Downloaded 99 times



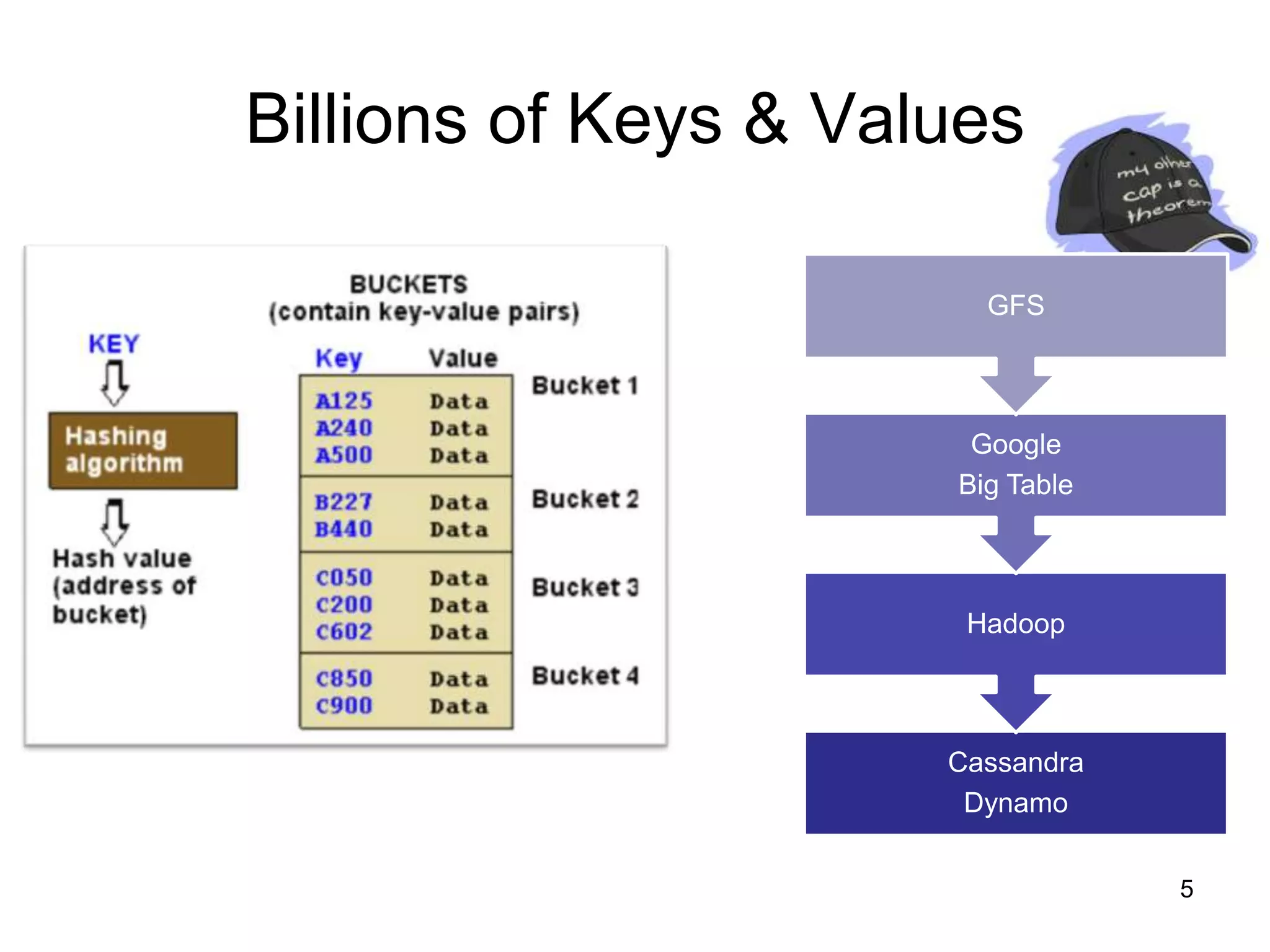


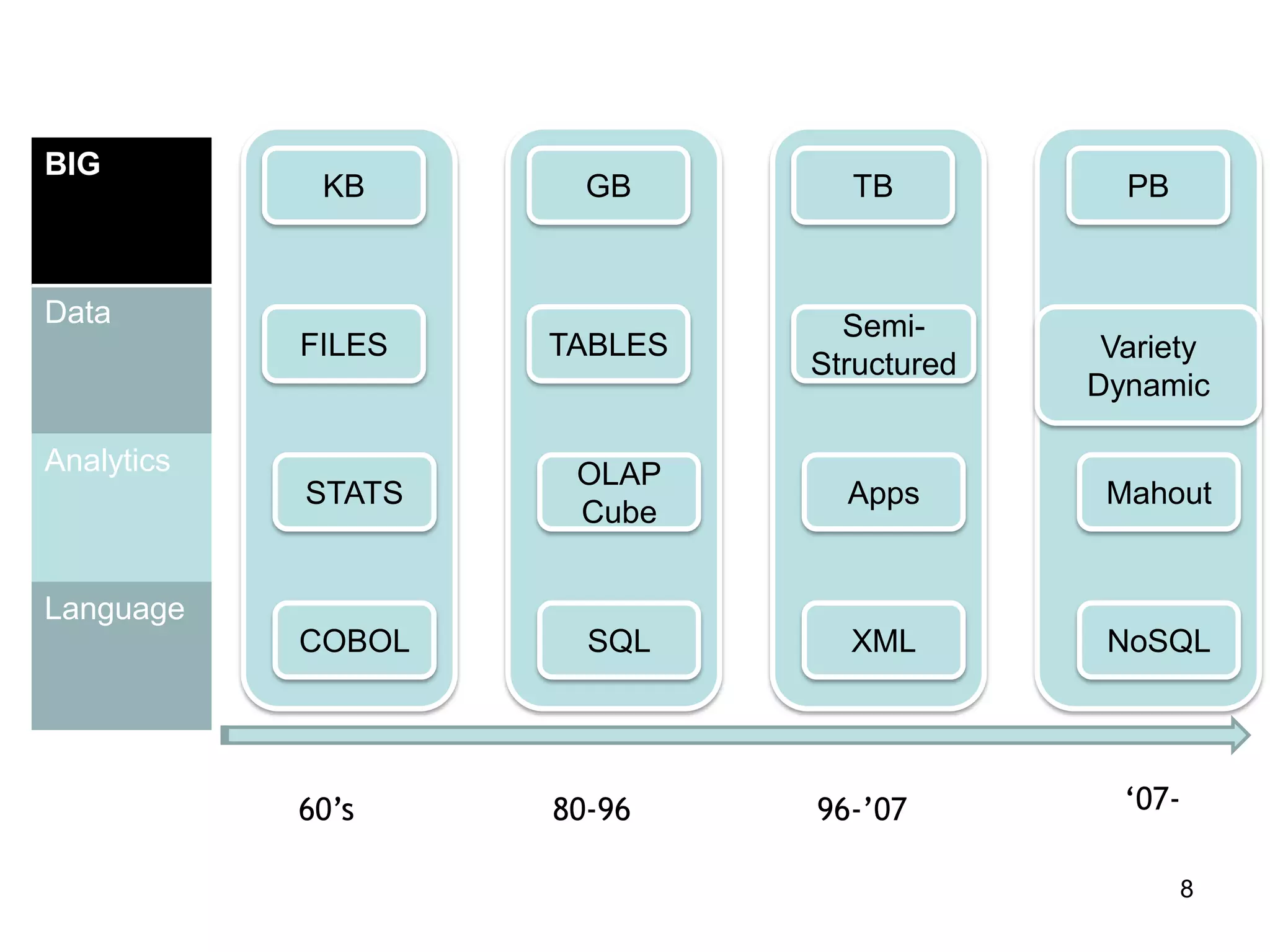


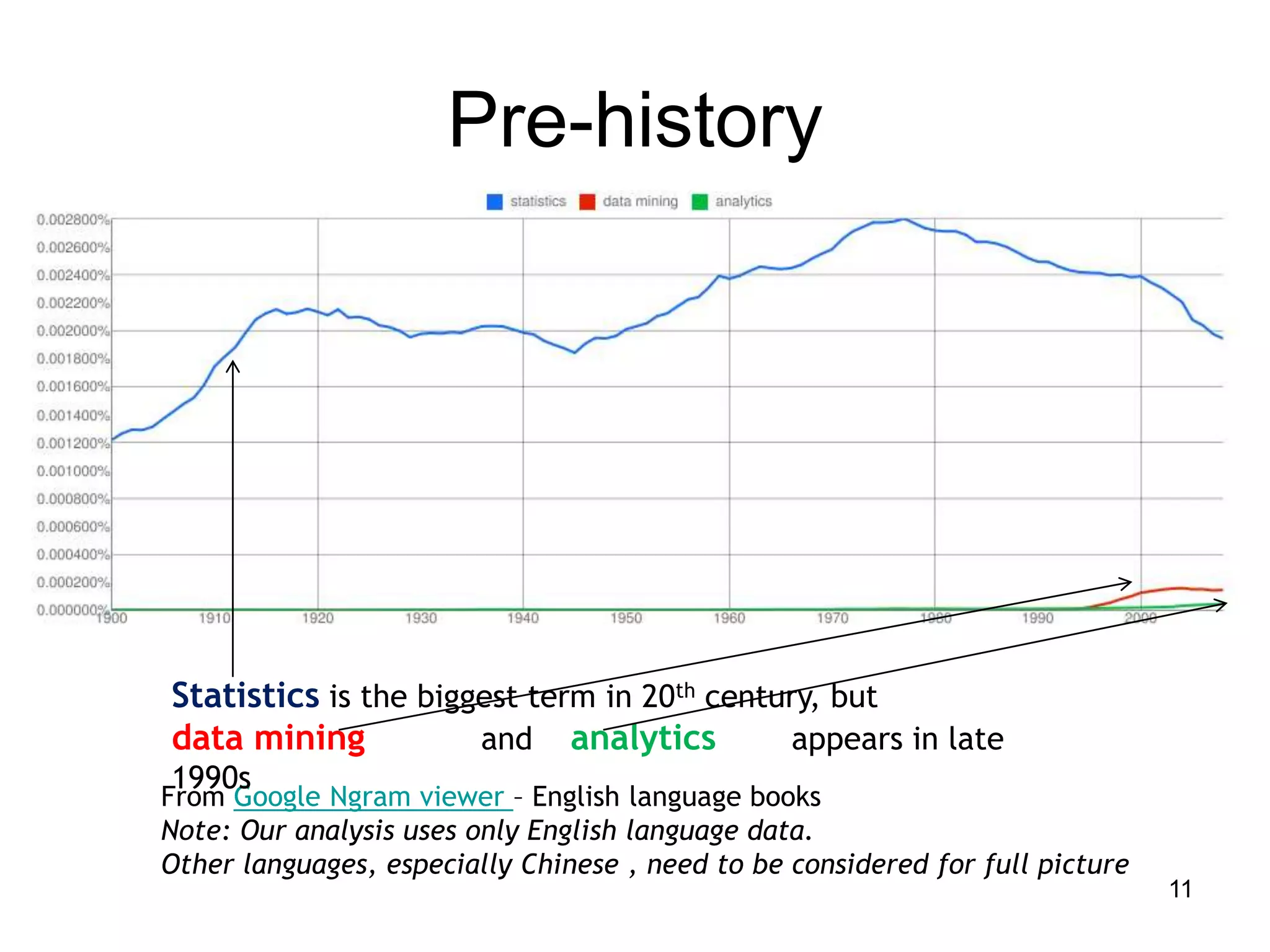
