Download as KEY, PPTX






![Tower of Babel
GitHub Twitter
{
{ "max_id": 195520745634406400,
"type": "User", "page": 1,
"followers": 35, "query": "%40gkellogg",
"html_url": "https://github.com/gkellogg", "results": [{
"hireable": true, "created_at": "Thu, 26 Apr 2012 14:32:33
"created_at": "2009-01-13T16:58:46Z", +0000",
"public_repos": 44, "from_user": "kendall",
"blog": "http://greggkellogg.net", "from_user_name": "Kendall Clark",
"bio": "Gregg is a Standards Architect ...", "id": 195520745634406400,
"gravatar_id": "in_reply_to_status_id":
"42f948adff3afaa52249d963117af7c8", 195518881811529729,
"following": 35, "iso_language_code": "en",
"company": "Self", "metadata": {"result_type": "recent"},
"public_gists": 4, "text": "@Gkellogg Multiple resources in a
"location": "San Rafael, CA", single JSON-LD struct/doc/message.",
"name": "Gregg Kellogg", "to_user": "Gkellogg",
"email": "gregg@kellogg-assoc.com", "to_user_id": 6125262,
"url": "https://api.github.com/users/gkellogg", "to_user_name": "Gregg Kellogg"
"avatar_url": "...", }],
"id": 46296, "results_per_page": 1,
"login": "gkellogg" "since_id": 0,
"since_id_str": "0"
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-6-320.jpg)
![Tower of Babel
GitHub Twitter Facebook
{
{ "max_id": 195520745634406400, {
"type": "User", "page": 1, "id": "1236600216",
"followers": 35, "query": "%40gkellogg", "name": "Gregg Kellogg",
"html_url": "https://github.com/gkellogg", "results": [{ "first_name": "Gregg",
"hireable": true, "created_at": "Thu, 26 Apr 2012 14:32:33 "last_name": "Kellogg",
"created_at": "2009-01-13T16:58:46Z", +0000", "link": "https://www.facebook.com/
"public_repos": 44, "from_user": "kendall", gkellogg",
"blog": "http://greggkellogg.net", "from_user_name": "Kendall Clark", "username": "gkellogg",
"bio": "Gregg is a Standards Architect ...", "id": 195520745634406400, "gender": "male",
"gravatar_id": "in_reply_to_status_id": "locale": "en_US"
"42f948adff3afaa52249d963117af7c8", 195518881811529729, }
"following": 35, "iso_language_code": "en",
"company": "Self", "metadata": {"result_type": "recent"},
"public_gists": 4, "text": "@Gkellogg Multiple resources in a
"location": "San Rafael, CA", single JSON-LD struct/doc/message.",
"name": "Gregg Kellogg", "to_user": "Gkellogg",
"email": "gregg@kellogg-assoc.com", "to_user_id": 6125262,
"url": "https://api.github.com/users/gkellogg", "to_user_name": "Gregg Kellogg"
"avatar_url": "...", }],
"id": 46296, "results_per_page": 1,
"login": "gkellogg" "since_id": 0,
"since_id_str": "0"
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-7-320.jpg)

![Self-describing Messages
• Give objects types {
"@context": {
(@type) "schema": "http://schema.org/",
"Person": "schema:Person",
"colleagues": {"@id": "schema:colleagues", "@type": "@id"},
"name": "schema:name",
"image": {"@id": "schema:image", "@type": "@id"},
"url": {"@id": "schema:url", "@type": "@id"}
}
}
{
"@context": "http://example.com/context.jsonld",
"@type": "Person",
"image": "http://localhost:9393/examples/schema.org/janedoe.jpg",
"colleagues": [
"http://www.xyz.edu/students/alicejones.html",
"http://www.xyz.edu/students/bobsmith.html"
],
"name": "Jane Doe",
"url": "http://www.janedoe.com"
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-9-320.jpg)
![Self-describing Messages
• Give objects types {
"@context": {
(@type) "schema": "http://schema.org/",
"Person": "schema:Person",
•
"colleagues": {"@id": "schema:colleagues", "@type": "@id"},
Associate properties "name": "schema:name",
"image": {"@id": "schema:image", "@type": "@id"},
