Downloaded 51 times






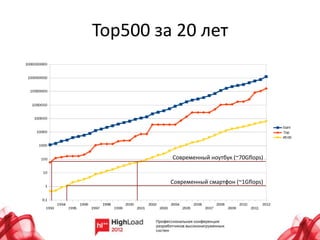



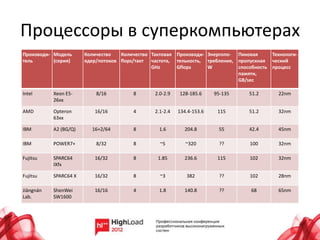















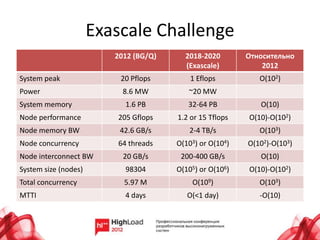



















Документ рассматривает состояние и будущее суперкомпьютеров, охватывая их архитектуру, производительность и основные проблемы. В нем анализируются топологии интерконнектов, потребление энергии и надежность систем, а также прогресс в области программного обеспечения и параллельного программирования. Также подчеркиваются перспективы развития технологий, включая интеграцию памяти и процессоров, а также использование альтернативных архитектур, таких как ARM.



































































