Download to read offline




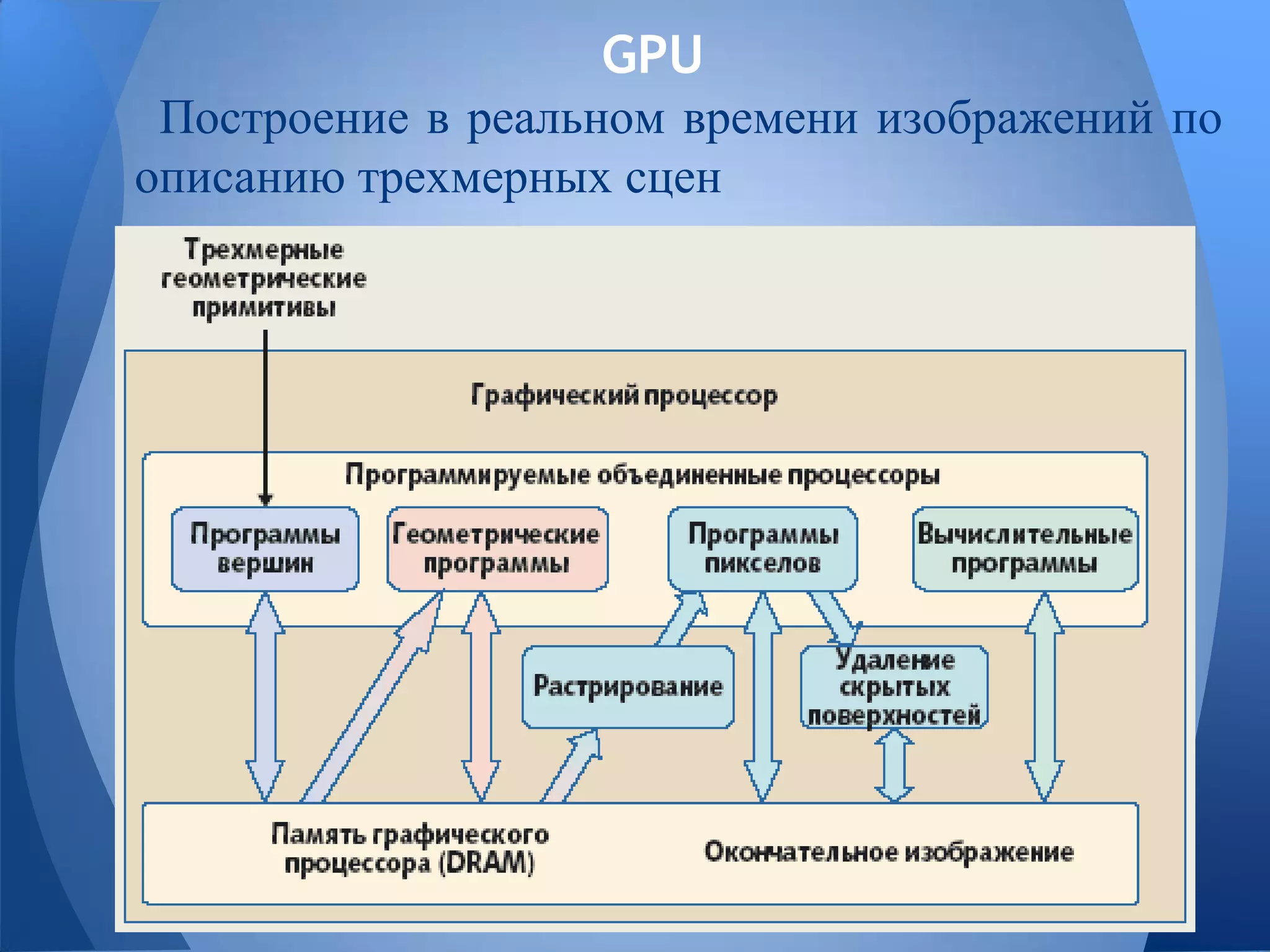

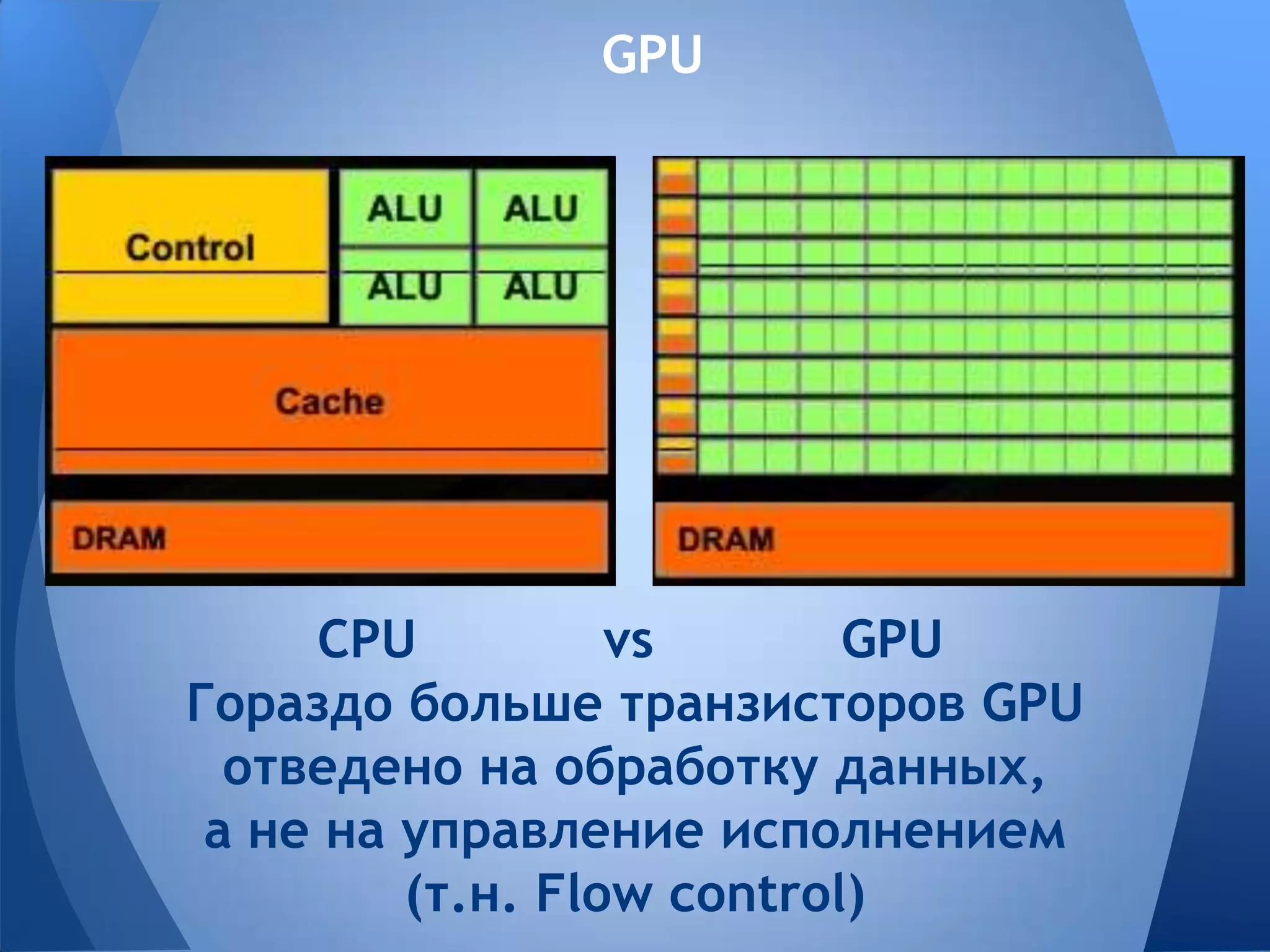
