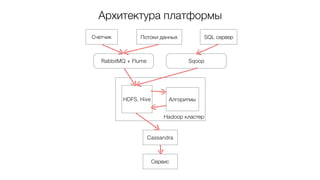
В данном документе рассматривается внедрение системы товарных рекомендаций в интернет-магазине, начиная с проблем, связанных с использованием SQL и переходом к более эффективным инструментам, таким как Apache Spark и Hive. Описаны подходы к улучшению рекомендательных алгоритмов через машинное обучение и оптимизацию обработки данных, а также приведены результаты повышения конверсии и планы на развитие системы. Также упомянуты другие направления работы, включая прогнозирование продаж и оптимизацию ранжирования поиска.