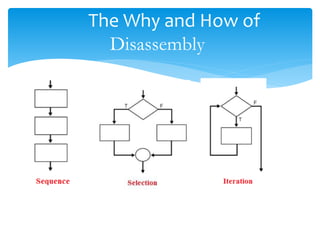
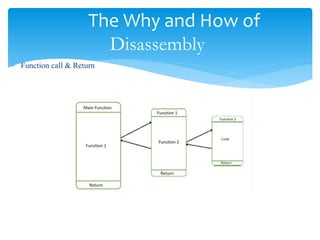
The document discusses disassembly theory, including first, second, and third generation languages. It then discusses the why and how of disassembly, including uses for malware analysis, vulnerability analysis, software interoperability, compiler validation, and debugging displays. It describes the basic process of disassembly and two common algorithms: linear sweep and recursive descent. Finally, it outlines some common reversing and disassembly tools like file, PE Tools, PEiD, nm, ldd, objdump, otool, and strings.