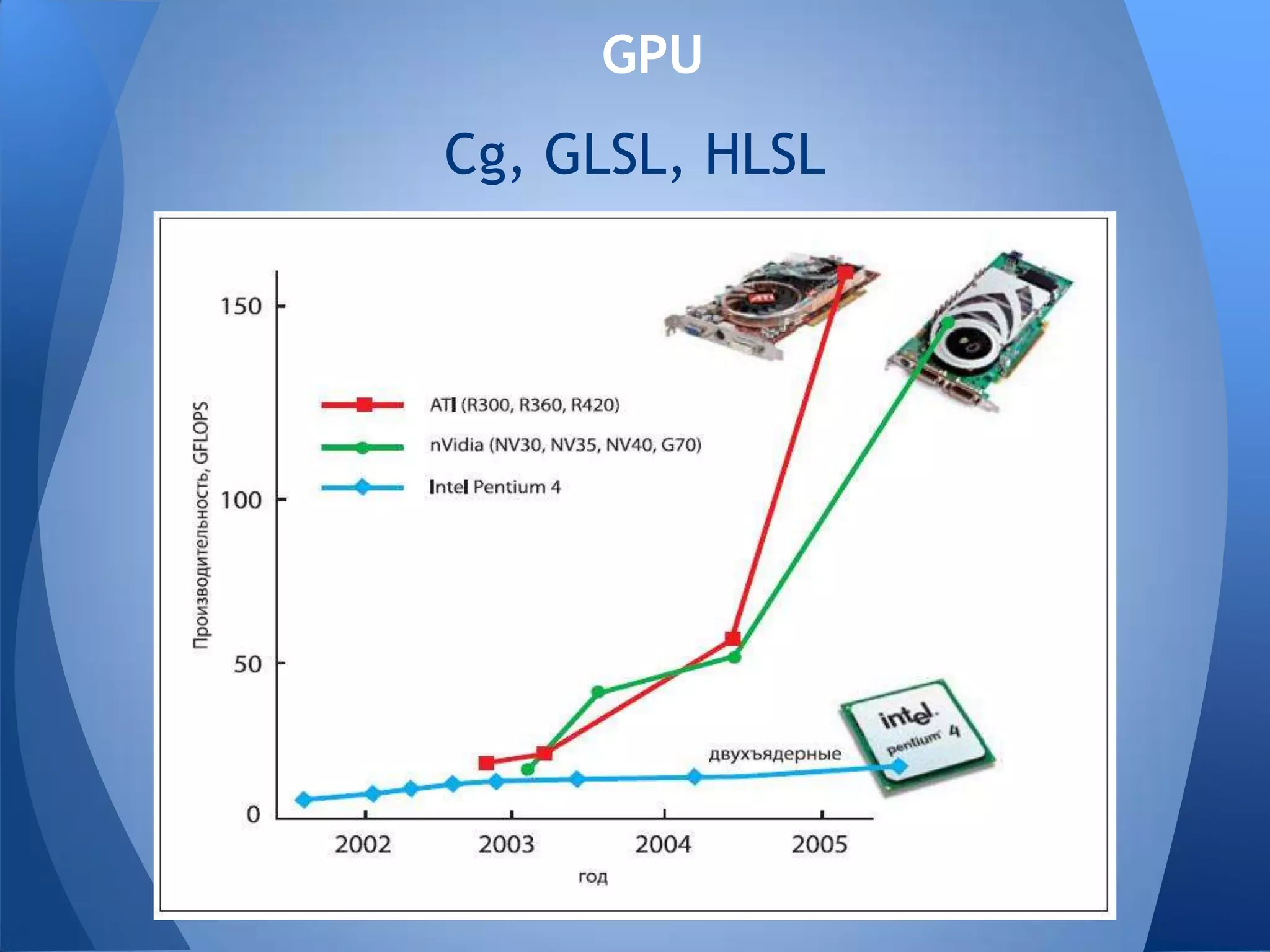
