









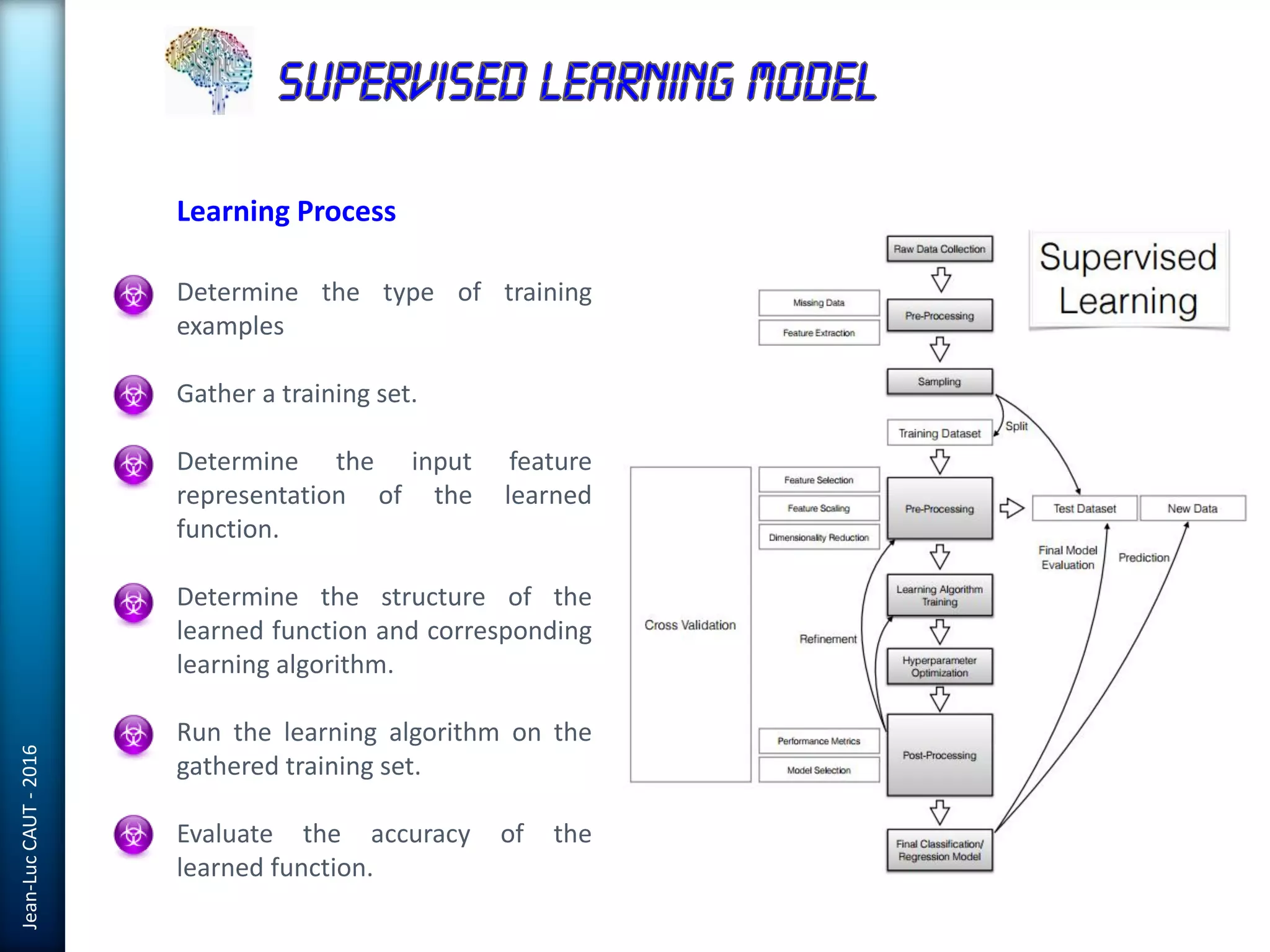
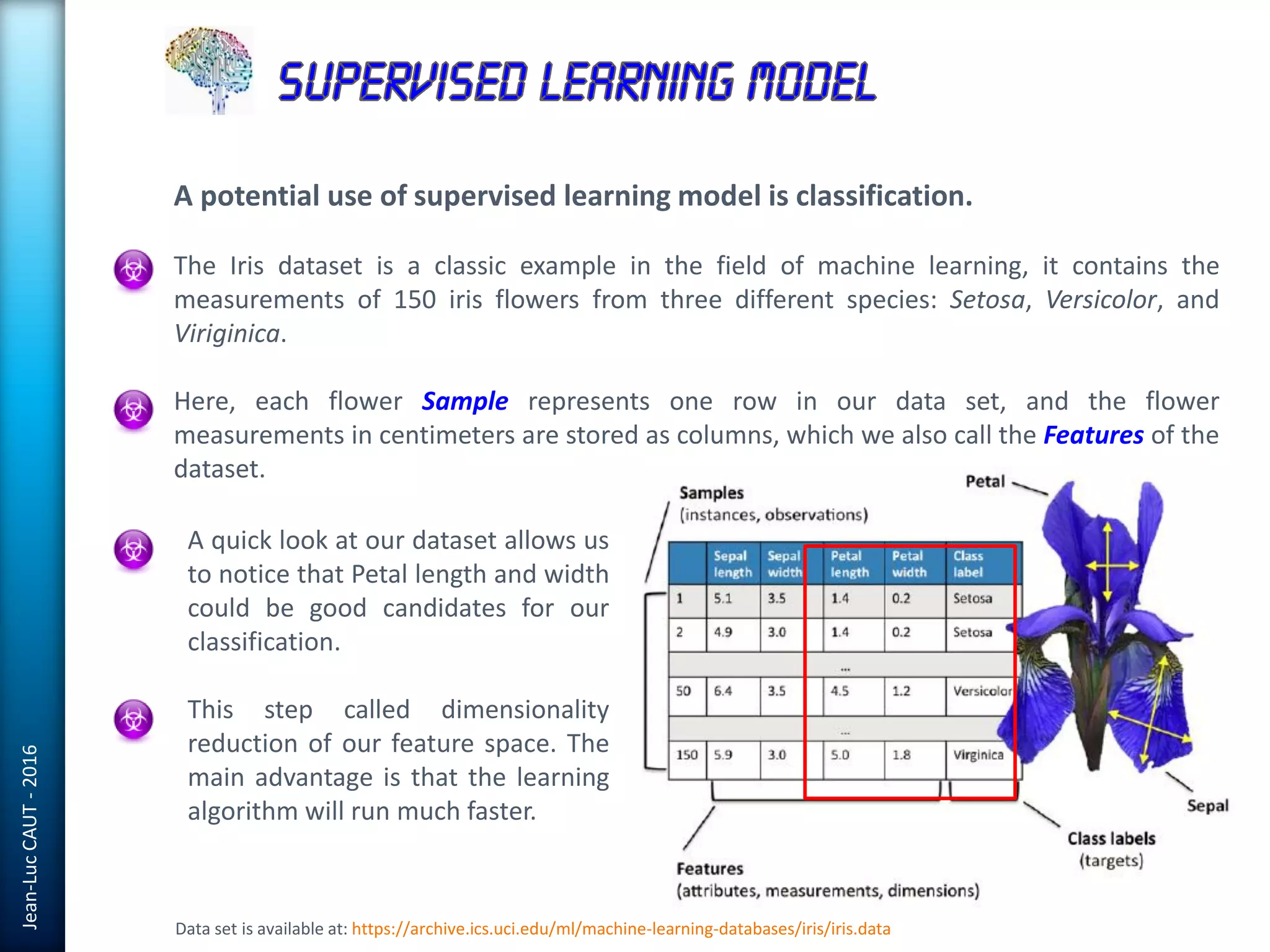




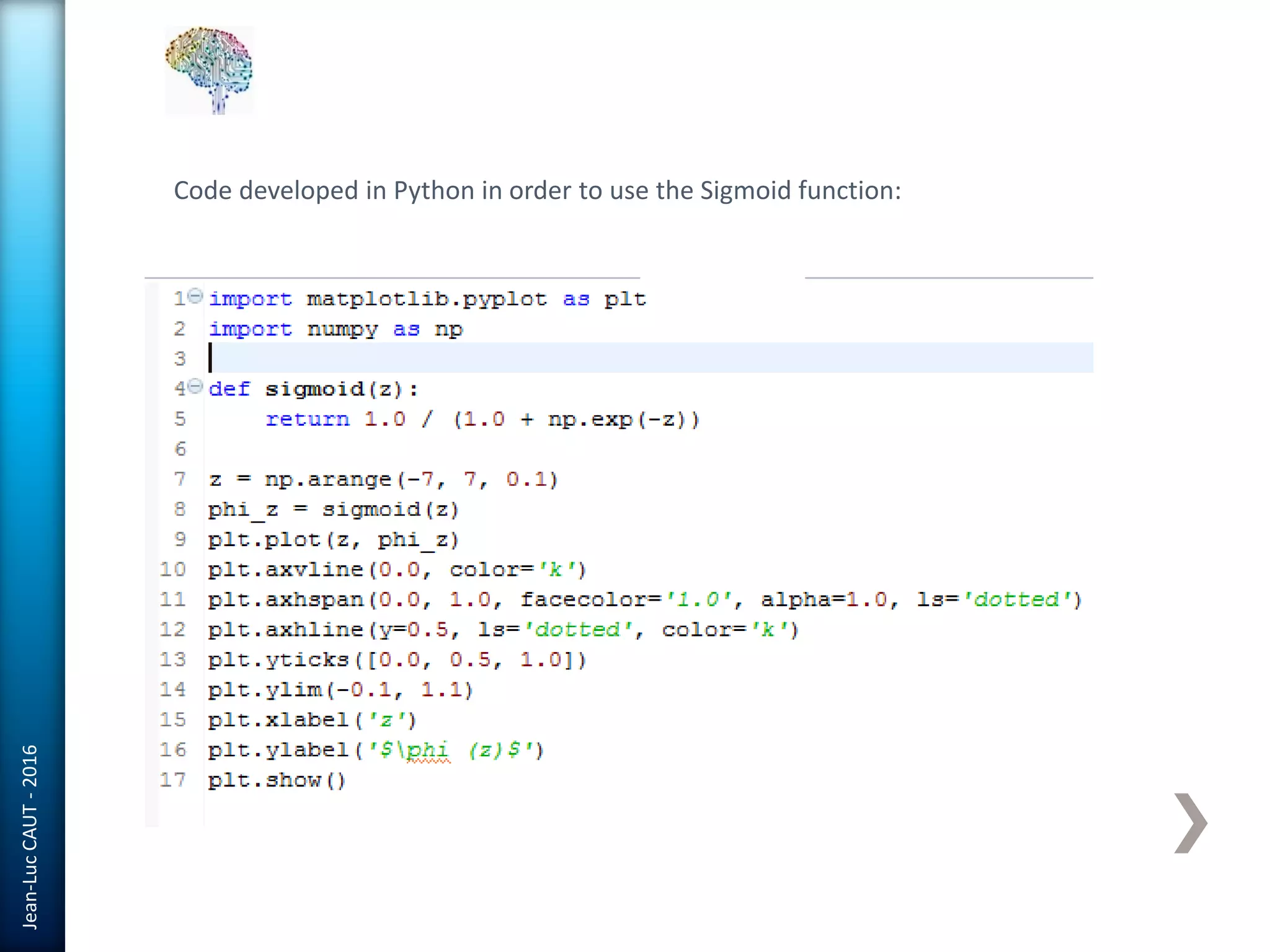

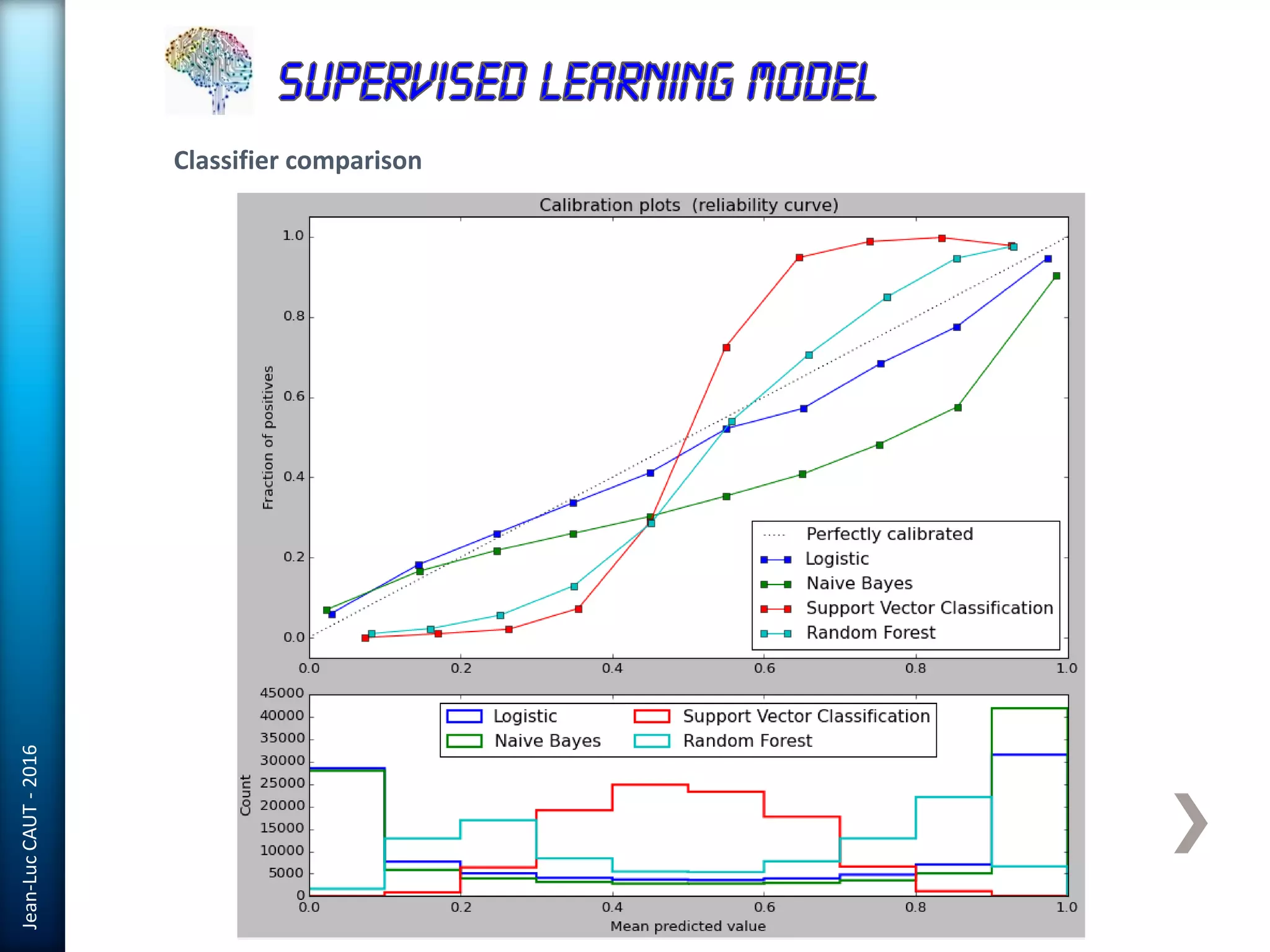