with IRIs "url": {"@id": "schema:url", "@type": "@id"}
}
}
{
"@context": "http://example.com/context.jsonld",
"@type": "Person",
"image": "http://localhost:9393/examples/schema.org/janedoe.jpg",
"colleagues": [
"http://www.xyz.edu/students/alicejones.html",
"http://www.xyz.edu/students/bobsmith.html"
],
"name": "Jane Doe",
"url": "http://www.janedoe.com"
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-10-320.jpg)
![Self-describing Messages
• Give objects types {
"@context": {
(@type) "schema": "http://schema.org/",
"Person": "schema:Person",
•
"colleagues": {"@id": "schema:colleagues", "@type": "@id"},
Associate properties "name": "schema:name",
"image": {"@id": "schema:image", "@type": "@id"},
with IRIs "url": {"@id": "schema:url", "@type": "@id"}
}
•
}
Use terms defined in a
referenced context {
"@context": "http://example.com/context.jsonld",
"@type": "Person",
"image": "http://localhost:9393/examples/schema.org/janedoe.jpg",
"colleagues": [
"http://www.xyz.edu/students/alicejones.html",
"http://www.xyz.edu/students/bobsmith.html"
],
"name": "Jane Doe",
"url": "http://www.janedoe.com"
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-11-320.jpg)
![Self-describing Messages
• Give objects types {
"@context": {
(@type) "schema": "http://schema.org/",
"Person": "schema:Person",
•
"colleagues": {"@id": "schema:colleagues", "@type": "@id"},
Associate properties "name": "schema:name",
"image": {"@id": "schema:image", "@type": "@id"},
with IRIs "url": {"@id": "schema:url", "@type": "@id"}
}
•
}
Use terms defined in a
referenced context {
"@context": "http://example.com/context.jsonld",
"@type": "Person",
• Specify property types
"image": "http://localhost:9393/examples/schema.org/janedoe.jpg",
"knows": [
"http://www.xyz.edu/students/alicejones.html",
in context "http://www.xyz.edu/students/bobsmith.html"
],
"name": "Jane Doe",
"url": "http://www.janedoe.com"
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-12-320.jpg)



![• Make full use of JSON syntactic
{
"@context": "http://json-ld.org/contexts/person",
representations "@id": "http://greggkellogg.net/foaf#me",
"@type": "Person",
• Object defines a subject "name": "Gregg Kellogg",
"knows": "http://www.markus-lanthaler.com/"
definition }
• Also used for subject
reference and value { "@id": "http://greggkellogg.net/foaf#me" }
representations
{
"@type": "Recipe",
"name": "Mom's World Famous Banana Bread",
"ingredients": [
• Arrays describe sets of unordered
values
"3 or 4 ripe bananas, smashed",
"1 egg",
"3/4 cup of sugar"
],
• Single values can skip array "nutrition": [{
"@type": ["NutritionInformation"],
"calories": ["240 calories"],
"fatContent": ["9 grams fat"]
}]
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-16-320.jpg)









![DBpedia
{
"@graph": [
{
"@id": "http://dbpedia.org/resource/DBpedia",
"http://dbpedia.org/property/genre" : [ "http://dbpedia.org/resource/Linked_Data" ]
},
{
"@id": "http://dbpedia.org/resource/Linked_Data",
"@type" : [ "http://dbpedia.org/class/yago/Buzzwords" ] ,
"http://www.w3.org/2002/07/owl#sameAs" : ["http://rdf.freebase.com/ns/m/02r2kb1"] ,
"http://www.w3.org/2000/01/rdf-schema#comment": [
{ "@value" : "Linked Open Data (LOD) bezeichnet ..." , "@language" : "de" } ,
{ "@value" : "In computing, linked Data describes ..." , "@language" : "en" } ],
"http://purl.org/dc/terms/subject" : [
"http://dbpedia.org/resource/Category:World_Wide_Web" ,
"http://dbpedia.org/resource/Category:Buzzwords" ,
"http://dbpedia.org/resource/Category:Semantic_Web"
],
...
