarial Networks
by
ぱんいち すみもと
RUPC2017:M問題
by
Takumi Yamashita
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
Jokyokai
by
Taiji Suzuki
ICLR2020の異常検知論文の紹介 (2019/11/23)
by
ぱんいち すみもと
What's hot
PDF
Visualizing Data Using t-SNE
by
Tomoki Hayashi
PDF
論文紹介 Pixel Recurrent Neural Networks
by
Seiya Tokui
PDF
最近(2020/09/13)のarxivの分布外検知の論文を紹介
by
ぱんいち すみもと
ODP
Introduction to "Facial Landmark Detection by Deep Multi-task Learning"
by
Yukiyoshi Sasao
PDF
t-SNE
by
貴之 八木
PDF
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
PDF
Spring
by
Lutfiana Ariestien
PDF
Anomaly detection survey
by
ぱんいち すみもと
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
深層学習による非滑らかな関数の推定
by
Masaaki Imaizumi
PPTX
test
by
Kazuki Yoshida
PDF
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
PDF
はじめてのパターン認識輪読会 10章後半
by
koba cky
PDF
Variational denoising network
by
ぱんいち すみもと
PDF
点群深層学習 Meta-study
by
Naoya Chiba
Visualizing Data Using t-SNE
by
Tomoki Hayashi
論文紹介 Pixel Recurrent Neural Networks
by
Seiya Tokui
最近(2020/09/13)のarxivの分布外検知の論文を紹介
by
ぱんいち すみもと
Introduction to "Facial Landmark Detection by Deep Multi-task Learning"
by
Yukiyoshi Sasao
t-SNE
by
貴之 八木
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
Spring
by
Lutfiana Ariestien
Anomaly detection survey
by
ぱんいち すみもと
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
数学で解き明かす深層学習の原理
by
Taiji Suzuki
深層学習の数理
by
Taiji Suzuki
深層学習による非滑らかな関数の推定
by
Masaaki Imaizumi
test
by
Kazuki Yoshida
[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介
by
Deep Learning JP
はじめてのパターン認識輪読会 10章後半
by
koba cky
Variational denoising network
by
ぱんいち すみもと
点群深層学習 Meta-study
by
Naoya Chiba
Similar to Integrating different data types by regularized unsupervised multiple kernel learning with application to cancer subtype discovery
PPTX
Ismb2018yomi ibe
by
Tatsuro Ibe
PDF
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
PDF
Prml5 6
by
K5_sem
PDF
ユークリッド距離以外の距離で教師無しクラスタリング
by
Maruyama Tetsutaro
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PDF
データサイエンス概論第一=8 パターン認識と深層学習
by
Seiichi Uchida
PDF
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
Ismb2018yomi ibe
by
Tatsuro Ibe
PRML2.3.8~2.5 Slides in charge
by
Junpei Matsuda
Prml5 6
by
K5_sem
ユークリッド距離以外の距離で教師無しクラスタリング
by
Maruyama Tetsutaro
PRML第6章「カーネル法」
by
Keisuke Sugawara
データサイエンス概論第一=8 パターン認識と深層学習
by
Seiichi Uchida
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
More from Y-h Taguchi
PDF
Tensor decomposition based and principal component analysis based unsupervise...
by
Y-h Taguchi
PDF
主成分分析を用いた教師なし学習による筋萎縮性側索硬化症とがんの遺伝的関連性の解明
by
Y-h Taguchi
PDF
Tensor decompositionbased unsupervised feature extraction identified the un...
by
Y-h Taguchi
PDF
Tensor decomposition based unsupervised feature extraction applied to matrix...
by
Y-h Taguchi
PDF
遺伝子発現プロファイルからの 薬剤標的タンパクの統計的推定法の開発
by
Y-h Taguchi
PDF
Identification of Candidate Drugs for Heart Failure using Tensor Decompositio...
