Download as PDF, PPTX




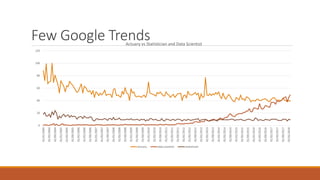



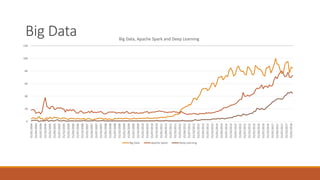





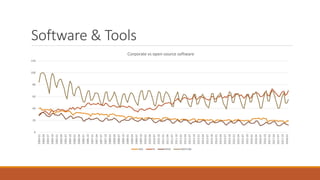






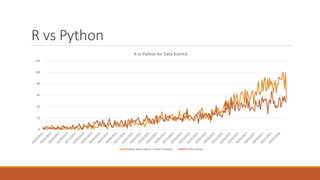






Giorgio Alfredo Spedicato will give a presentation on machine learning and actuarial science. He will review machine learning theory, including unsupervised and supervised learning algorithms. He will provide examples using various datasets, including using unsupervised learning on an auto insurance dataset and supervised learning for credit scoring and claim severity prediction. Spedicato has experience as a data scientist and actuary and holds a PhD in Actuarial Science.

























![[Eestec] Machine Learning online seminar 1, 12 2016](https://cdn.slidesharecdn.com/ss_thumbnails/eestecmachinelearningseminar1122016offline-161222133213-thumbnail.jpg?width=640&height=640&fit=bounds)























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