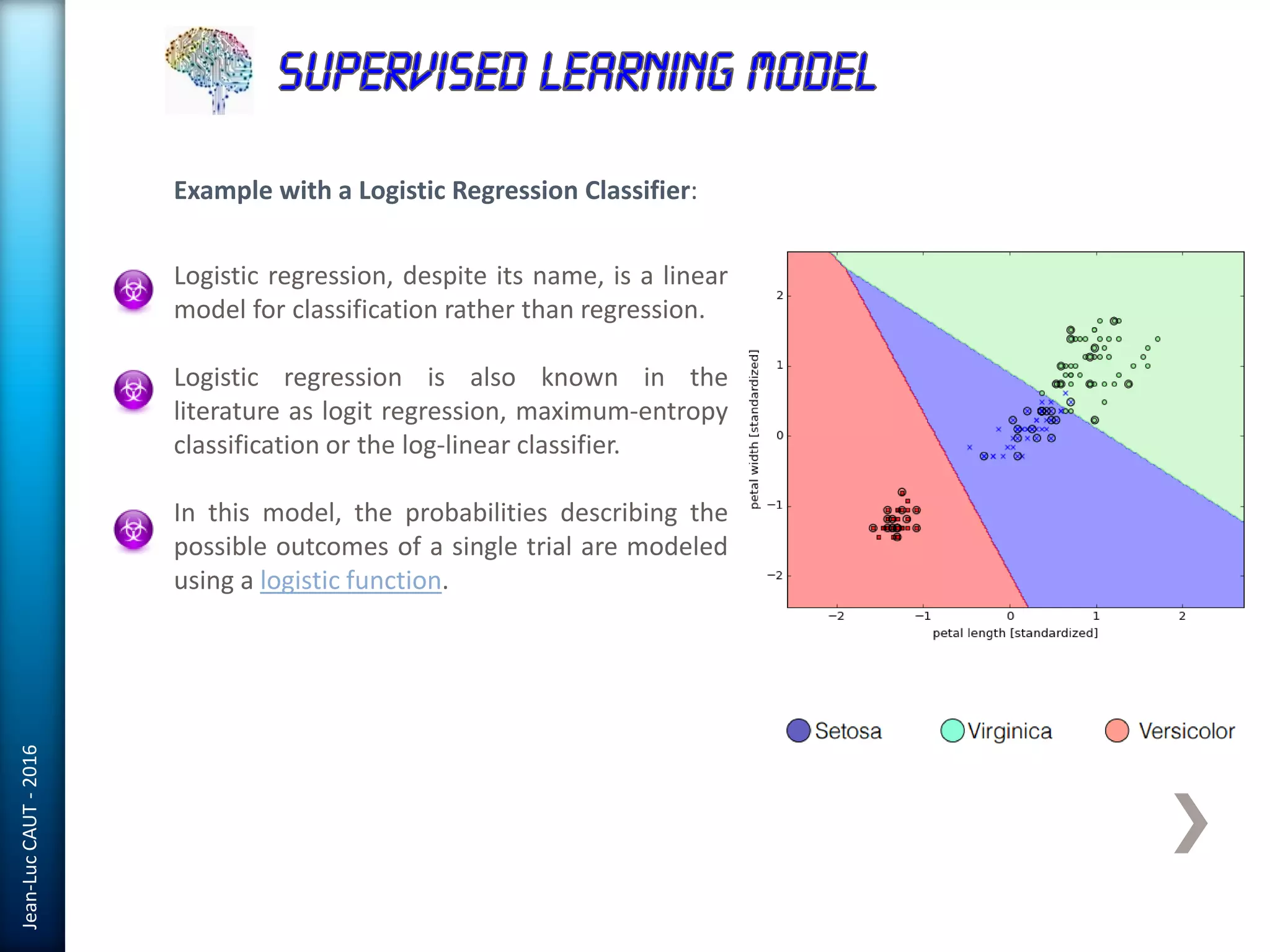







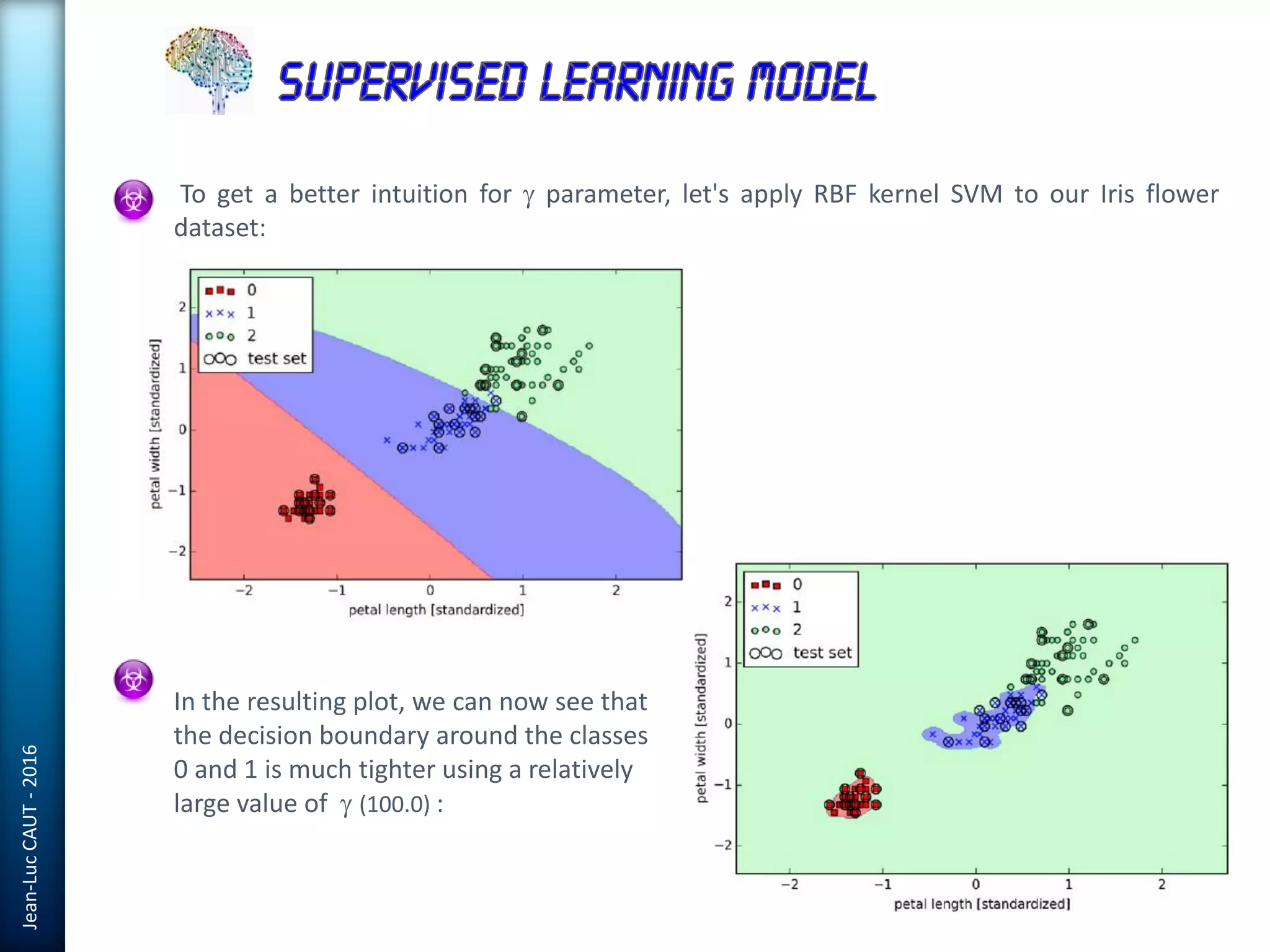
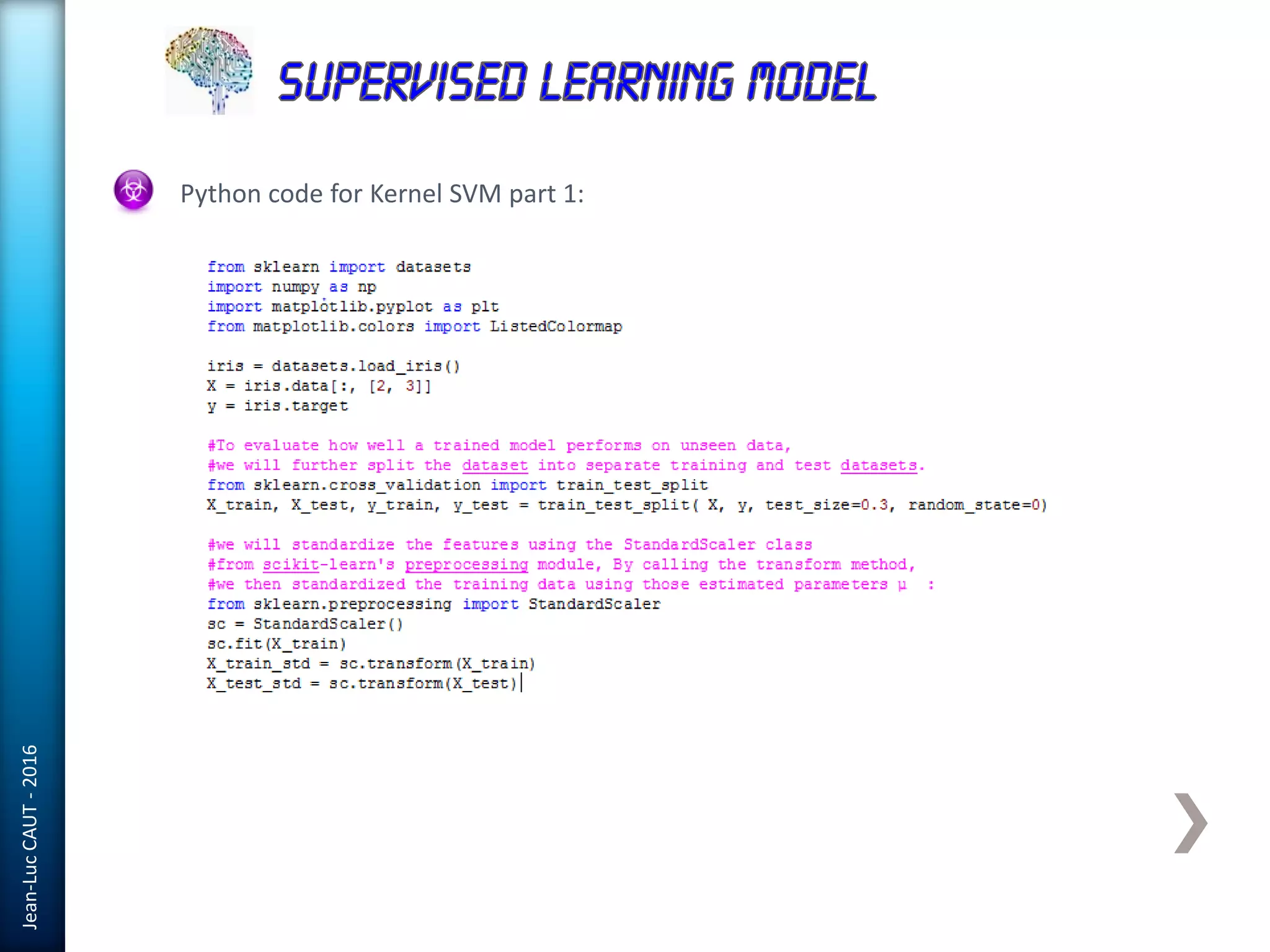
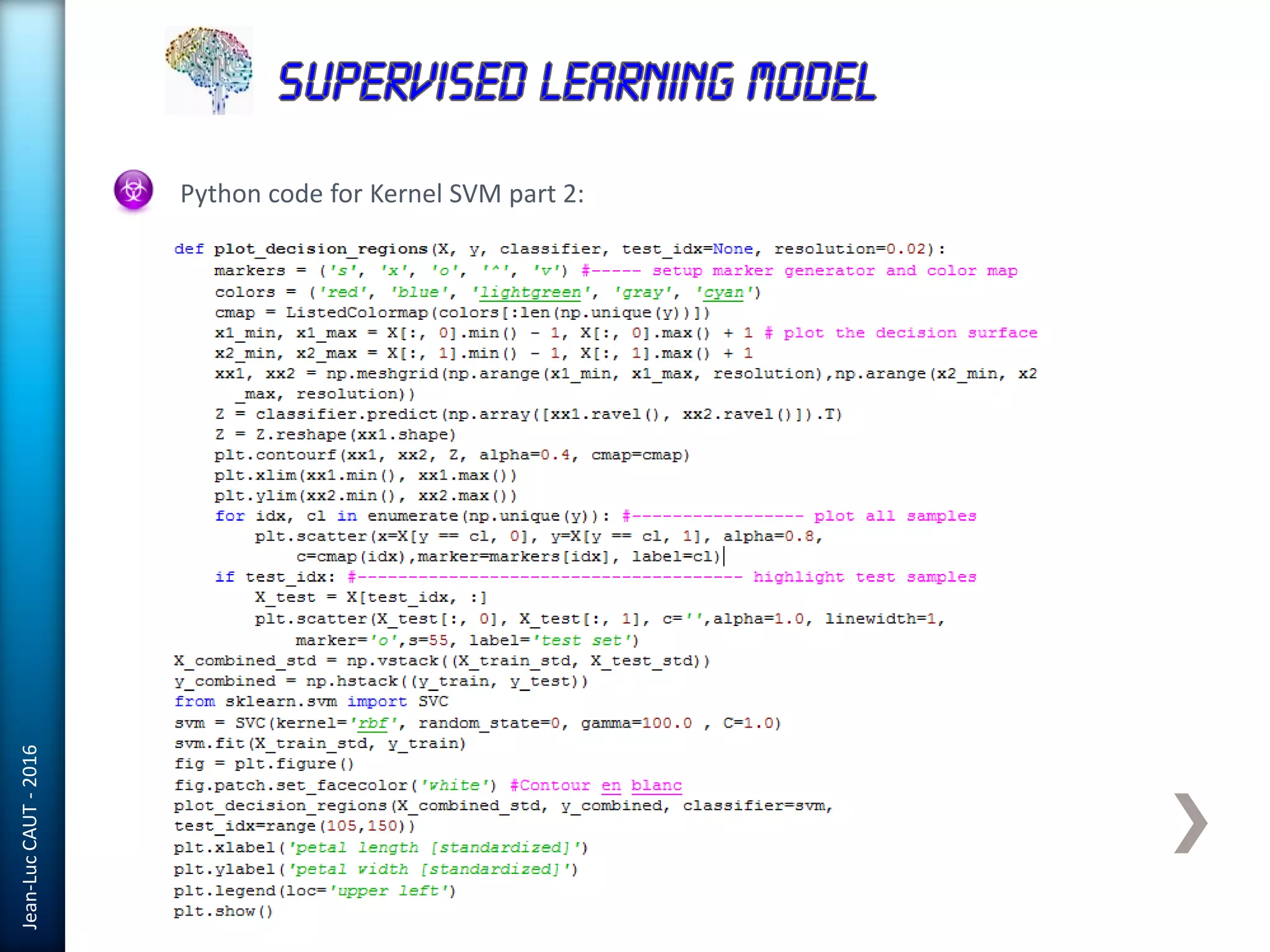







