Downloaded 93 times





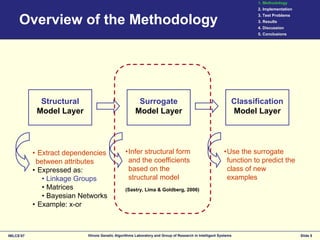





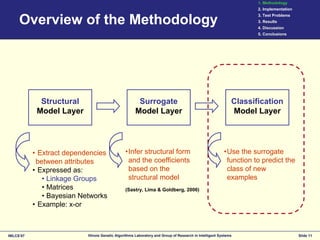

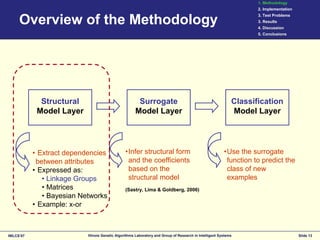



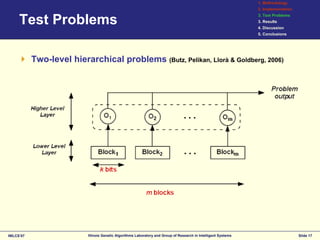




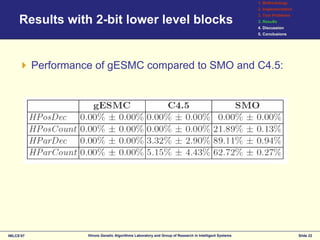









This document discusses the development of surrogates for decomposable classification problems using probabilistic models and regression techniques. It outlines a methodology for building structural surrogate models to classify new examples and evaluates their effectiveness through experiments on various test problems. The results indicate advantages of the proposed greedy extraction method over traditional approaches, although limitations and potential improvements are also identified.





































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















