













![Amazon design rules - 2
• It doesn’t matter what technology they[services]
use.
• All service interfaces, without exception, must be
designed from the ground up to be externalizable.
• Amazon is providing the specifications for what has
come to be called “Microservice Architecture”.
• (Its really an architectural style).
16](https://image.slidesharecdn.com/1-151126152050-lva1-app6891/85/Deploying-at-will-SEI-16-320.jpg)


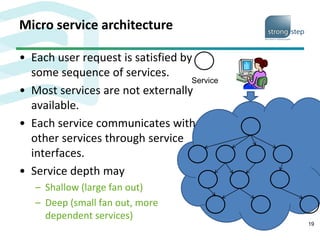







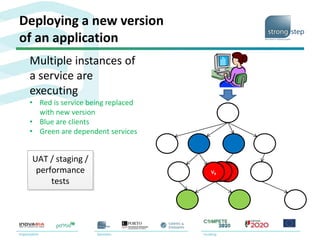


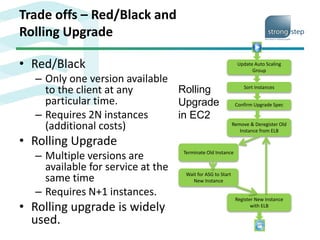








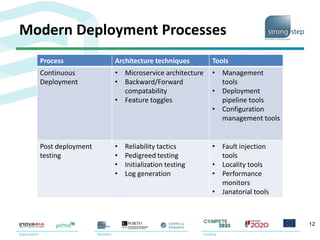
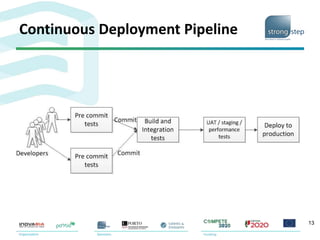
The document discusses the challenges and strategies associated with software deployment and release management, emphasizing the importance of continuous deployment to enhance efficiency and reduce time to market. It outlines Amazon's microservice architecture which allows independent team deployments through service interfaces, enabling flexibility and reducing coordination overhead. Key deployment strategies such as rolling upgrades and canary testing are presented, highlighting their benefits in maintaining service availability during upgrades.



































































































