2014 Linked OpenData Annual Conference
LOD 해외 사례
따
라
가
지
만
말
고
2014. 1. 24.
박진호(jino.kor@gmail.com)
성균관대학교 문헌정보학과 DataLab
2014.1.24. 국립중앙도서관 국제회의장
2.
이 자료는 네이버에서제공한 나눔글꼴이 적용되어 있습니다
http://hangeul.naver.com/font
This work is licensed under the Creative Commons 저작자표시-비영리-변경금지
2.0 대한민국 License. To view a copy of this license, visit
http://creativecommons.org/licenses/by-nc-nd/2.0/kr/ or send a letter to
Creative Commons, 444 Castro Street, Suite 900, Mountain View, California,
94041, USA.
3.
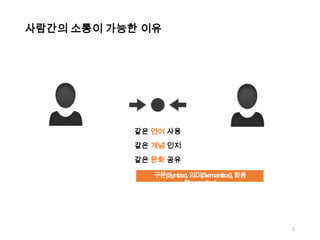
사람간의 소통이 가능한이유
같은 언어 사용
같은 개념 인지
같은 문화 공유
구문(Syntax), 의미(Semantics), 화용
(Pragmatics)
2
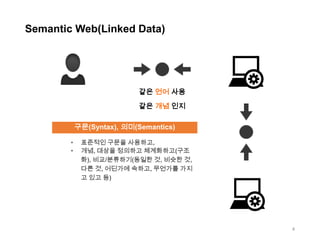
Semantic Web(Linked Data)
같은언어 사용
같은 개념 인지
구문(Syntax), 의미(Semantics)
•
•
표준적인 구문을 사용하고,
개념, 대상을 정의하고 체계화하고(구조
화), 비교/분류하기(동일한 것, 비슷한 것,
다른 것, 어딘가에 속하고, 무언가를 가지
고 있고 등)
4
6.
Linked Open Data
•웹에서 보다 잘 소통하기 위한 방식 :
-
기본적으로 정보문제(Information needs) 해결을 위한 활동
-
웹은 문제해결이 가능한 거대한 데이터베이스(documents 중심)
-
기존의 소통방식도 좋으나 보다 정확하고 명확한 이해(machine
processable)가 가능하도록 하는 것이 필요
-
웹을 구조화시키고, 소통하기 위한 기본 원칙(LOD원칙)을 준수하고,
공통적으로(사람과 기계, 기계와 기계) 이해가 가능한 구조와 언어로
(RDF/OWL) 누구나 활용할 수 있도록(Open) 하기
5
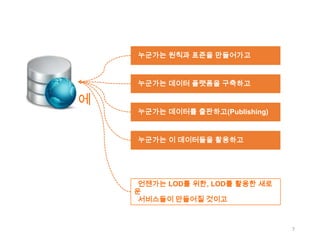
누군가는 원칙과 표준을만들어가고
누군가는 데이터 플랫폼을 구축하고
에
누군가는 데이터를 출판하고(Publishing)
누군가는 이 데이터들을 활용하고
언젠가는 LOD를 위한, LOD를 활용한 새로
운
서비스들이 만들어질 것이고
7
9.
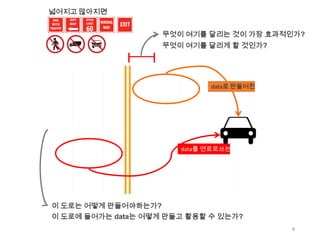
넓어지고 많아지면
무엇이 여기를달리는 것이 가장 효과적인가?
무엇이 여기를 달리게 할 것인가?
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data
data data로 만들어진
data
data
data
data
data
data
data를 연료로쓰는
data
data
data
data
data
이 도로는 어떻게 만들어야하는가?
이 도로에 들어가는 data는 어떻게 만들고 활용할 수 있는가?
