Downloaded 12 times












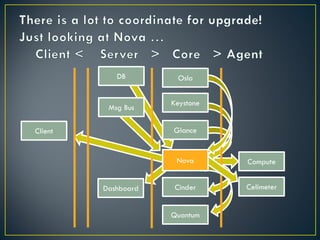
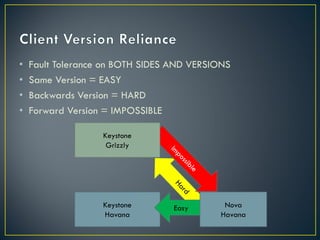
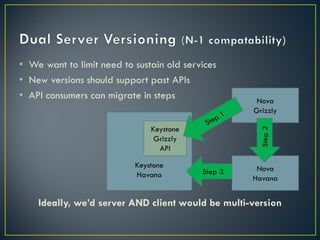
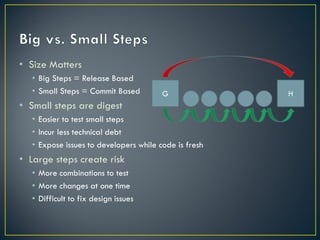
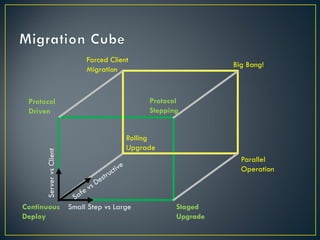
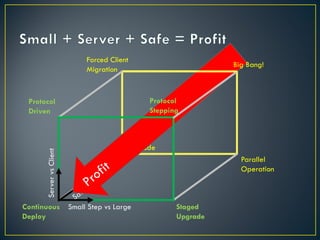
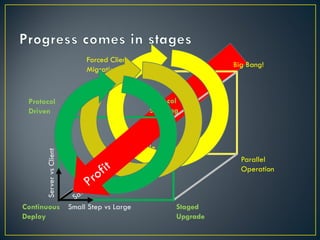



The document discusses several challenges and strategies for upgrading OpenStack deployments from one release to another. It notes that OpenStack has a rapid release cycle and emphasizes the importance of designing systems that can support rolling, continuous upgrades of components through multiple versions. Effective upgrade strategies require coordination between operations and development teams to ensure new versions maintain backward compatibility and upgrades can be tested in a controlled manner.




















![Perforce webinar clear-case_jb[2]](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-webinarclearcasejb2-171107142005-thumbnail.jpg?width=640&height=640&fit=bounds)
































![Open Patterns for Day 2 Ops [Gluecon 2017]](https://cdn.slidesharecdn.com/ss_thumbnails/gluecon2017-day2ops-170523221725-thumbnail.jpg?width=640&height=640&fit=bounds)