}]
}
http://dbpedia.org/sparql?default-graph-uri=http%3A%2F%2Fdbpedia.org&query=DESCRIBE+<http://dbpedia.org/resource/
Linked_Data>&output=application%2Fld%2Bjson](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-26-320.jpg)

![Schema.org
{
"@context": {...},
Using RDFa to JSON-LD bookmarklet* "@graph": [{
"@id": "http://linter.structured-data.org/examples/schema.org/Recipe.rdfa",
"rdfa:usesVocabulary": "http://schema.org/"
}, {
"@type": ["Recipe"],
"name": ["Mom's World Famous Banana Bread"],
"author": ["John Smith"],
"publishDate": ["2009-05-08"],
"image": [{"@id": ".../bananabread.jpg"}],
http://linter.structured-data.org/examples/ "description": ["This classic banana bread recipe ..."],
schema.org/sdo_eg_rdfa_12.html "prepTime": ["PT15M"],
"cookTime": ["PT1H"],
"recipeYield": ["1 loaf"],
"nutrition": [{
"@type": ["NutritionInformation"],
"calories": ["240 calories"],
"fatContent": ["9 grams fat"]
}],
"ingredients": [
"3 or 4 ripe bananas, smashed",
"1 egg",
"3/4 cup of sugar"
],
"recipeInstructions": ["Preheat the oven to 350 degrees..."],
"interactionCount": ["UserComments:140"]
}]
* bookmarklet courtesy of Niklas Lindström
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-28-320.jpg)
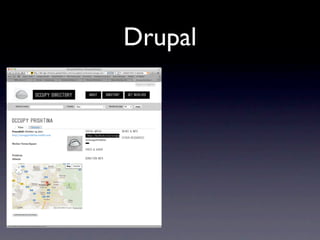
![Drupal
{
"@context": "http://drupal.example.org/context.jsonld",
"@id": "http://directory.occupy.net/occupation/al/occupy-
prishtina",
"@type": ["ows:Occupation", "schema:Organization"],
"foaf:name": "Occupy Prishtina",
"schema:name": "Occupy Prishtina",
"dc:date": "2012-02-12T21:18:08-05:00",
"dc:created": "2012-02-12T21:18:08-05:00",
"dc:modified": "2012-02-12T21:57:52-05:00",
"sioc:num_replies": 0,
"schema:foundingDate": "2011-10-15T00:00:00-04:00",
"ows:twitter_account": "@OccupyPrishtina",
"foaf:mbox": "",
"schema:telephone": "",
"foaf:phone": ""
}
http://directory.occupy.net/node/20080.jsonld](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-30-320.jpg)
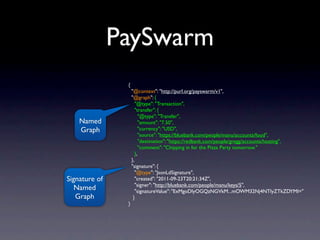
![Working with data
• Expand documents to remove effect of @context.
{
"@context": "http://drupal.example.org/context.jsonld",
"@id": "http://directory.occupy.net/occupation/al/occupy-
prishtina",
"@type": ["ows:Occupation", "schema:Organization"],
"foaf:name": "Occupy Prishtina",
"schema:name": "Occupy Prishtina",
"dc:date": "2012-02-12T21:18:08-05:00",
"dc:created": "2012-02-12T21:18:08-05:00",
"dc:modified": "2012-02-12T21:57:52-05:00",
"sioc:num_replies": 0,
"schema:foundingDate": "2011-10-15T00:00:00-04:00",
"ows:twitter_account": "@OccupyPrishtina",
"foaf:mbox": "",
"schema:telephone": "",
"foaf:phone": ""
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-32-320.jpg)
![Working with data
• Expand documents to remove effect of @context.