by
Y-h Taguchi
PDF
Rectified factor networks for biclustering of omics data
by
Y-h Taguchi
PDF
テンソル分解を用いた教師なし学習による変数選択
by
Y-h Taguchi
PDF
主成分分析を用いた教師なし学習による変数選択を用いたヒストン脱アセチル化酵素阻害剤の機能探索
by
Y-h Taguchi
PDF
『主成分分析を用いた教師なし学習による変数選択』 を用いたデング出血熱原因遺伝子の推定
by
Y-h Taguchi
PDF
miRNA-mRNA相互作用同定を用いた 腎芽腫関連遺伝子の推定
by
Y-h Taguchi
PDF
Principal component analysis based unsupervised feature extraction applied to...
by
Y-h Taguchi
PDF
microRNA-mRNA interaction identification in Wilms tumor using principal compo...
by
Y-h Taguchi
PDF
Comprehensive analysis of transcriptome andmetabolome analysis in Intrahepati...
by
Y-h Taguchi
PDF
主成分分析を用いた教師なし学習による出芽酵母 の時間周期遺伝子発現プロファイルの解析
by
Y-h Taguchi
PDF
PCAを用いた2群の有意差検定
by
Y-h Taguchi
PDF
SFRP1 is a possible candidate for epigenetic therapy in nonsmall cell lung ...
by
Y-h Taguchi
PDF
A cross-species bi-clustering approach to identifying conserved co-regulated ...
by
Y-h Taguchi
PDF
主成分分析を用いた教師なし学習による変数選択法を用いたがんにおけるmRNA-miRNA相互作用のより信頼性のある同定
by
Y-h Taguchi
PDF
Identification of aberrant gene expression associated with aberrant promoter ...
by
Y-h Taguchi
Tensor decomposition based and principal component analysis based unsupervise...
by
Y-h Taguchi
主成分分析を用いた教師なし学習による筋萎縮性側索硬化症とがんの遺伝的関連性の解明
by
Y-h Taguchi
Tensor decompositionbased unsupervised feature extraction identified the un...
by
Y-h Taguchi
Tensor decomposition based unsupervised feature extraction applied to matrix...
by
Y-h Taguchi
遺伝子発現プロファイルからの 薬剤標的タンパクの統計的推定法の開発
by
Y-h Taguchi
Identification of Candidate Drugs for Heart Failure using Tensor Decompositio...
by
Y-h Taguchi
Rectified factor networks for biclustering of omics data
by
Y-h Taguchi
テンソル分解を用いた教師なし学習による変数選択
by
Y-h Taguchi
主成分分析を用いた教師なし学習による変数選択を用いたヒストン脱アセチル化酵素阻害剤の機能探索
by
Y-h Taguchi
『主成分分析を用いた教師なし学習による変数選択』 を用いたデング出血熱原因遺伝子の推定
by
Y-h Taguchi
miRNA-mRNA相互作用同定を用いた 腎芽腫関連遺伝子の推定
by
Y-h Taguchi
Principal component analysis based unsupervised feature extraction applied to...
by
Y-h Taguchi
microRNA-mRNA interaction identification in Wilms tumor using principal compo...
by
Y-h Taguchi
Comprehensive analysis of transcriptome andmetabolome analysis in Intrahepati...
by
Y-h Taguchi
主成分分析を用いた教師なし学習による出芽酵母 の時間周期遺伝子発現プロファイルの解析
by
Y-h Taguchi
PCAを用いた2群の有意差検定
by
Y-h Taguchi
SFRP1 is a possible candidate for epigenetic therapy in nonsmall cell lung ...
by
Y-h Taguchi
A cross-species bi-clustering approach to identifying conserved co-regulated ...
by
Y-h Taguchi
主成分分析を用いた教師なし学習による変数選択法を用いたがんにおけるmRNA-miRNA相互作用のより信頼性のある同定
by
Y-h Taguchi
Identification of aberrant gene expression associated with aberrant promoter ...
by
Y-h Taguchi
Integrating different data types by regularized unsupervised multiple kernel learning with application to cancer subtype discovery
1.
Integrating different data types by regularized unsupervised multiple kernel learning with application to cancer subtype discovery Nora K. Speicher and Nico Pfeifer 発表者:中央大学理工学部物理学科田口善弘 Bioinformatics, 31, 2015, i268–i275
2.