8
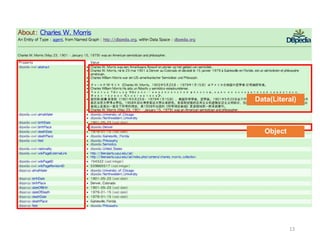
사례1 : DBpedia
•위키피디아(Wikipedia, http://www.wikipedia.org)로부터 구조화된정
보를 추출하고 웹에서 이 정보들을 활용 가능하도록 함
- 약 400만 개의 개념(things)이 기술 : 약 80만 건이 사람에 대한 것, 60
만 건이 장소(인구정보를 포함하고 있는 약 40만 건 포함), 약 37만 건
이 저작물(11만 건의 음악앨범, 7만 건의 영화, 2만 건의 비디오 게임
포함), 20만 건이 기관(약 5만 건의 회사 정보와 4만 건의 교육기관 포
함), 22만 건의 종 정보와 약 5천 건의 질병관련 정보
- 영어 외에 DBpedia는 119개 언어로 구성된 정보를 제공함. 이는 약
2,400백만 건의 개념(things)들을 기술하고 있는데 이 중 약 16백만건
이 영어버전의 DBpedia와 연결되어 있음
10
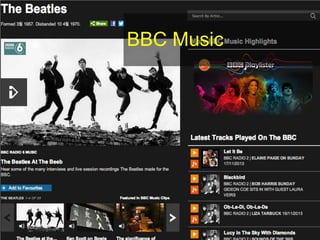
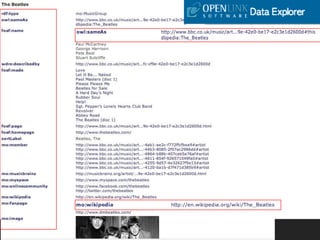
사례2 : BBC
•미디어 분야 중 가장 적극적으로 LOD를 직접 활용하고 업무 영역까
지 확장하여 실제 이용자 서비스에 도입
- BBC가 구축, 관리하는 데이터에 대한 Linked Data 발행자이자,
MusicB_rainz, DBPedia, Wikipedia 데이터와의 연결을 지향하는 데이
터 소비자
- BBC가 생산하는 막대한 정보들은 상호간의 공유와 연계, 협업 없이 해
당 채널별 지역별로 분리되어, 데이터 중복, 데이터 관리/운영 어려움
(재정적어려움 포함) 초래
- 이러한 문제를 극복하기 위해 Linked Data 도입
14
16.
사례2 : BBC
•2007년 10월 BBC Programmes 서비스
- 웹에서 BBC 프로그램에 대한 영구적인 접근과 정보활용 보장
- BBC 프로그램으로 8개의 BBC TV 채널, 10개의 주요 라디오 방송국,
스코틀랜드, 북아일랜드, 웨일즈를 포함하는 6개 방송국의 모든 프로
그램 데이터에 대한 접근
- 이를 구현하기 위해 프로그램 메타데이터 간의 공유와 활용을 위해
Linked Data 선택(BBC 웹사이트 15개 원칙)
- 특정 사람부터 특정 프로그램까지 모든 것을 식별할 수 있도록 하고,
이를 RDF를 활용하여 기계가독형으로 표현
15
17.
사례2 : BBC
TheBBC’s 15 Web principles
• BBC 2.0 프로젝트의 일환
1. Build web products that meet audience needs
2. The very best websites do one thing really, really well 3. Do not attempt
to do everything yourselves
4. Fall forward, fast
5. Treat the entire web as a creative canvas
6. The web is a conversation. Join in 7. Any website is only as good as its
worst page
8. Make sure all your content can be linked to, forever.
9. Remember your granny won’t ever use “Second Life”
10. Maximise routes to content
11. Consistent design and navigation needn’t mean one-size-fits-all
12. Accessibility is not an optional extra
13. Let people paste your content on the walls of their virtual homes
14. Link to discussions on the web, don’t host them
15. Personalisation should be unobtrusive, elegant and transparent
16
18.
사례2 : BBC
•BBC Linked Data 플랫폼은 DSP(Dynamic Semantic Publishing)가
자연스럽게 진화한 형태로 BBC의 모든 콘텐츠에 태깅을 허용한다
는 생각에 기초
-
기존의 BBC 콘텐츠 관리 시스템은 개방되고 연결된 구조의 웹에서 재
활용되고 서비스되는데 적합하지 않음
-
모든 BBC 저작물이 데이터 뒤에 숨겨져 있는 의미를 이해할 수 있도
록 하고 “things”에 대한 검색이 가능하도록 하는 API를 제공하는 것임
-
현재 음악, 스포츠(축구와 올림픽), 정치, 학습 분야에 적용 향후 확장
고려
17
사례2 : BBC
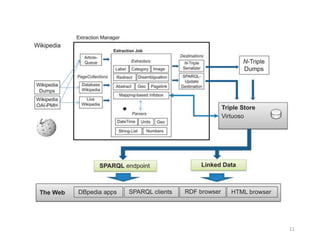
•2012년부터 BBC News를 위한 시맨틱 프로토타이핑 플랫폼
BBC News Juicer 시작
The News Juicer
1
2
3
4
5
6
Grab
BBC News & Sp
ort Articles
Extract Concep
ts
Match to DBpe
dia
Annotate Articl
e
Push to Triplest
ore
Expose
via
API
20
22.