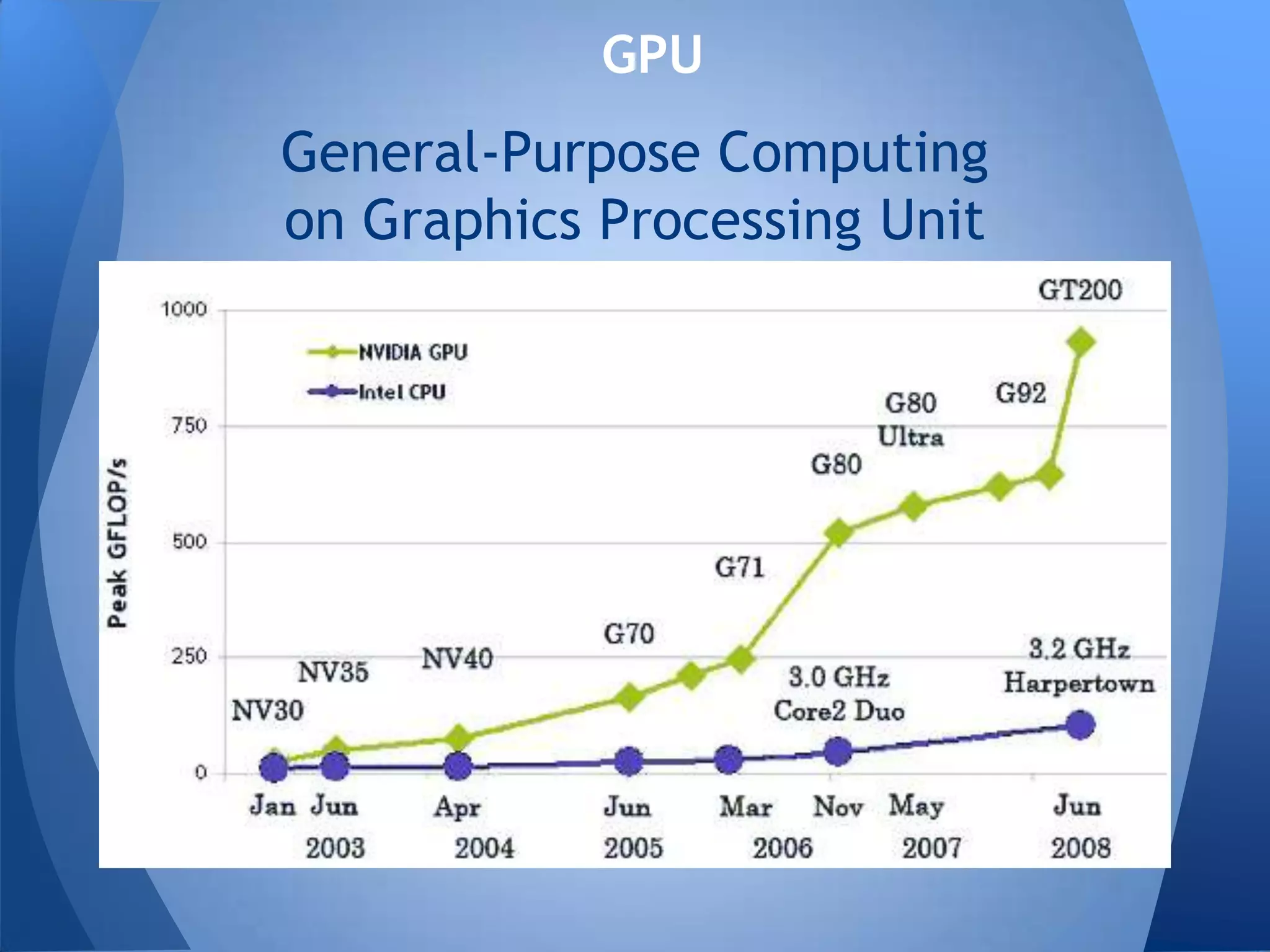