[{
"@id": "http://directory.occupy.net/occupation/al/occupy-prishtina",
{ "@type": ["http://vocab.occupy.net/ows#Occupation", "http://schema.org/Organization"],
"@context": "http://drupal.example.org/context.jsonld", "http://purl.org/dc/terms/created": [{
"@id": "http://directory.occupy.net/occupation/al/occupy- "@type": "http://www.w3.org/2001/XMLSchema#dateTime",
"@value": "2012-02-12T21:18:08-05:00"
prishtina",
}],
"@type": ["ows:Occupation", "schema:Organization"], "http://purl.org/dc/terms/date": [{
"foaf:name": "Occupy Prishtina", "@type": "http://www.w3.org/2001/XMLSchema#dateTime",
"schema:name": "Occupy Prishtina", "@value": "2012-02-12T21:18:08-05:00"
}],
"dc:date": "2012-02-12T21:18:08-05:00",
"http://purl.org/dc/terms/modified": [{
"dc:created": "2012-02-12T21:18:08-05:00", "@type": "http://www.w3.org/2001/XMLSchema#dateTime",
"dc:modified": "2012-02-12T21:57:52-05:00", "@value": "2012-02-12T21:57:52-05:00"
"sioc:num_replies": 0, }],
"http://rdfs.org/sioc/ns#num_replies": [{
"schema:foundingDate": "2011-10-15T00:00:00-04:00",
"@type": "http://www.w3.org/2001/XMLSchema#integer",
"ows:twitter_account": "@OccupyPrishtina", "@value": "0"
"foaf:mbox": "", }],
"schema:telephone": "", "http://schema.org/foundingDate": [{
"@type": "http://www.w3.org/2001/XMLSchema#date",
"foaf:phone": ""
"@value": "2011-10-15T00:00:00-04:00"
} }],
"http://schema.org/name": ["Occupy Prishtina"],
"http://schema.org/telephone": [""],
"http://vocab.occupy.net/ows#twitter_account": ["@OccupyPrishtina"],
"http://xmlns.com/foaf/0.1/mbox": [""],
"http://xmlns.com/foaf/0.1/name": ["Occupy Prishtina"],
"http://xmlns.com/foaf/0.1/phone": [""]
}]](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-33-320.jpg)
![Working with data
• Compact documents to apply a @context.
[{
"@id": "http://directory.occupy.net/occupation/al/occupy-prishtina",
"@type": ["http://vocab.occupy.net/ows#Occupation", "http://schema.org/Organization"],
"http://purl.org/dc/terms/created": [{
"@type": "http://www.w3.org/2001/XMLSchema#dateTime",
"@value": "2012-02-12T21:18:08-05:00"
}],
"http://purl.org/dc/terms/date": [{
"@type": "http://www.w3.org/2001/XMLSchema#dateTime",
"@value": "2012-02-12T21:18:08-05:00"
}],
"http://purl.org/dc/terms/modified": [{
"@type": "http://www.w3.org/2001/XMLSchema#dateTime",
"@value": "2012-02-12T21:57:52-05:00"
}],
"http://rdfs.org/sioc/ns#num_replies": [{
"@type": "http://www.w3.org/2001/XMLSchema#integer",
"@value": "0"
}],
"http://schema.org/foundingDate": [{
"@type": "http://www.w3.org/2001/XMLSchema#date",
"@value": "2011-10-15T00:00:00-04:00"
}],
"http://schema.org/name": ["Occupy Prishtina"],
"http://schema.org/telephone": [""],
"http://vocab.occupy.net/ows#twitter_account": ["@OccupyPrishtina"],
"http://xmlns.com/foaf/0.1/mbox": [""],
"http://xmlns.com/foaf/0.1/name": ["Occupy Prishtina"],
"http://xmlns.com/foaf/0.1/phone": [""]
}]](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-34-320.jpg)
![Working with data
• Compact documents to apply a @context.
