Downloaded 26 times













![After the parsing process
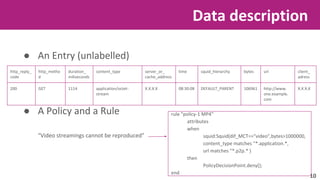
● A hash with the entries
○ Keys → Entry fields
○ Values → Field values
● A hash with the set of rules
○ Keys → Condition fields, and decision
○ Values → Name of the data type, its
desired value, relationship between them,
and allow, or deny.
%logdata = (
entry =>{
http_reply_code =>xxx
http_method =>xxx
duration_miliseconds =>xxx
content_type =>xxx
server_or_cache_address =>xxx
time =>xxx
squid_hierarchy =>xxx
bytes =>xxx
url =>xxx
client_address =>xxx
},
);
%rules = (
rule =>{
field =>xxx
relation =>xxx
value =>xxx
decision =>[allow, deny]
},
);
13](https://image.slidesharecdn.com/applyingsoftcomputingtechniquestocorporatemobilesecuritysystems-140921120849-phpapp01/85/Applying-soft-computing-techniques-to-corporate-mobile-security-systems-16-320.jpg)





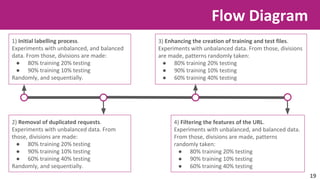
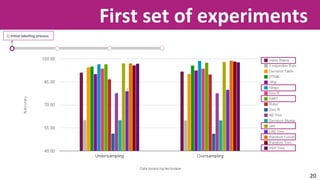

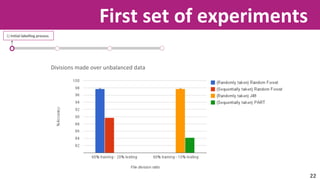
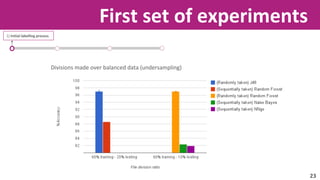
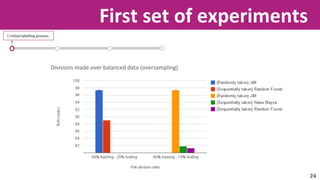

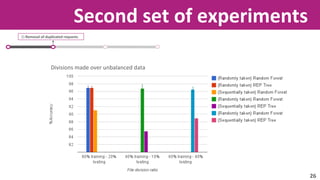

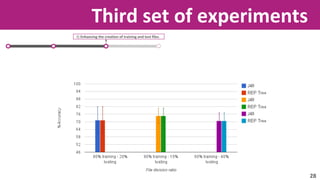



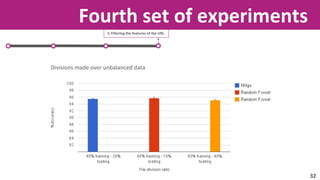
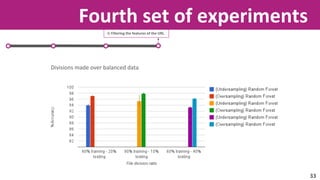










The document discusses the application of soft computing techniques to enhance corporate mobile security by automatically making decisions about URL access based on various parameters beyond traditional blacklists and whitelists. It outlines the research objectives, experimental setup, and results involving classifiers tested on a log file dataset, detailing the data mining process, machine learning methodologies, and future work to improve URL request classification. The findings suggest a potential system for real-time URL access control while contributing to the fields of computational intelligence and corporate security.


































