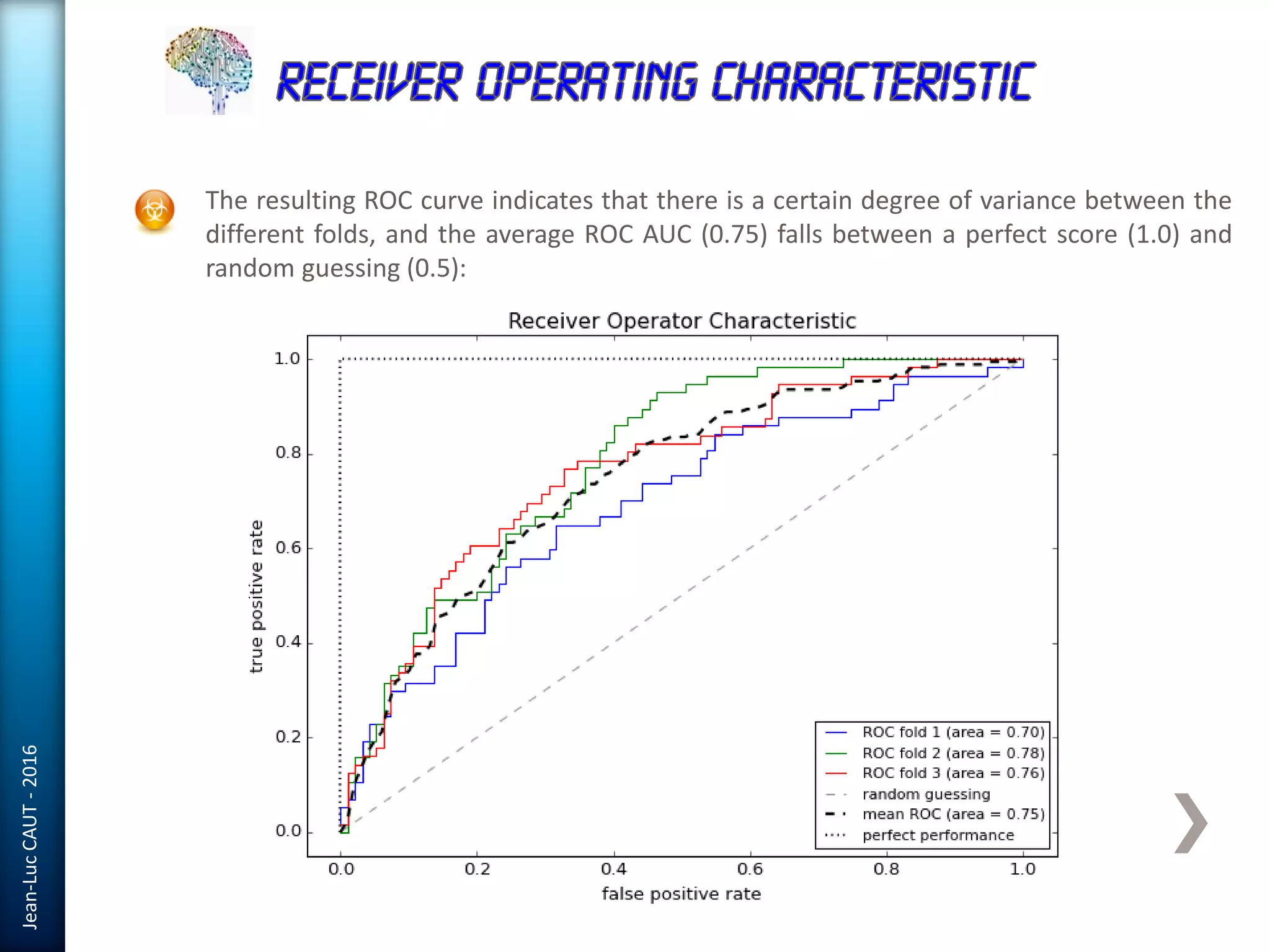

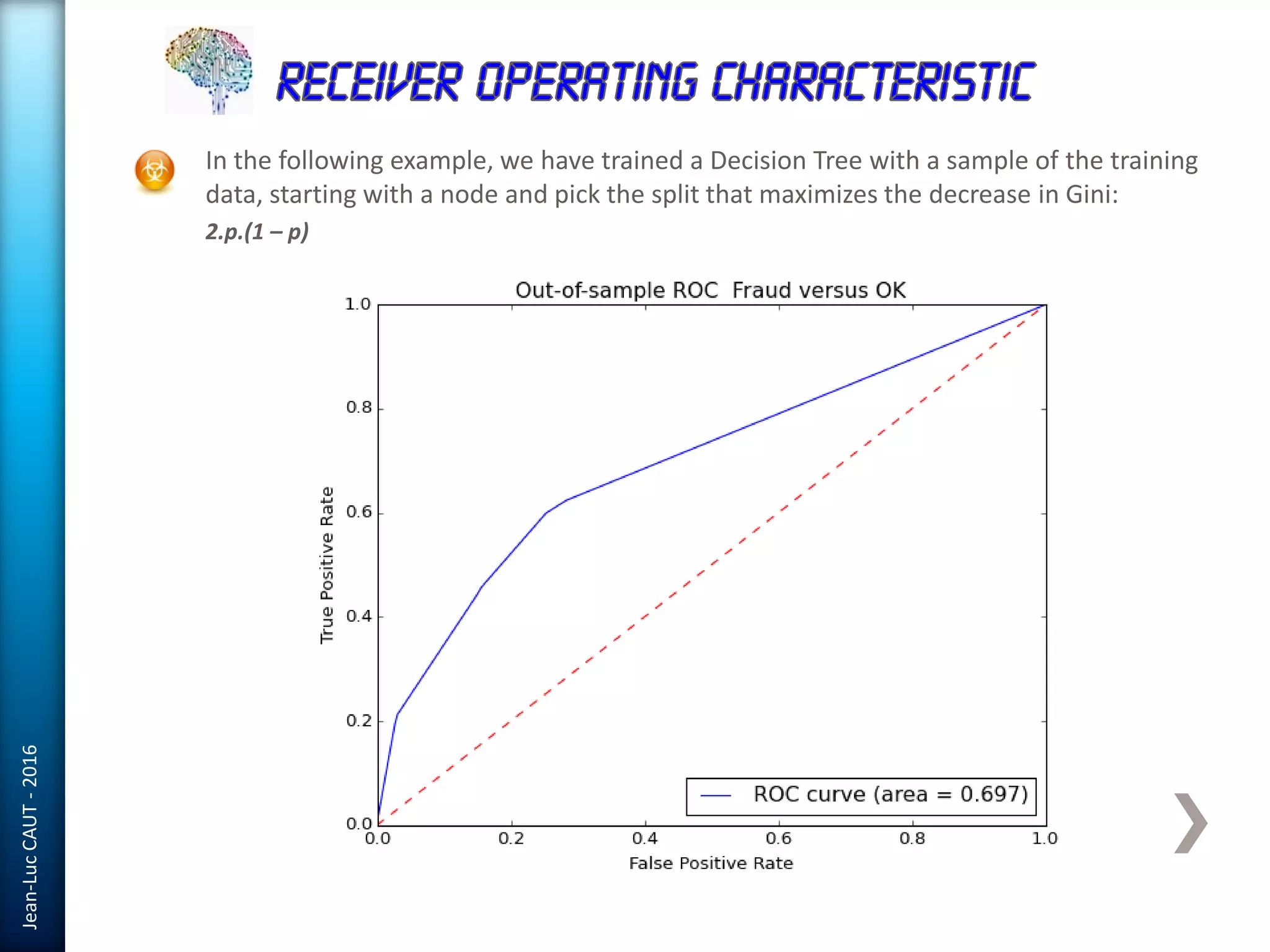

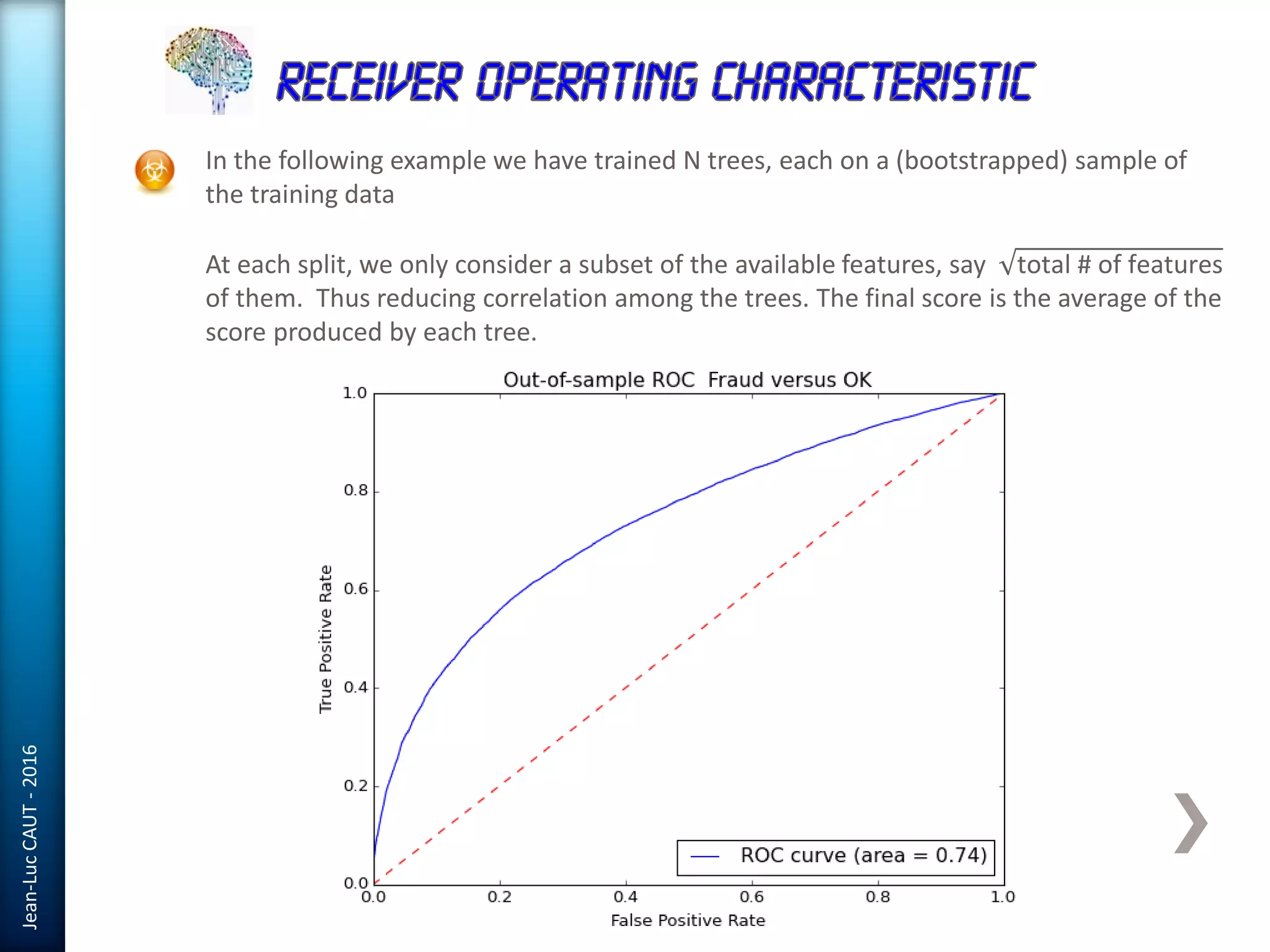
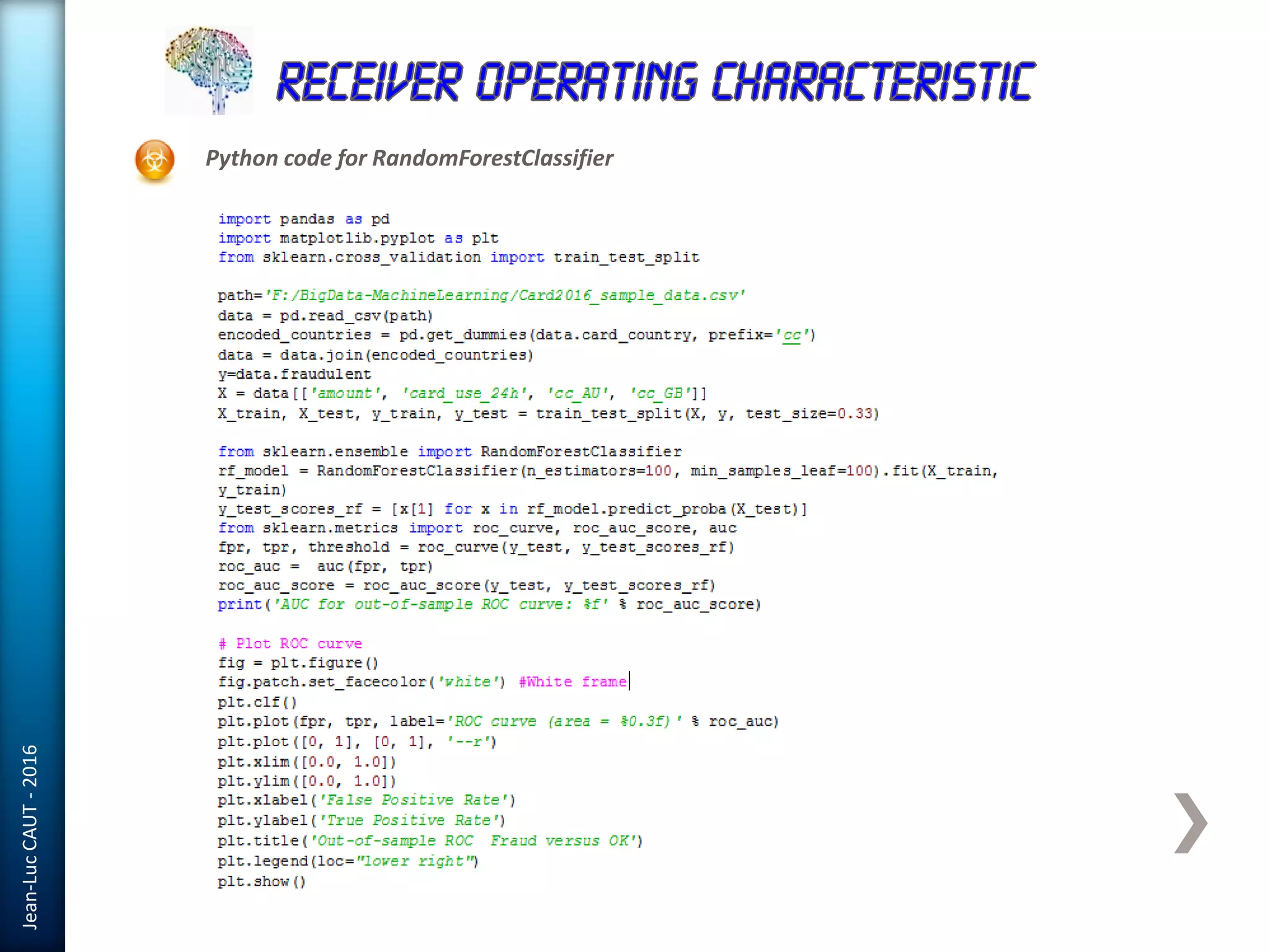