[{
"@id": "http://directory.occupy.net/occupation/al/occupy-prishtina",
{
"@type": ["http://vocab.occupy.net/ows#Occupation", "http://schema.org/Organization"], "@context": "http://drupal.example.org/context.jsonld",
"http://purl.org/dc/terms/created": [{ "@id": "http://directory.occupy.net/occupation/al/occupy-
"@type": "http://www.w3.org/2001/XMLSchema#dateTime", prishtina",
"@value": "2012-02-12T21:18:08-05:00" "@type": ["ows:Occupation", "schema:Organization"],
}],
"http://purl.org/dc/terms/date": [{ "foaf:name": "Occupy Prishtina",
"@type": "http://www.w3.org/2001/XMLSchema#dateTime", "schema:name": "Occupy Prishtina",
"@value": "2012-02-12T21:18:08-05:00" "dc:date": "2012-02-12T21:18:08-05:00",
}], "dc:created": "2012-02-12T21:18:08-05:00",
"http://purl.org/dc/terms/modified": [{
"@type": "http://www.w3.org/2001/XMLSchema#dateTime", "dc:modified": "2012-02-12T21:57:52-05:00",
"@value": "2012-02-12T21:57:52-05:00" "sioc:num_replies": 0,
}], "schema:foundingDate": "2011-10-15T00:00:00-04:00",
"http://rdfs.org/sioc/ns#num_replies": [{ "ows:twitter_account": "@OccupyPrishtina",
"@type": "http://www.w3.org/2001/XMLSchema#integer",
"@value": "0" "foaf:mbox": "",
}], "schema:telephone": "",
"http://schema.org/foundingDate": [{ "foaf:phone": ""
"@type": "http://www.w3.org/2001/XMLSchema#date", }
"@value": "2011-10-15T00:00:00-04:00"
}],
"http://schema.org/name": ["Occupy Prishtina"],
"http://schema.org/telephone": [""],
"http://vocab.occupy.net/ows#twitter_account": ["@OccupyPrishtina"],
"http://xmlns.com/foaf/0.1/mbox": [""],
"http://xmlns.com/foaf/0.1/name": ["Occupy Prishtina"],
"http://xmlns.com/foaf/0.1/phone": [""]
}]](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-35-320.jpg)
![Working with data
• Frame documents to impose structure
input
{
"@context": {
"dc": "http://purl.org/dc/elements/1.1/",
"ex": "http://example.org/vocab#",
"contains": {"@type": "@id"}
},
"@graph": [{
"@id": "http://example.org/test/#library",
"@type": "ex:Library",
"ex:contains": "http://example.org/test#book"
}, {
"@id": "http://example.org/test#book",
"@type": "ex:Book",
"dc:contributor": "Writer",
"dc:title": "My Book",
"ex:contains": "http://example.org/test#chapter"
}, {
"@id": "http://example.org/test#chapter",
"@type": "ex:Chapter",
"dc:description": "Fun",
"dc:title": "Chapter One"
}]
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-36-320.jpg)
![Working with data
• Frame documents to impose structure
input frame
{ {
"@context": { "@context": {
"dc": "http://purl.org/dc/elements/1.1/", "dc": "http://purl.org/dc/elements/1.1/",
"ex": "http://example.org/vocab#", "ex": "http://example.org/vocab#",
"contains": {"@type": "@id"} "contains": {“@id”: “ex:contains”, "@type": "@id",
}, “title”: “dc:title”
"@graph": [{ },
"@id": "http://example.org/test/#library", "@type": "ex:Library",
+
"@type": "ex:Library", "contains": {
"ex:contains": "http://example.org/test#book" "@type": "ex:Book",
}, { "contains": {
"@id": "http://example.org/test#book", "@type": "ex:Chapter"
"@type": "ex:Book", }
"dc:contributor": "Writer", }
"dc:title": "My Book", }
"ex:contains": "http://example.org/test#chapter"
}, {
"@id": "http://example.org/test#chapter",
"@type": "ex:Chapter",
"dc:description": "Fun",
"dc:title": "Chapter One"
}]
}](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-37-320.jpg)
![Working with data
• Frame documents to impose structure
input frame output
{ {
{
"@context": { "@context": {
"@context": {
"dc": "http://purl.org/dc/elements/1.1/", "dc": "http://purl.org/dc/elements/1.1/",
"dc": "http://purl.org/dc/elements/1.1/",
"ex": "http://example.org/vocab#", "ex": "http://example.org/vocab#",,
"ex": "http://example.org/vocab#",
