Downloaded 38 times










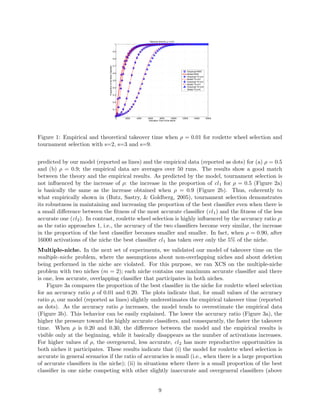
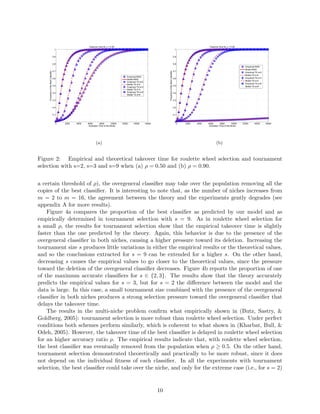
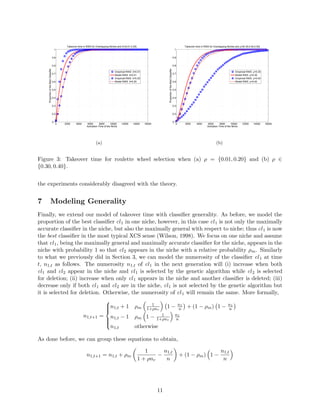
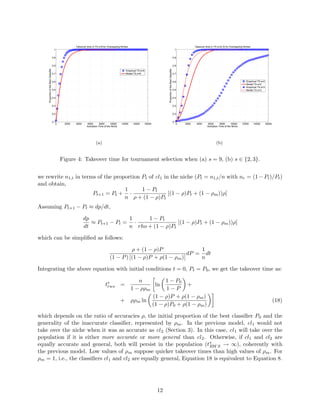


This paper models selection pressure in the XCS learning classifier system under both proportionate (roulette wheel) and tournament selection methods. The authors validate their models against simple problems, showing that the theoretical predictions align with empirical results when certain assumptions hold. Additionally, the findings provide insight into the dynamics of classifier populations and the conditions impacting their convergence.
































































