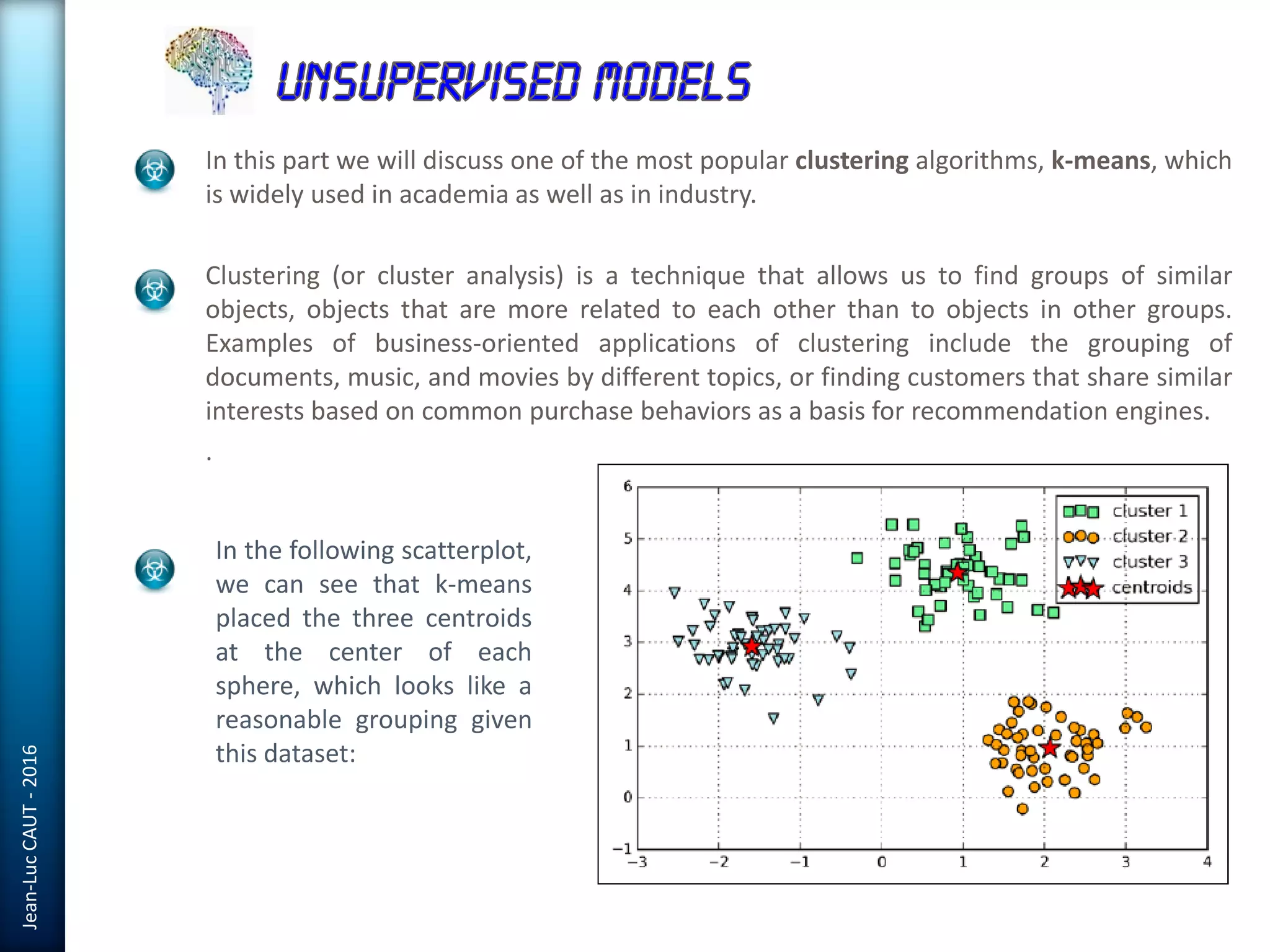

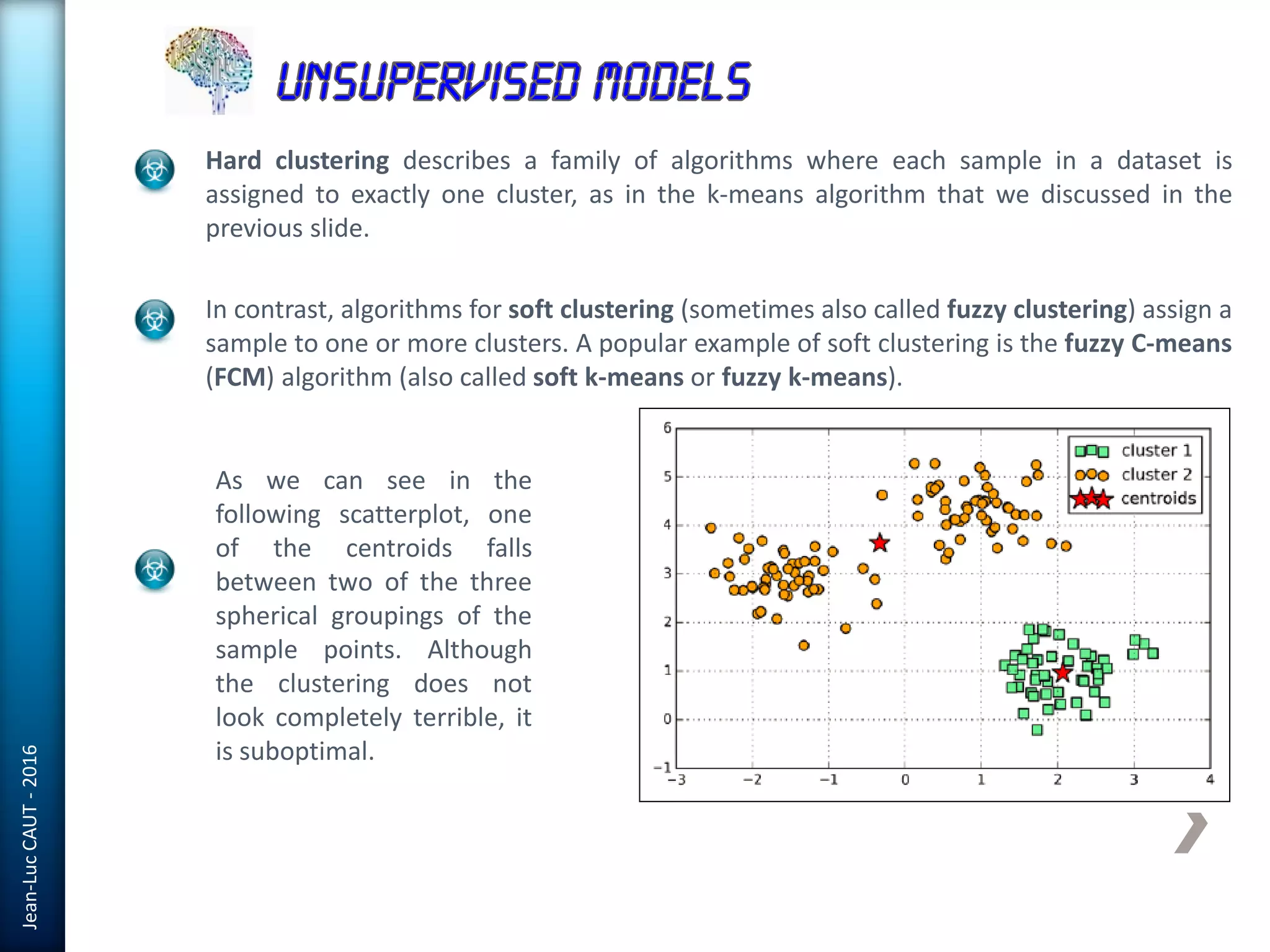
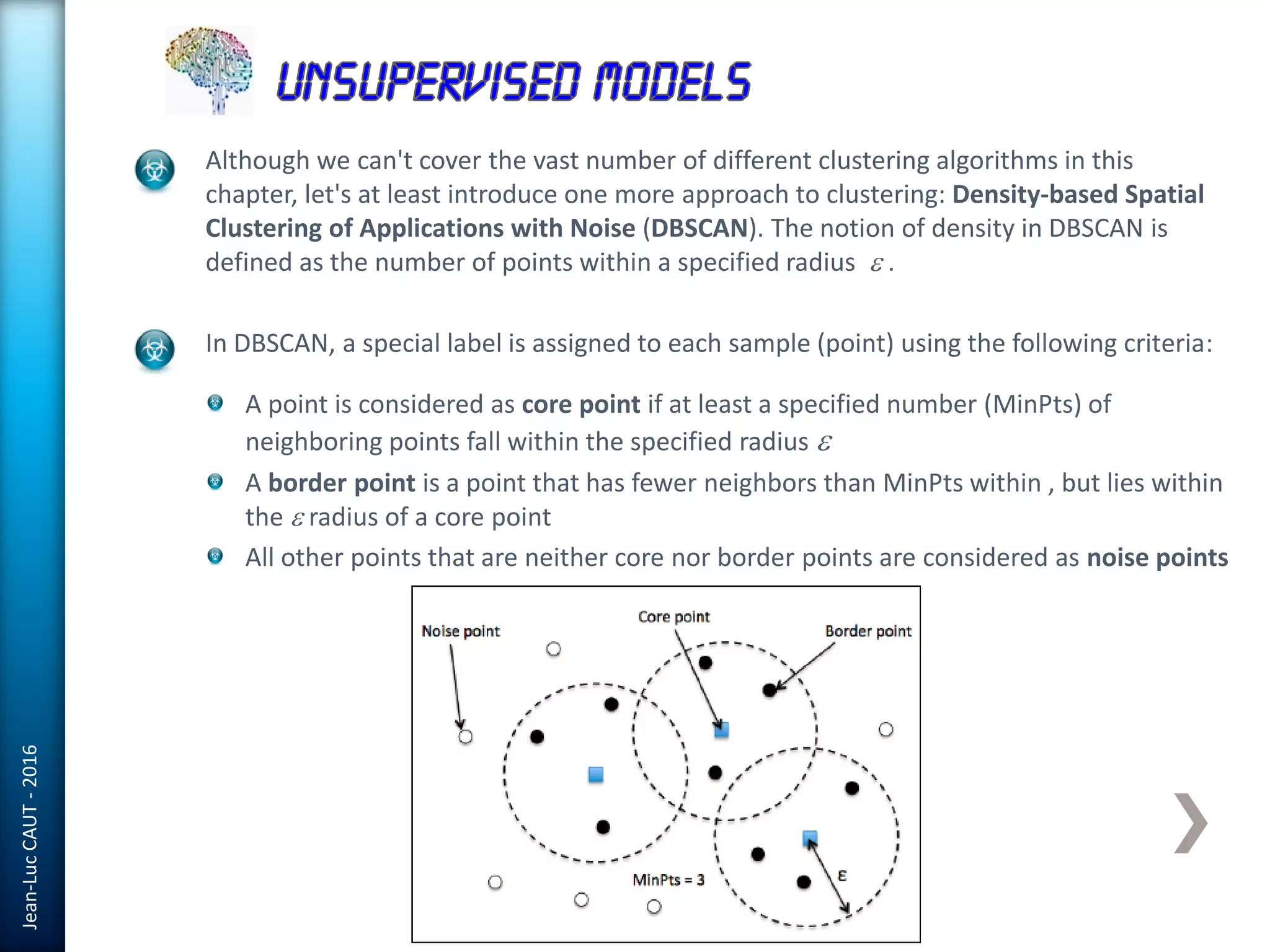
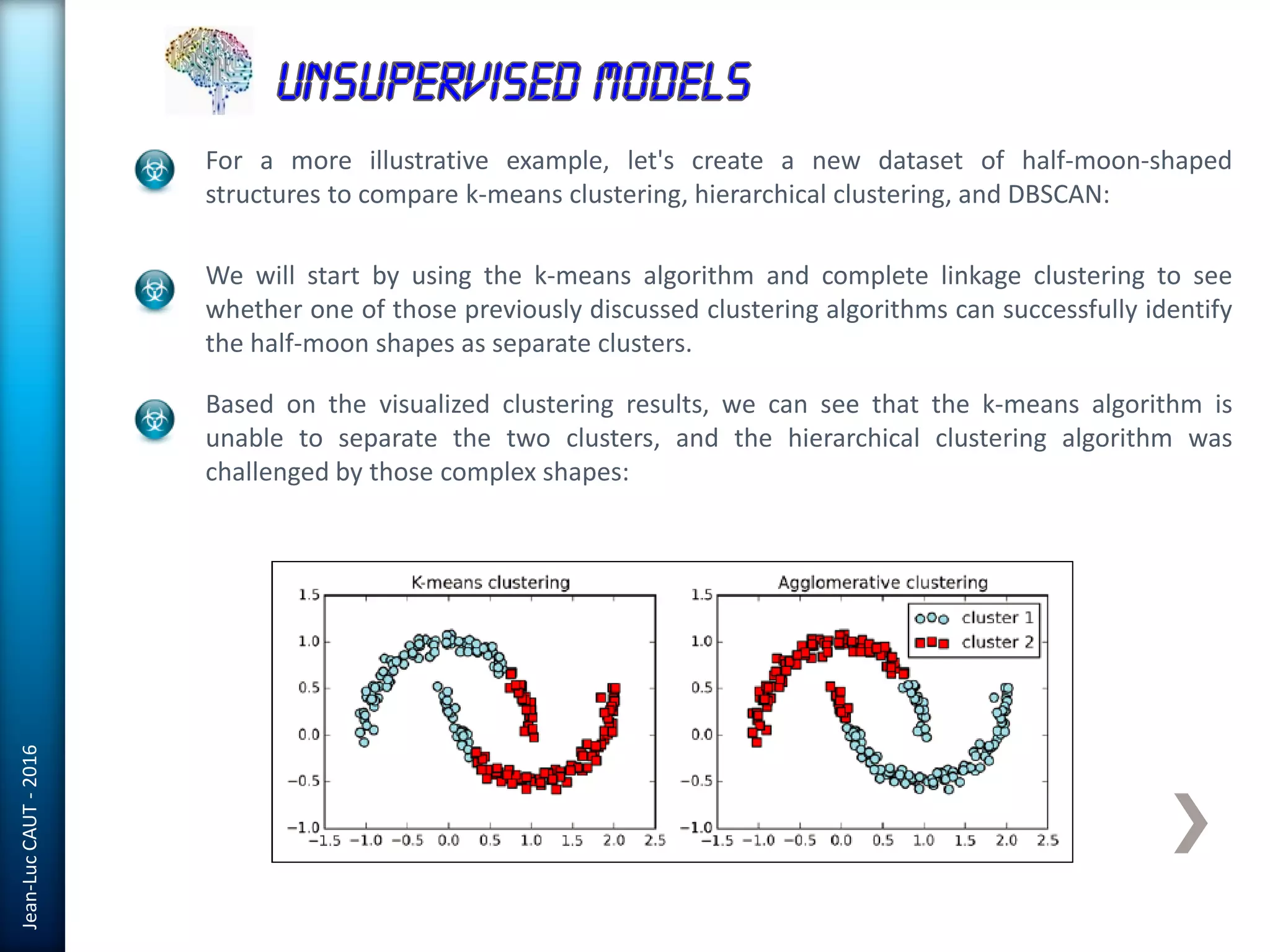
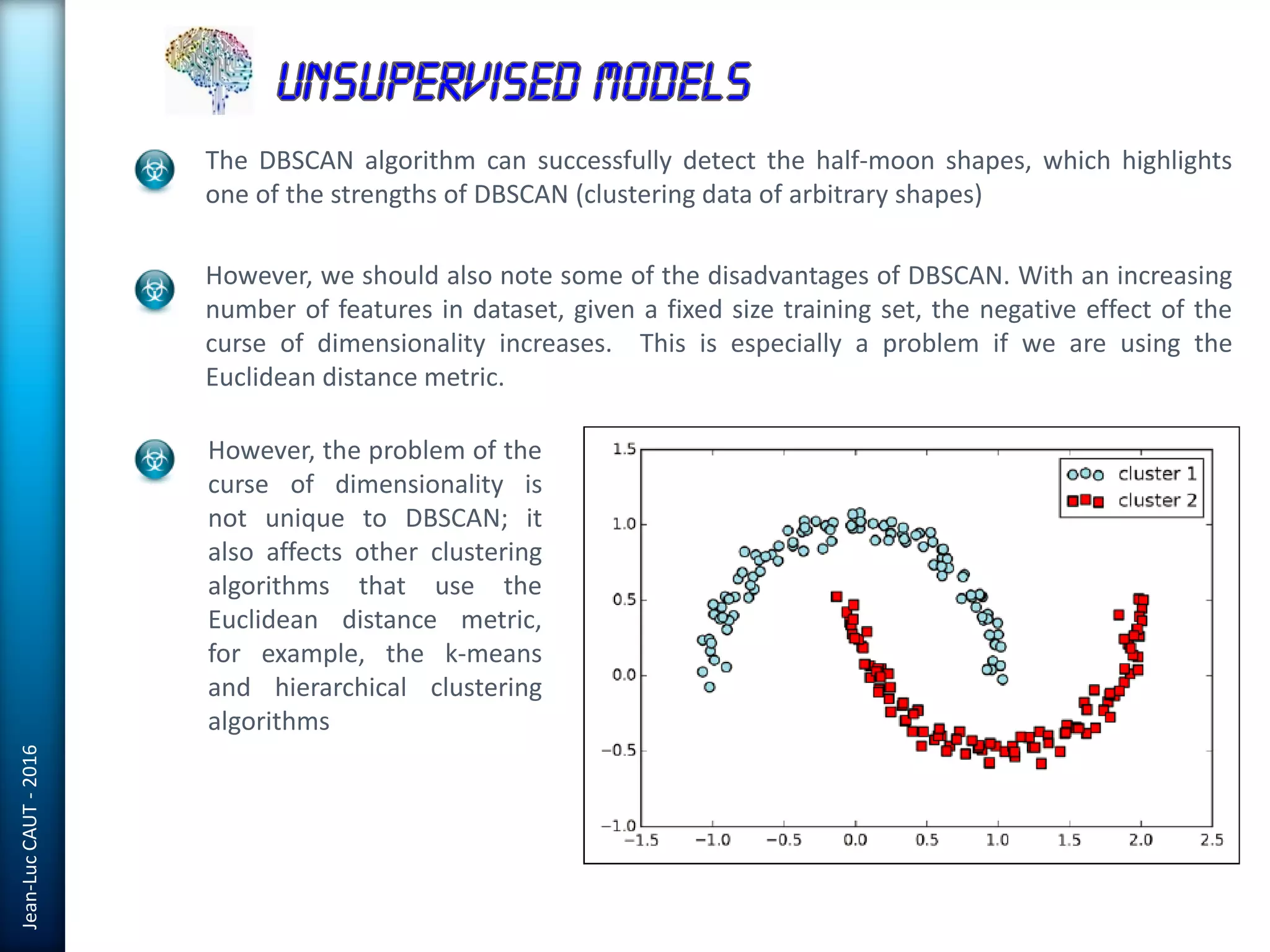