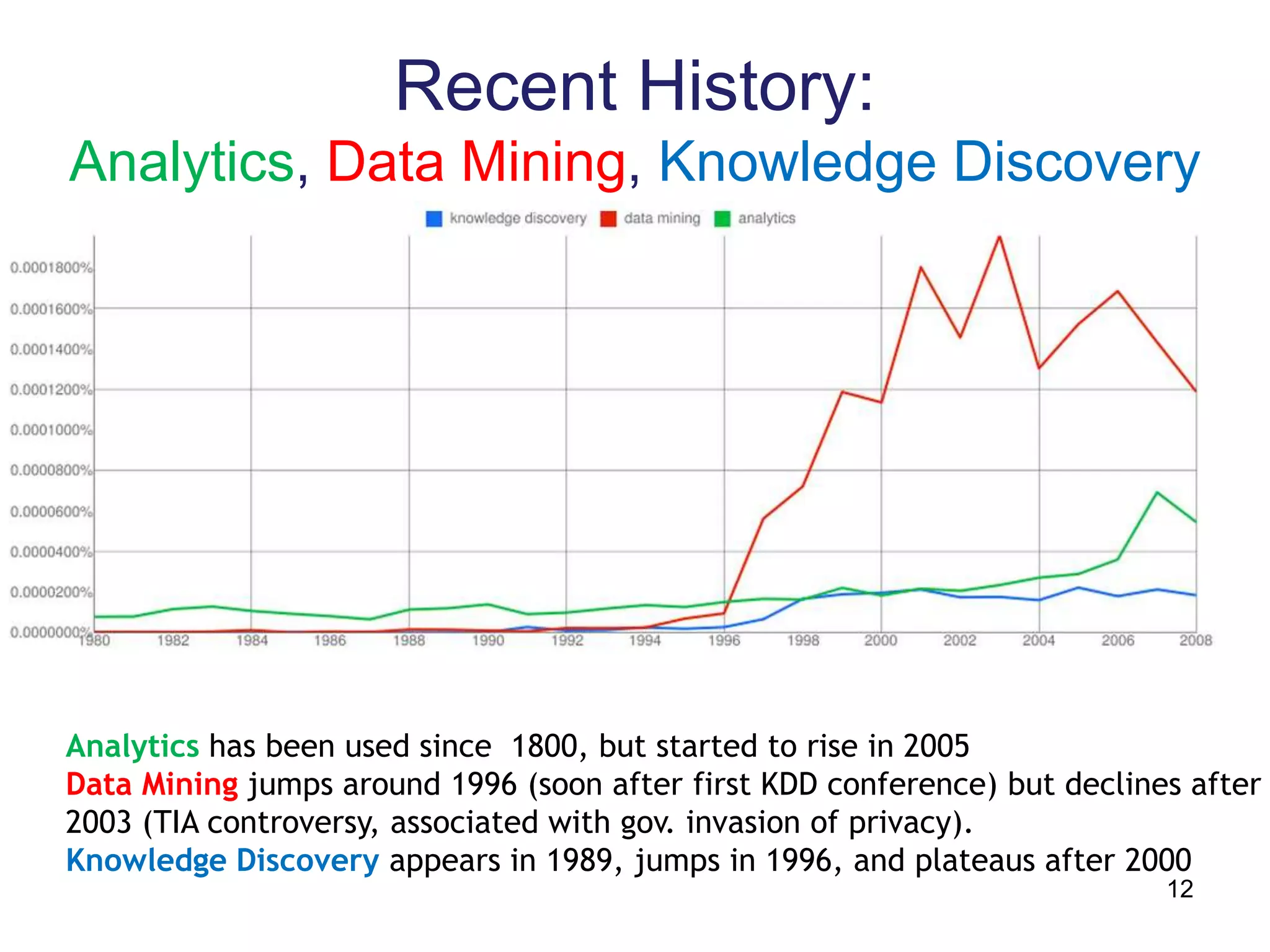
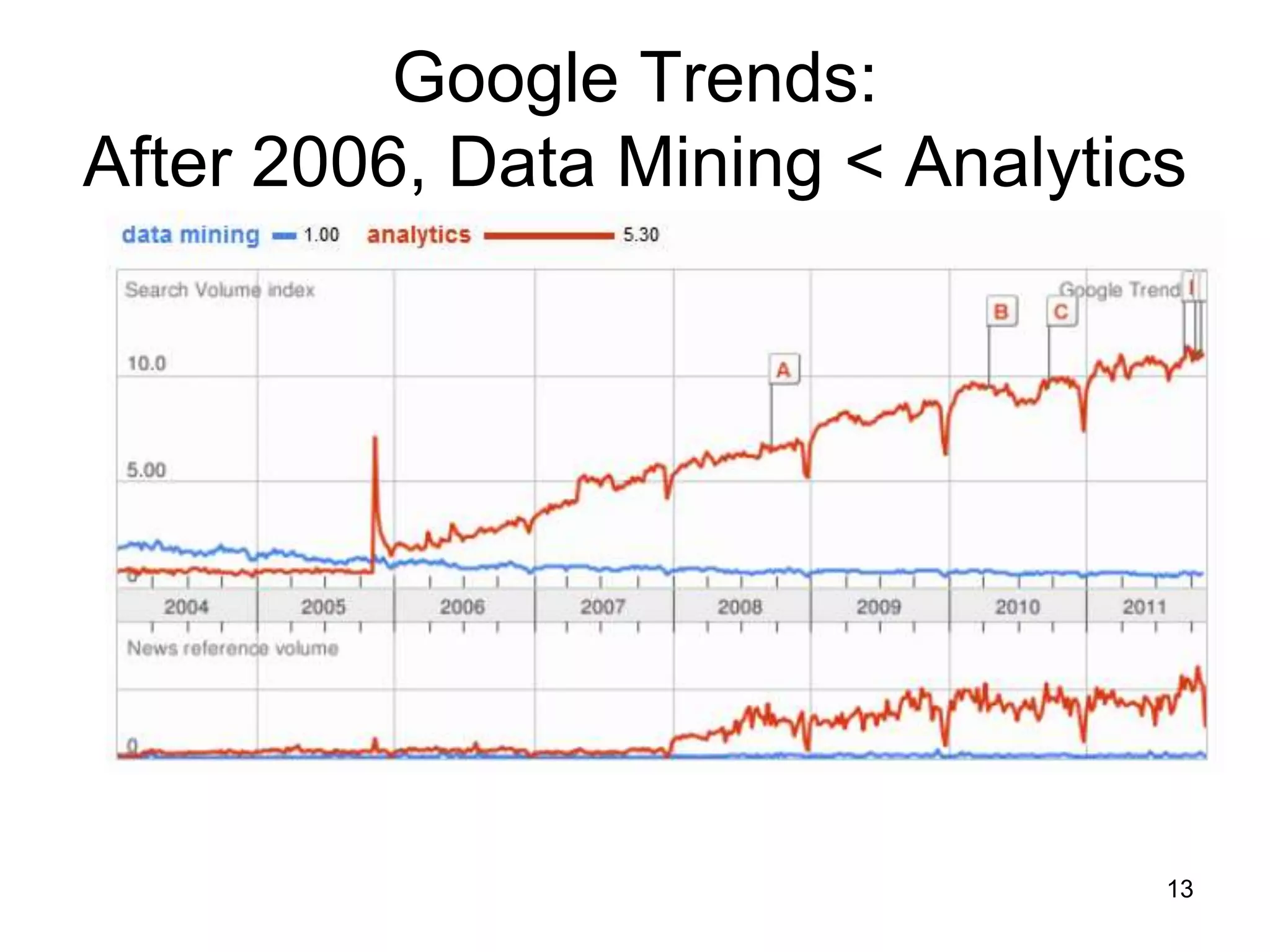

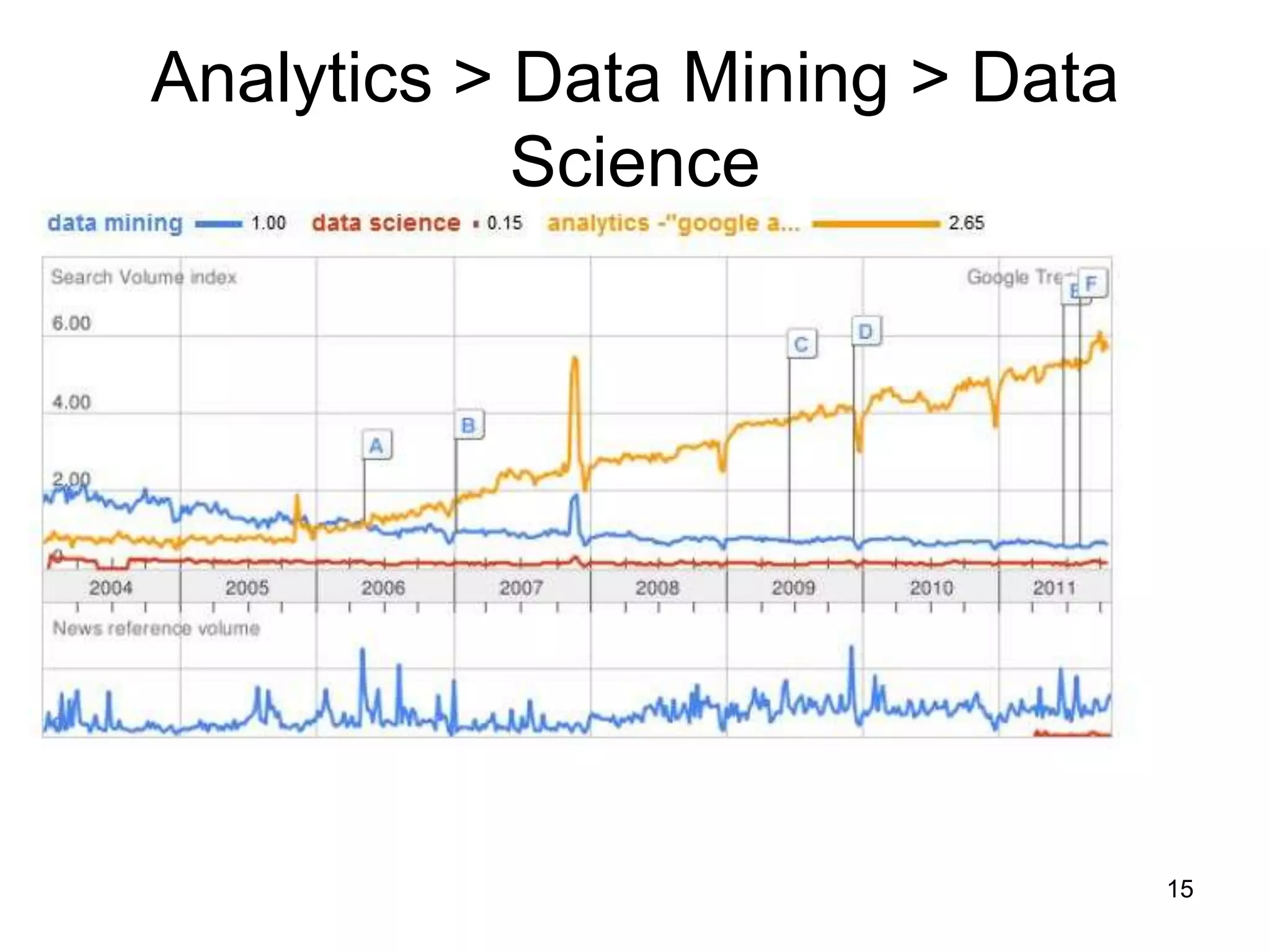