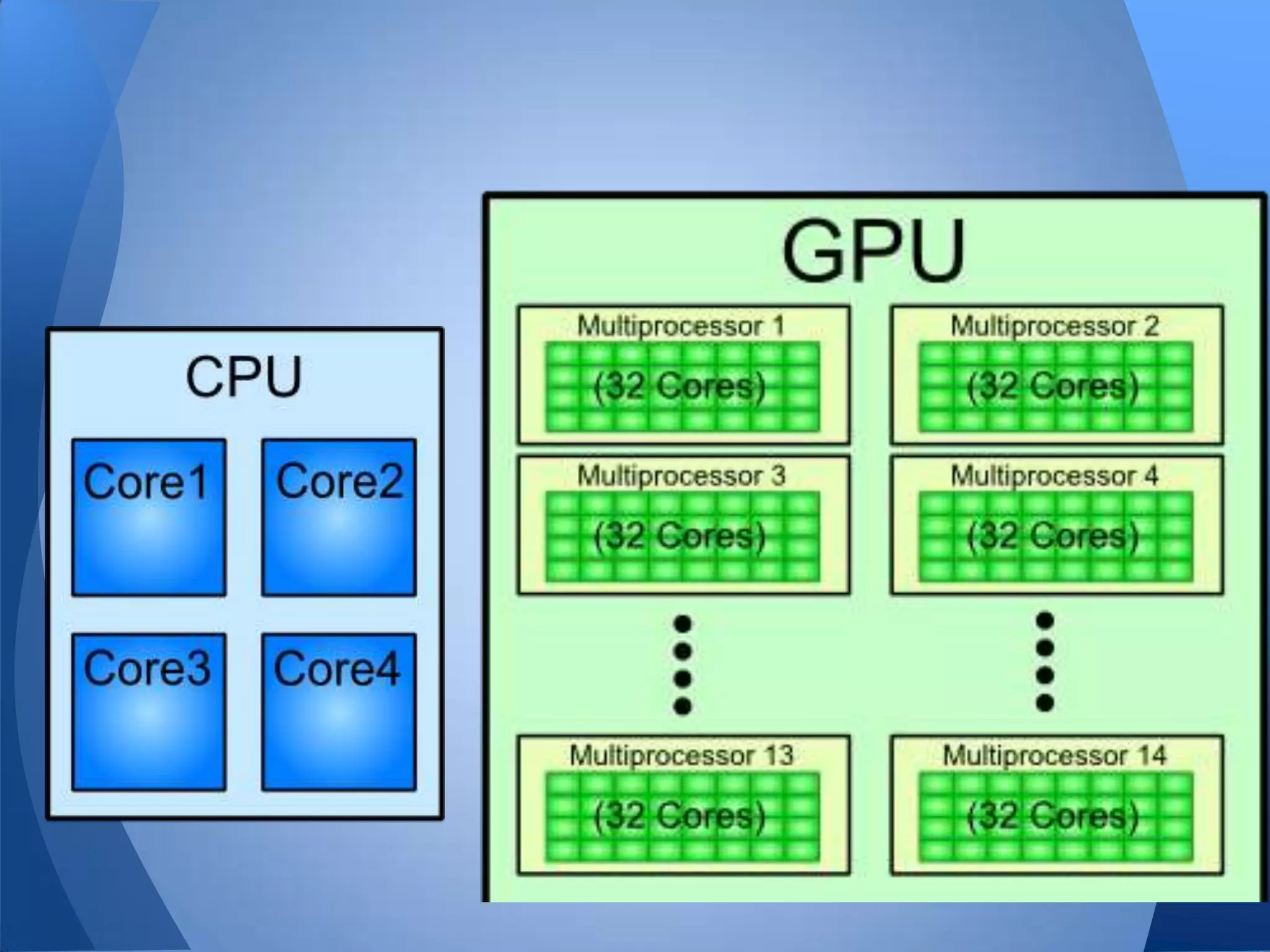

