Downloaded 147 times






























![t2t2
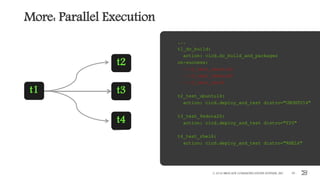
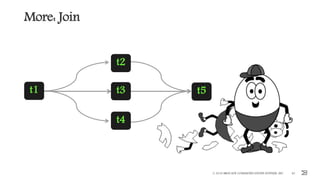
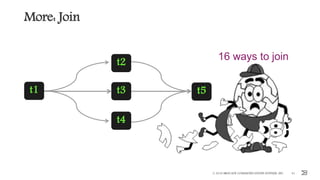
More: Multiple Data
© 2016 BROCADE COMMUNICATIONS SYSTEMS, INC. 45
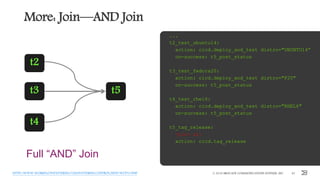
...
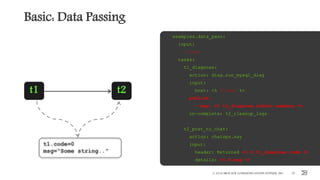
t1_get_ip_list:
action: myinventory.allocate_ips num=4
publish:
- ip_list: <% $.t1_get_ip_list.ips %>
on-complete: t2_create_vms
t2_create_vms:
with-items: ip in <% $. ip_list %>
action: myaws.create_vms ip=<% $.ip %>
t1 t2
ip_list=[...]](https://image.slidesharecdn.com/event-driven-automation-and-workflows-berlin-slideshare-161108184805/85/Event-driven-automation-and-workflows-45-320.jpg)


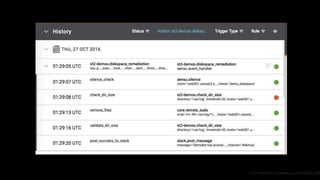








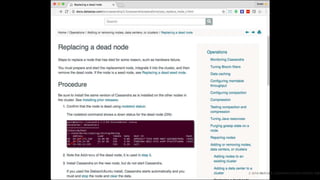
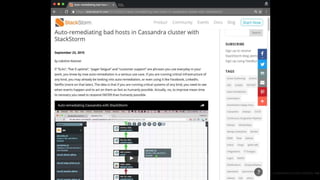




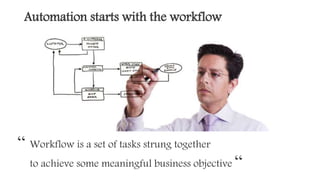
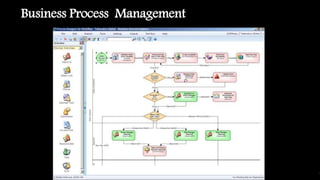
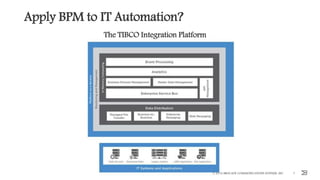
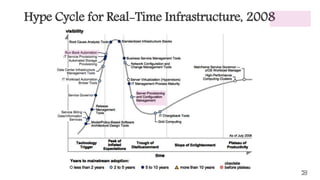
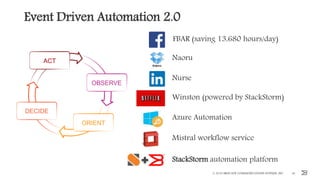
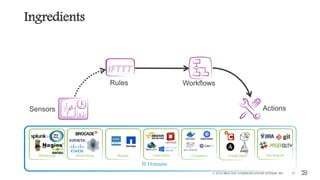
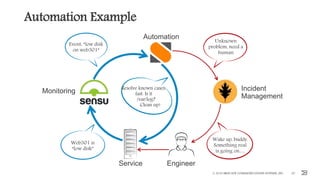
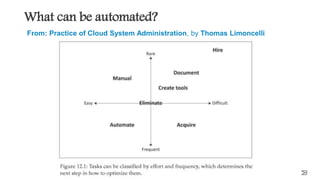
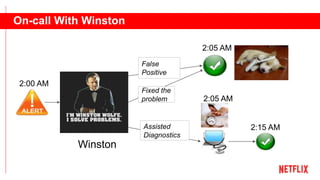
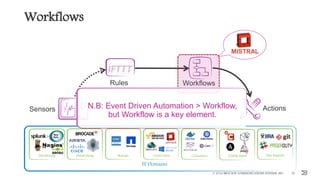
This document outlines the importance of event-driven automation and workflows for enhancing IT operations and auto-remediation. It discusses various automation use cases, benefits such as reducing mean time to recovery and human errors, and compares workflow-based automation to traditional scripting methods. The document emphasizes the significance of reliable automation, infrastructure as code, and the advantages of using workflows over legacy runbook automation.
























![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)



























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














