Download as PDF, PPTX











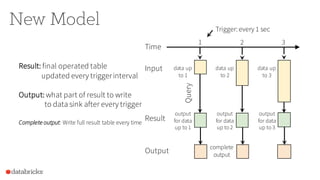





![Streaming ETL with DataFrames
1 2 3
Result
[append-only table]
Input
Output
[append mode]
new rows
in result
of 2
new rows
in result
of 3
input = spark.read
.format("json")
.stream("source-path")
result = input
.select("device", "signal")
.where("signal > 15")
result.write
.format("parquet")
.startStream("dest-path")](https://image.slidesharecdn.com/adeepdiveintostructuredstreaming-sparksummit2016-160608164257/85/Apache-Spark-2-0-A-Deep-Dive-Into-Structured-Streaming-by-Tathagata-Das-18-320.jpg)










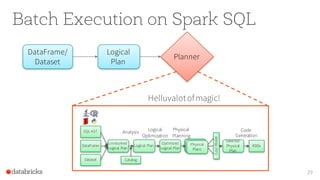


![Continuous Incremental Execution
32
Planner
Incremental
Execution 2
Offsets:[106-197] Count: 92
Plannerpollsfor
new data from
sources
Incremental
Execution 1
Offsets:[19-105] Count: 87
Incrementally executes
new data and writesto sink](https://image.slidesharecdn.com/adeepdiveintostructuredstreaming-sparksummit2016-160608164257/85/Apache-Spark-2-0-A-Deep-Dive-Into-Structured-Streaming-by-Tathagata-Das-32-320.jpg)
![Continuous Aggregations
Maintain runningaggregate as in-memory state
backed by WAL in file system for fault-tolerance
33
state data generated and used
across incremental executions
Incremental
Execution 1
state:
87
Offsets:[19-105] Running Count: 87
memory
Incremental
Execution 2
state:
179
Offsets:[106-179] Count: 87+92 = 179](https://image.slidesharecdn.com/adeepdiveintostructuredstreaming-sparksummit2016-160608164257/85/Apache-Spark-2-0-A-Deep-Dive-Into-Structured-Streaming-by-Tathagata-Das-33-320.jpg)








![Release Plan: Spark 2.0 [June 2016]
Basic infrastructureand API
- Eventtime, windows,aggregations
- Append and Complete output modes
- Support for a subsetof batch queries
Sourceand sink
- Sources: Files(*Kafka coming soon
after 2.0 release)
- Sinks: Filesand in-memory table
Experimental release to set
the future direction
Not ready for production
but good to experiment
with and provide feedback](https://image.slidesharecdn.com/adeepdiveintostructuredstreaming-sparksummit2016-160608164257/85/Apache-Spark-2-0-A-Deep-Dive-Into-Structured-Streaming-by-Tathagata-Das-43-320.jpg)




The document discusses structured streaming in Apache Spark, focusing on its development, features, and enhancements introduced in Spark 2.0 and beyond. It highlights the transition from traditional streaming apps to a unified model that simplifies the handling of batch and streaming data while offering advanced capabilities like continuous processing and fault tolerance. The presentation emphasizes practical use cases in IoT and machine learning, showcasing how structured streaming improves analytics and query management.























































