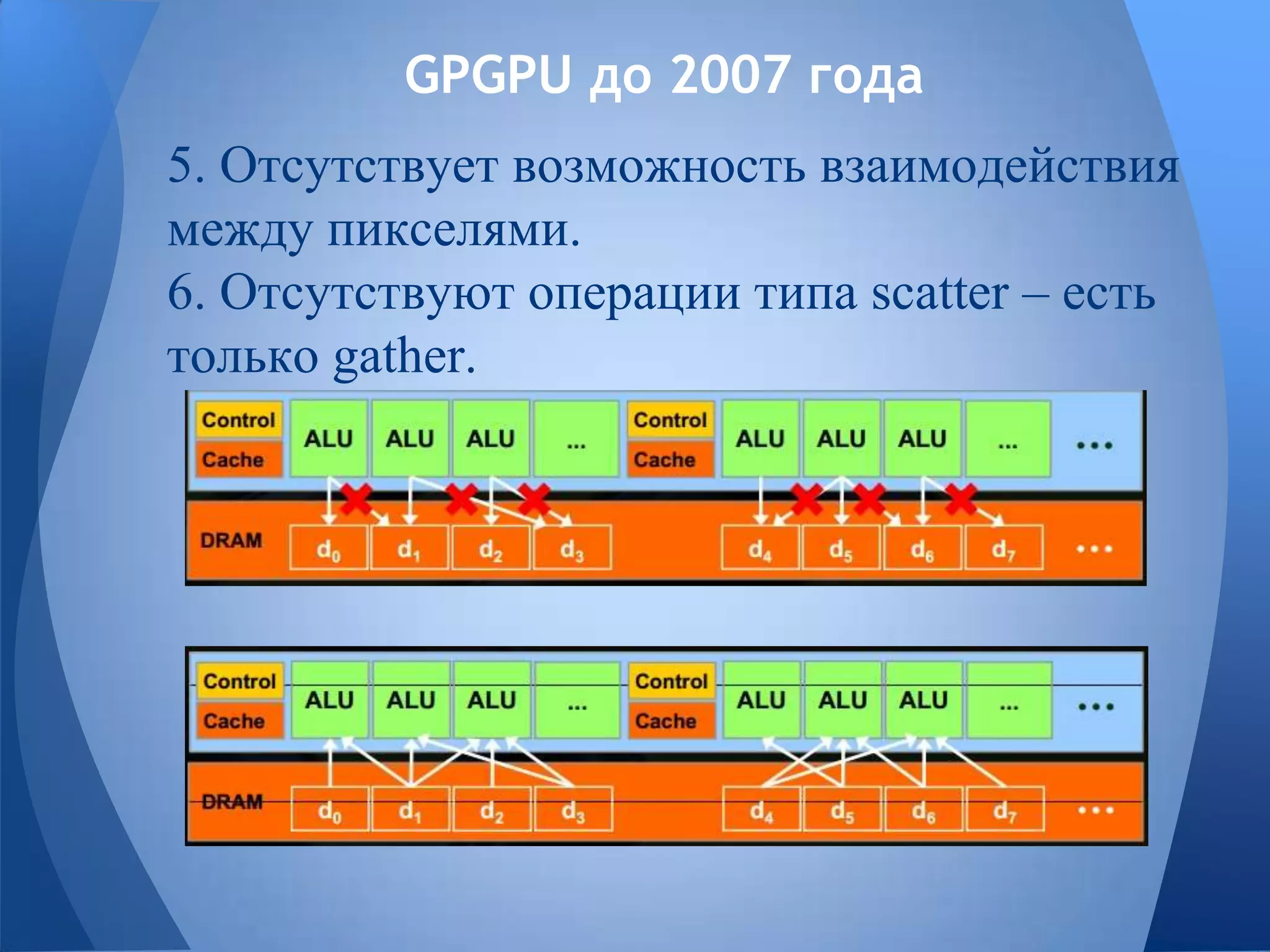
