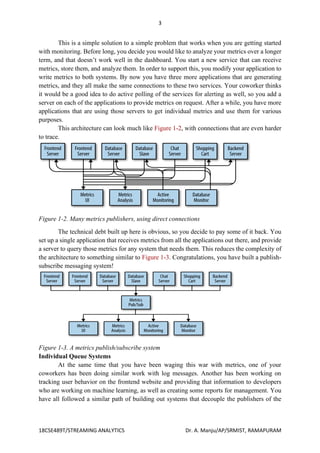
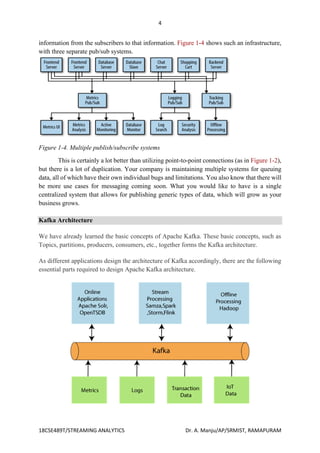
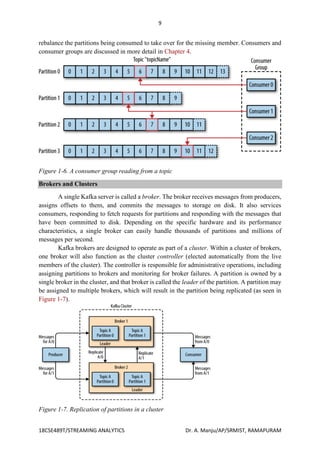
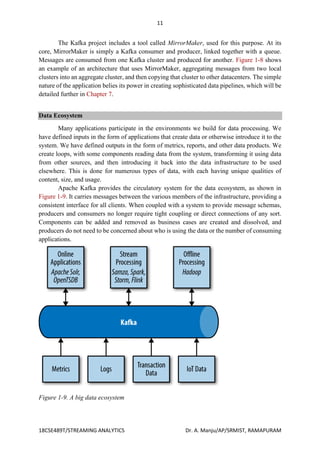
The document details the architecture and functionality of Apache Kafka, focusing on its publish/subscribe messaging model, including components like producers, consumers, brokers, topics, and partitions. It highlights Kafka's ability to handle multiple producers and consumers while ensuring durable message retention, scalability, and high performance. Additionally, it discusses how messages are structured, stored, and consumed in Kafka's ecosystem, emphasizing the advantages of using a centralized messaging system for data processing.

























![29
18CSE489T/STREAMING ANALYTICS Dr. A. Manju/AP/SRMIST, RAMAPURAM
Example application development with Kafka Streams
Word Count
Let’s walk through an abbreviated word count example for Kafka Streams. You can find the
full example on GitHub.
The first thing you do when creating a stream-processing app is configure Kafka Streams.
Kafka Streams has a large number of possible configurations, which we won’t discuss here,
but you can find them in the documentation. In addition, you can also configure the producer
and consumer embedded in Kafka Streams by adding any producer or consumer config to the
Properties object:
public class WordCountExample {
public static void main(String[] args) throws Exception{
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG,
"wordcount");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,
"localhost:9092");
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG,
Serdes.String().getClass().getName());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG,
Serdes.String().getClass().getName());
Every Kafka Streams application must have an application ID. This is used to coordinate the
instances of the application and also when naming the internal local stores and the topics related
to them. This name must be unique for each Kafka Streams application working with the same
Kafka cluster.
The Kafka Streams application always reads data from Kafka topics and writes its output to
Kafka topics. As we’ll discuss later, Kafka Streams applications also use Kafka for
coordination. So we had better tell our app where to find Kafka.
When reading and writing data, our app will need to serialize and deserialize, so we provide
default Serde classes. If needed, we can override these defaults later when building the streams
topology.
Now that we have the configuration, let’s build our streams topology:
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> source =
builder.stream("wordcount-input");
final Pattern pattern = Pattern.compile("W+");
KStream counts = source.flatMapValues(value->
Arrays.asList(pattern.split(value.toLowerCase())))
.map((key, value) -> new KeyValue<Object,
Object>(value, value))
.filter((key, value) -> (!value.equals("the")))
.groupByKey()
.count("CountStore").mapValues(value->
Long.toString(value)).toStream();](https://image.slidesharecdn.com/saunitii-241231054828-8d68d1e1/85/Streaming-Analytics-unit-2-notes-for-engineers-29-320.jpg)




































