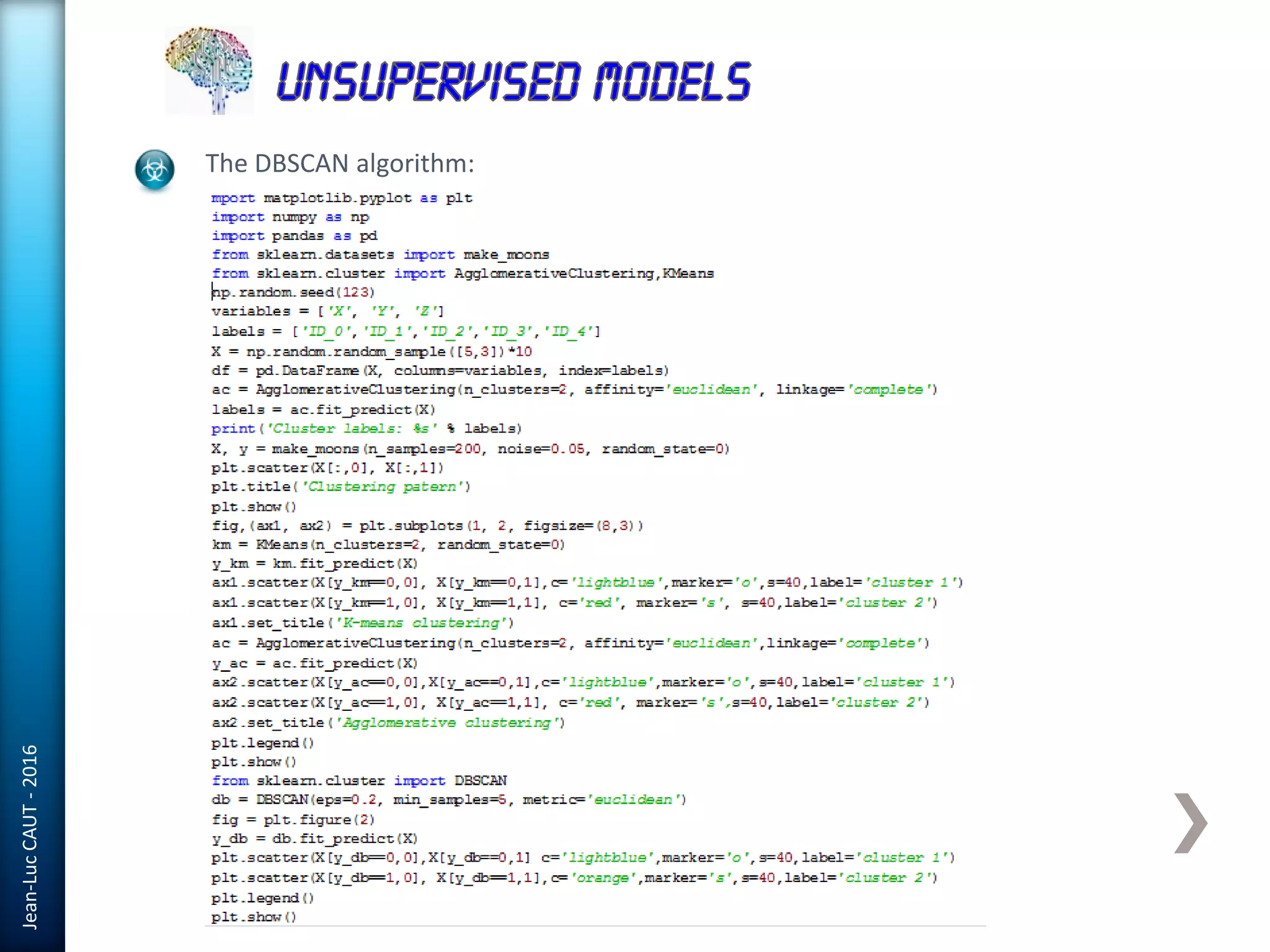

The document discusses the use of machine learning in detecting fraud and analyzing suspicious transactions in banking, emphasizing supervised, unsupervised, and reinforcement learning models. It elaborates on various machine learning algorithms, including logistic regression and random forests, that are effective for classification tasks, and outlines methods for evaluation such as confusion matrices and ROC curves. Additionally, it covers practical applications with Python, showcasing how predictive data analytics can be utilized to enhance decision-making in finance.









































