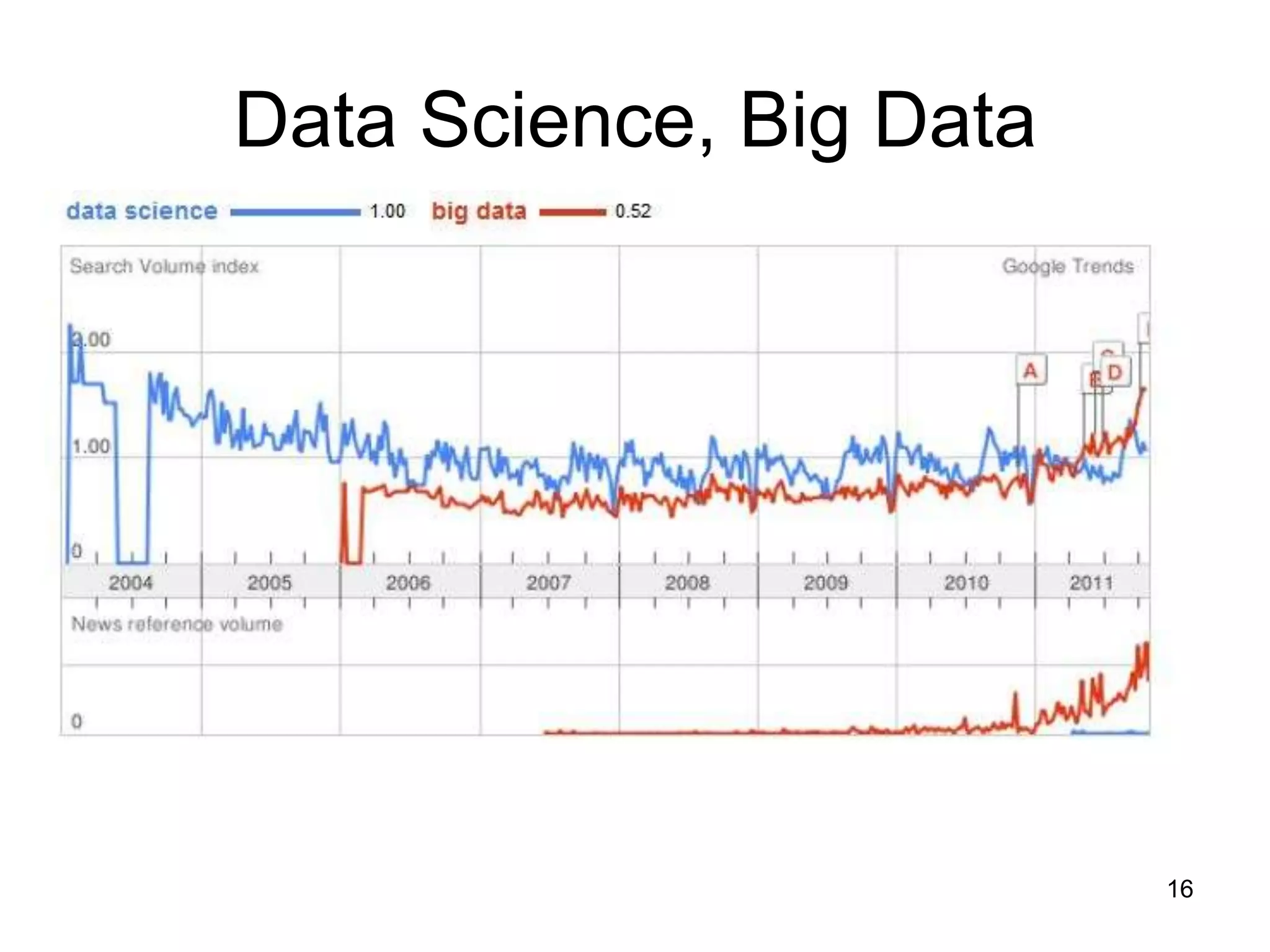
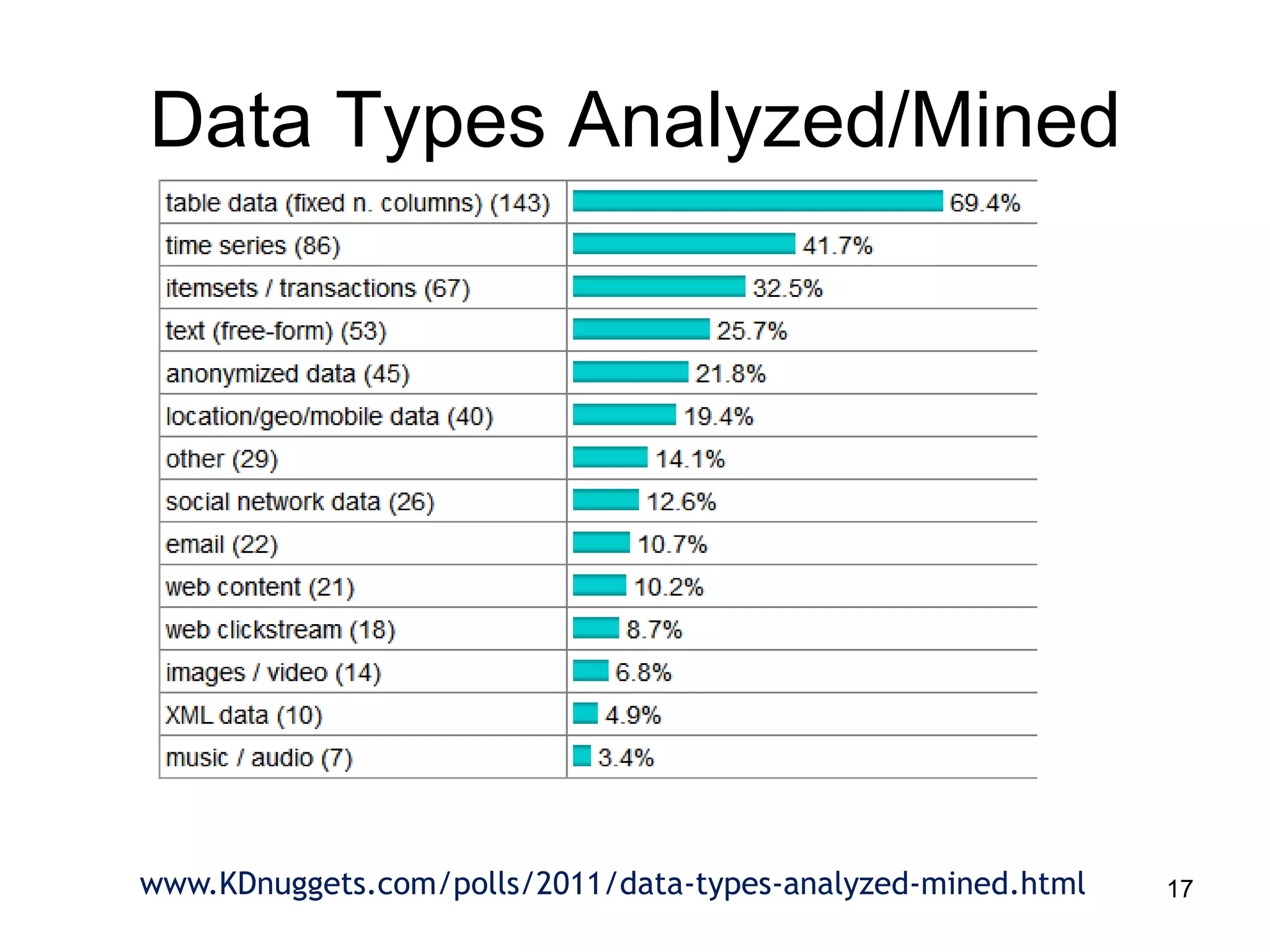
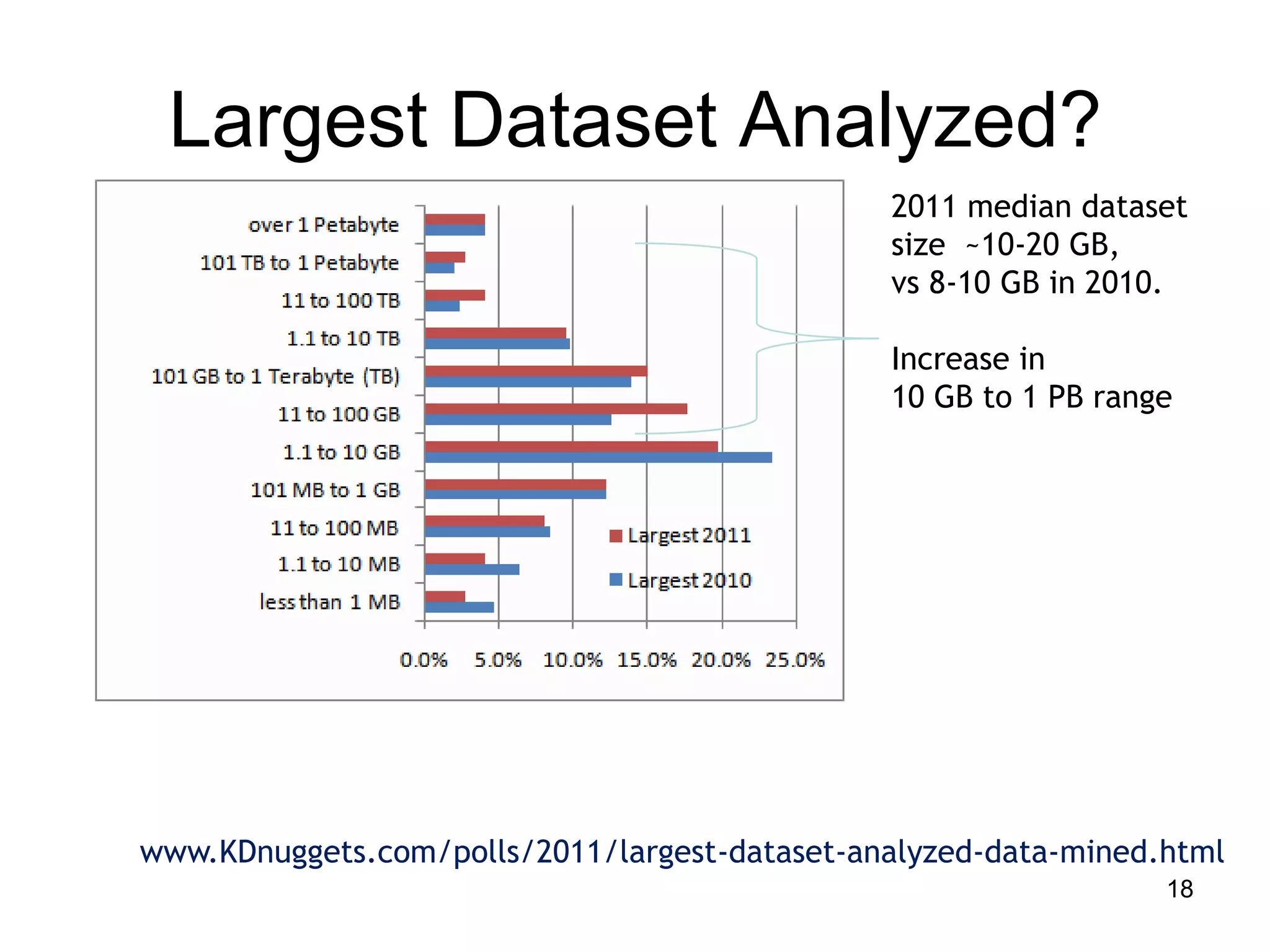