( x11 x12 …
x1 N x21 x22 … x2 N … … … … xd 1 xd 2 … xdN )=( ⃗x1, ⃗x2, …, ⃗xN ) Nサンプル × d次元 特徴量 (N≪d) 目的 ( w11 w12 … w1N w21 w22 … w2N … … … … wN 1 wN 2 … wNN ) 類似度行列 wij δ( ⃗xi , ⃗xj)⇔ 大 小 類似度 距離
3.
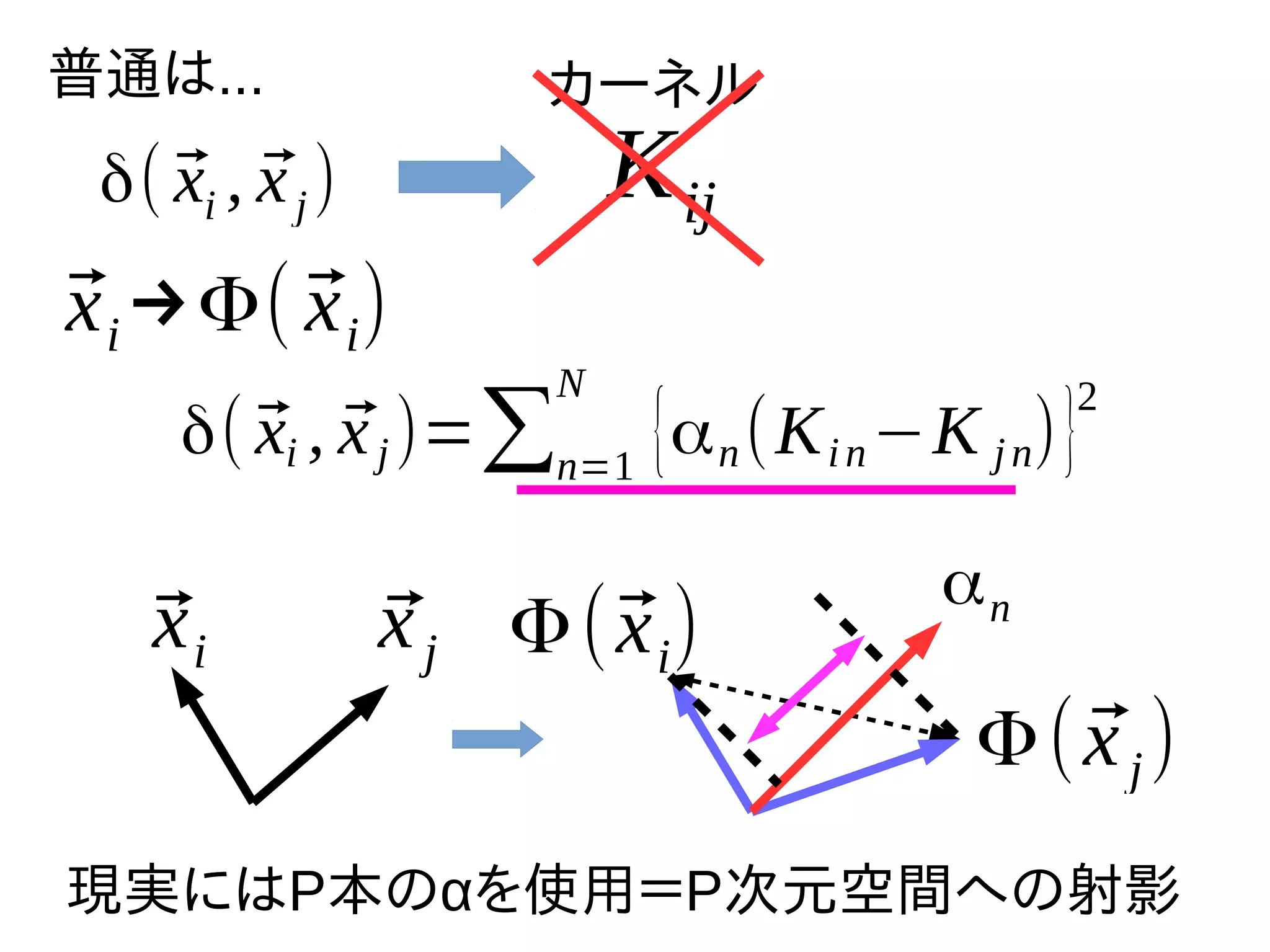
δ( ⃗xi ,
⃗xj) 普通は... Kij カーネル ⃗xi→Φ( ⃗xi) ⃗xi ⃗xj Φ(⃗xi) Φ( ⃗xj) αn δ( ⃗xi , ⃗xj)=∑n=1 N {αn(Kin−K jn)} 2 現実にはP本のαを使用=P次元空間への射影
4.