"contains": {“@id”: “ex:contains”, "@type": "@id", "contains": {“@id”: “ex:contains”, "@type": "@id"
"contains": {"@type": "@id"}
“title”: “dc:title” “title”: “dc:title”
},
}, },
"@graph": [{
"@type": "ex:Library", "@graph": [{
"@id": "http://example.org/test/#library", "@id": "http://example.org/test/#library",
+
"@type": "ex:Library", "contains": {
"@type": "ex:Book", "@type": "ex:Library",
"ex:contains": "http://example.org/test#book"
"contains": { "contains": {
}, {
"@type": "ex:Chapter" "@id": "http://example.org/test#book",
"@id": "http://example.org/test#book",
} "@type": "ex:Book",
"@type": "ex:Book",
} "dc:contributor": "Writer",
"dc:contributor": "Writer",
} "title": "My Book",
"dc:title": "My Book", "contains": {
"ex:contains": "http://example.org/test#chapter" "@id": "http://example.org/test#chapter",
}, { "@type": "ex:Chapter",
"@id": "http://example.org/test#chapter", "dc:description": "Fun",
"@type": "ex:Chapter", "title": "Chapter One"
"dc:description": "Fun", }
"dc:title": "Chapter One" }
}] }]
} }
JavaScript object path: data[‘@graph][0].contains.contains.title](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-38-320.jpg)



![{
Macros
"type": "User",
"followers": 35,
"name": "Gregg Kellogg",
"email": "gregg@kellogg-assoc.com",
• Transform information
"url": "https://api.github.com/users/
gkellogg",
"avatar_url": "...",
"id": 46296,
• Add @id to data
{
}
+
"login": "gkellogg"
• Other programmatic
transformations
"https://api.github.com/users/*": {
"$": {
"@context": {
"foaf": "http://xmlns.com/foaf/0.1/",
"foaf:depiction": {"@type": "@id"},
"gh": "https://api.github.com/vocabulary#"
},
"@id": [{"f:valueof": "login"},
{"f:prefix": "http://github.com/"}],
"@ns": {
"ns:default": "gh",
"ns:replace": {"avatar_url": "foaf:depiction", "name":
"foaf:name"}
},
"@only": ["avatar_url", "name", "followers"],
"@type": ["gh:User", "foaf:Person"]
}
}
}
* json-ld-macros courtesy of Antonio Garrote](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-42-320.jpg)
![{
Macros
"type": "User",
"followers": 35,
"name": "Gregg Kellogg",
"email": "gregg@kellogg-assoc.com",
• Transform information
"url": "https://api.github.com/users/
gkellogg",
"avatar_url": "...",
"id": 46296,
• Add @id to data
{
}
+
"login": "gkellogg"
• Other programmatic
transformations
"https://api.github.com/users/*": {
"$": {
"@context": {
{
"foaf": "http://xmlns.com/foaf/0.1/",
"@context": {
"foaf:depiction": {"@type": "@id"},
"foaf": "http://xmlns.com/foaf/0.1/",
"gh": "https://api.github.com/vocabulary#"
"foaf:depiction": {"@type": "@id"},
},
"gh": "https://api.github.com/
"@id": [{"f:valueof": "login"},
vocabulary#"
{"f:prefix": "http://github.com/"}],
},
"@ns": {
"@id": "https://api.github.com/users/
"ns:default": "gh",
gkellogg",
"ns:replace": {"avatar_url": "foaf:depiction", "name":
"@type": ["gh:User", “foaf:Person”],
"foaf:name"}
"foaf:name": "Gregg Kellogg",
},
"foaf:depiction": "http://...",
"@only": ["avatar_url", "name", "followers"],
“gh:followers”: 35
"@type": ["gh:User", "foaf:Person"]
}
}
}
* json-ld-macros courtesy of Antonio Garrote](https://image.slidesharecdn.com/semtech2012-120530122213-phpapp01/85/JSON-LD-JSON-for-Linked-Data-43-320.jpg)








The document discusses JSON-LD (JavaScript Object Notation for Linked Data), highlighting its structure for expressing linked data using self-describing messages. It outlines various features such as type definitions, context management, and property associations, along with practical examples like representing a person with their details. The emphasis is on using JSON's syntactic capabilities to create rich, interconnected data representations.



































