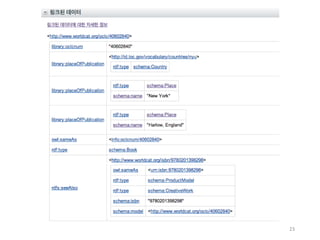
사례3 : OCLCWorldCat
• OCLC WorldCat.org
- Schema.org의 용어집을 활용하여 서지 정보에 대한 구조화된 데이터
를 제공
- 웹 검색엔진(서비스)에서 WorldCat 서지 정보에 대한 접근성을 강화하
는 효과를 갖는데, 이는 서지 정보 기술을 위한 OCLC의 1세대 링크드
데이터모델
21
사례4 : LinkedOpen Vocabulary
• LOV(Linked Open Vocabularies, http://lov.okfn.org)
-
링크드 데이터 웹의 성장으로 수많은 RDFS/OWL 기반의 용어집들이
존재하며, 용어집은 SKOS, DC, FRBR과 같은 표준뿐만 아니라 FOAF,
Event Ontology와 같이 사실상 표준들인 것들도 있음
- 현재 수많은 용어집들이 새로운 메타데이터를 선언하고 상호 연결되
어 웹에 출간되면서 새로운 용어집 생태계를 이루고 있음
- LOV는 어휘 생태계에 쉽게 접근할 수 있는 방법을 제공함
25
사례4 : GeoNames
•GeoNmaes 온톨로지는 웹에 URI를 활용해서 약 1,000만 건의 지리
적위치 정보를 제공하고 있으며 이중 약 800만 건은 지리와 관련된
다양한 특징적인 정보를 포함하고 있음
- 인구정보를 포함한 280만 건의 지리정보, 이명표기를 갖고 있는 550만
건의 지리정보 등
- GeoNames는 다양한 언어, 고도, 인구와 다양한 이명표기 등에 대한
데이터를 통합한 데이터로, 모든 위도, 경도 좌표는 WGS84(World
Geodetic System 1984)표준을 따르고 있음
28
한 번 더생각해볼 문제
• 어디에서 출발할 것인가?
- BBC의 경우처럼 현재 해결해야할 문제가 있는가?
- 단지, 내 데이터를 발행하는 것이 중요한가?
- 기존에 연결되어 있는 기관(웹사이트, 데이터베이스 등)과 함께 출발해
보는 것은 어떠한가?
- 꼭, RDF로 개방해야하는가?
30
32.
플랫폼은 누가, 어떻게만들고 있고
데이터는 누가, 어떻게 만들고 있고
서비스는 누가 어떻게 만들고 있는가?
나의 문제 상황은 무엇인고, 내가 만들어야 하는 것은 플랫폼인가, 데이터인가, 서비스인
가?
31
33.
참고자료
•
•
•
•
박진호 (2013, 7월).도서관은 웹에 존재하는가? : 링크드데이터, 글로벌 데이터베이스.
국가전자도서관 세미나. 경기도 : 국가기록원
박진호. (2013). 도서관 데이터의 링크드 데이터(Linked Data) 변환과
인터링킹(interlinking)을 통한 정보연계 확장성에 관한 연구 : 국립중앙도서관 서지,
주제명, 저자명 데이터를 중심으로. 석사학위논문, 성균관대학교, 서울.
박진호 (2013, 12월). 국내외 정보서비스 기관의 LOD 구축 동향, KISIT 세미나. 서울 :
한국과학기술정보연구원
Godby, J. Carol. (2013, June). The Relationship between BIBFRAME and OCLC’s Linked-Data
Model of Bibliographic Description: A Working Paper. OCLC Working Paper. Retrieved from
http://oclc.org/content/dam/research/publications/library/2013/2013-05.pdf
이미지 출처
http://www.flickr.com/photos/sergemelki/8156333460/
32



























































![[오원석 Kswc2010]데이터의 가치를 높이는 linked data](https://cdn.slidesharecdn.com/ss_thumbnails/kswc2010linkeddata-101208002844-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





