利点: ・入力データはカーネルなのでカーネル化できるも のはなんでも入力になる(複数種のカーネルの混 合使用可)。 ・教師あり、教師なし、半教師あり学習に対応 (w ij をデータから作れば教師なし学習)。 ・正規化項(次頁参照)を付加して過学習を抑止。 複数カーネルの統合法:線型結合(わりと芸がない..) Kij=∑m=1 M βm Kij m , βm⩾0
5.
∑ ij δ(⃗xi , ⃗x
j)wij min α,β ∑ i=1 N [δ( ⃗xi){∑ j=1 N wij }]=const . ∑ m=1 M |βm|=1 δ( ⃗xi)=∑ n=1 N (αn Kin) 2 ←カーネル空間でのx i のα方向への射影の2乗 x i の重要度 K ij =0を防ぐ∀ αn=0 を防ぐ
6.
今回の目的:ガンのサブタイプ wij= 1 i∈N
( j), j∈N (i) 0 N(i):iのk近傍→教師なし学習&低次元の構造誘導 δ( ⃗xi , ⃗xj)求まった を使ってカーネルK-means 最適クラスター数は silhouette width(クラス ターのコンパクトさを示す指標の一種)の平均値 が最大になるように決定
7.
結局、やっていること: カーネル空間(高次元空間)からP次元空間(低次元空間) になるべくコンパクトになるように射影する 「ランチはヘルメットをかぶって」1987 福田繁雄
8.
評価方法(生存解析): 全時期を通して多群の瞬間死亡率が等しいと仮 定した時のP値をχ二乗分布を仮定した対数順位 検定で求める。 対象データ(TCGA): 5種類のガンのサブタイプに対し て、mRNA,miRNA,DNAメチル化の3種類の データが与えられている(非常に高次元)。 時間 生 存 率
9.
5種のガン mRNA,miRNA,メチル化に 各1( )個のカーネル使用 αは5本で5次元への縮約、w ij 決定のための近傍 数は9,カーネルはガウスカーネル。 5 Similarity Network Fusion(従来法) ()内はクラスター数
10.
ISMB/ECCB2015に選ばれた理由: ・教師なし学習で生存曲線に差があるクラスター を作成することに成功 ・ロバストネス(説明できなかったが全サンプルの 50%しか使わなくてもLOOCVで求めたランド指 数が90%超) ・従来の高精度な手法は遺伝子数に対して指数 時間が必要なため、プレスクリーニングが必要 だったが提案手法は3乗程度なのでプレスクリー ニング不要 ・mRNA/miRNA/メチル化の統合解析可
Download



![∑
ij
δ(⃗xi , ⃗x j)wij
min
α,β
∑
i=1
N
[δ( ⃗xi){∑
j=1
N
wij }]=const . ∑
m=1
M
|βm|=1
δ( ⃗xi)=∑
n=1
N
(αn Kin)
2 ←カーネル空間でのx
i
のα方向への射影の2乗
x
i
の重要度 K
ij
=0を防ぐ∀
αn=0 を防ぐ](https://image.slidesharecdn.com/taguchipresen-150811035950-lva1-app6892/75/Integrating-different-data-types-by-regularized-unsupervised-multiple-kernel-learning-with-application-to-cancer-subtype-discovery-5-2048.jpg)






![[DL輪読会]Grasping Field: Learning Implicit Representations for Human Grasps](https://cdn.slidesharecdn.com/ss_thumbnails/graspingfieldlearningimplicitrepresentationsforhumangrasps1-210618032109-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)





