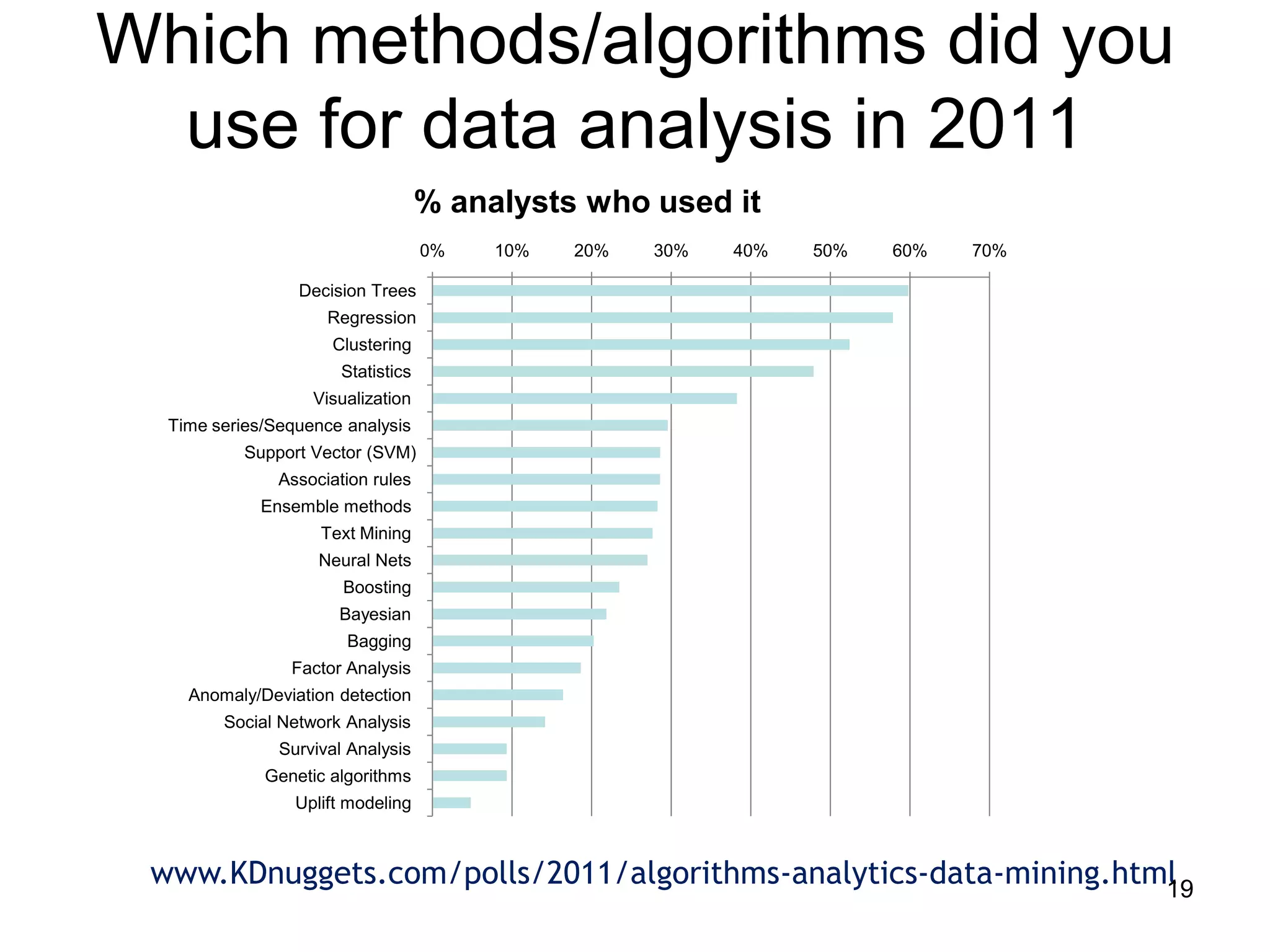
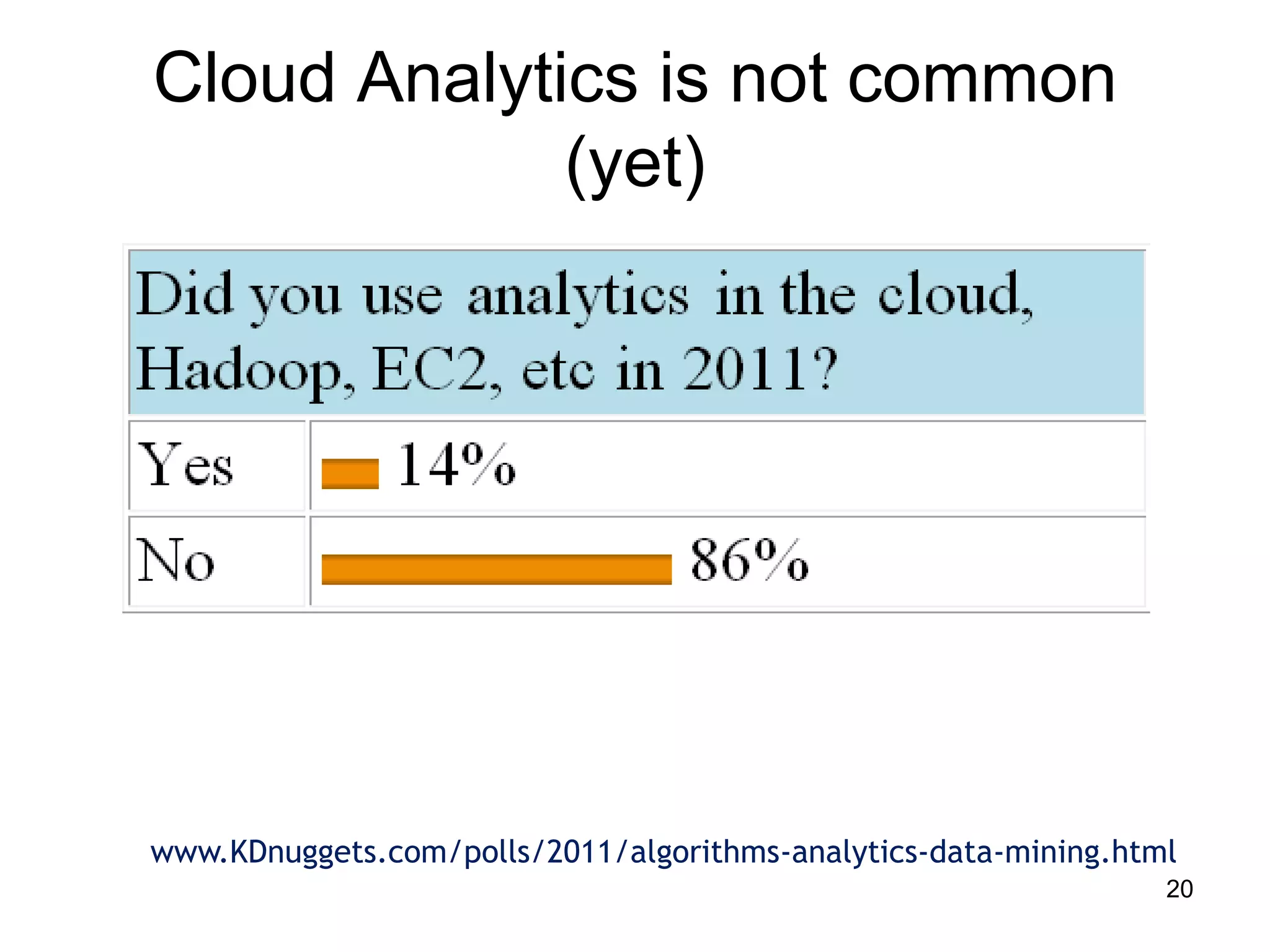




This document provides a high-level summary of NoSQL and Big Data: 1) It discusses the history of databases from COBOL to SQL and the development of NoSQL in response to the need to handle large, unstructured datasets. 2) It outlines some of the opportunities that NoSQL databases provide for storing and analyzing massive amounts of diverse data types. 3) It briefly mentions some examples of popular NoSQL databases like MongoDB, Cassandra, and DynamoDB that are well-suited for Big Data applications.

















































