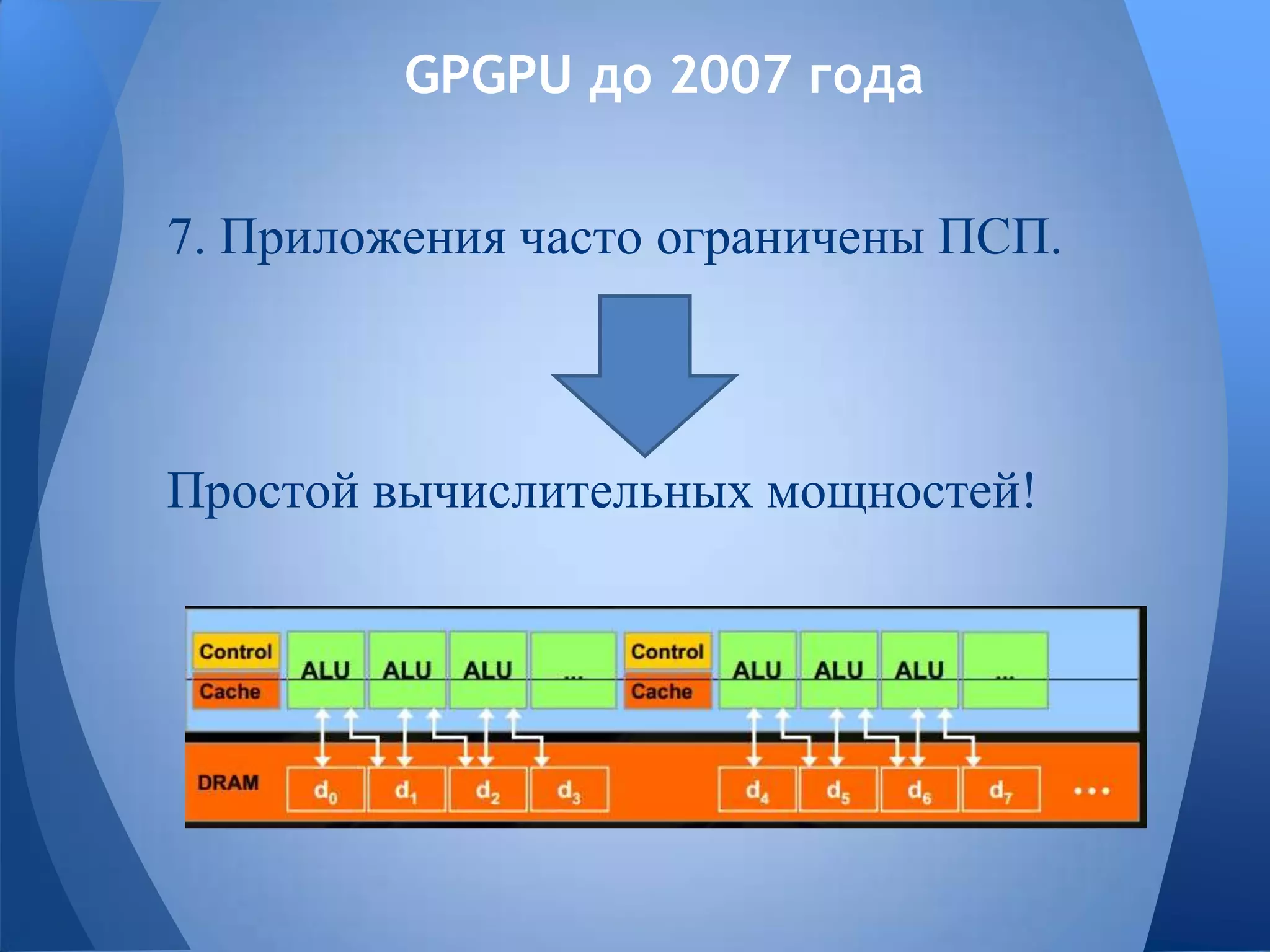


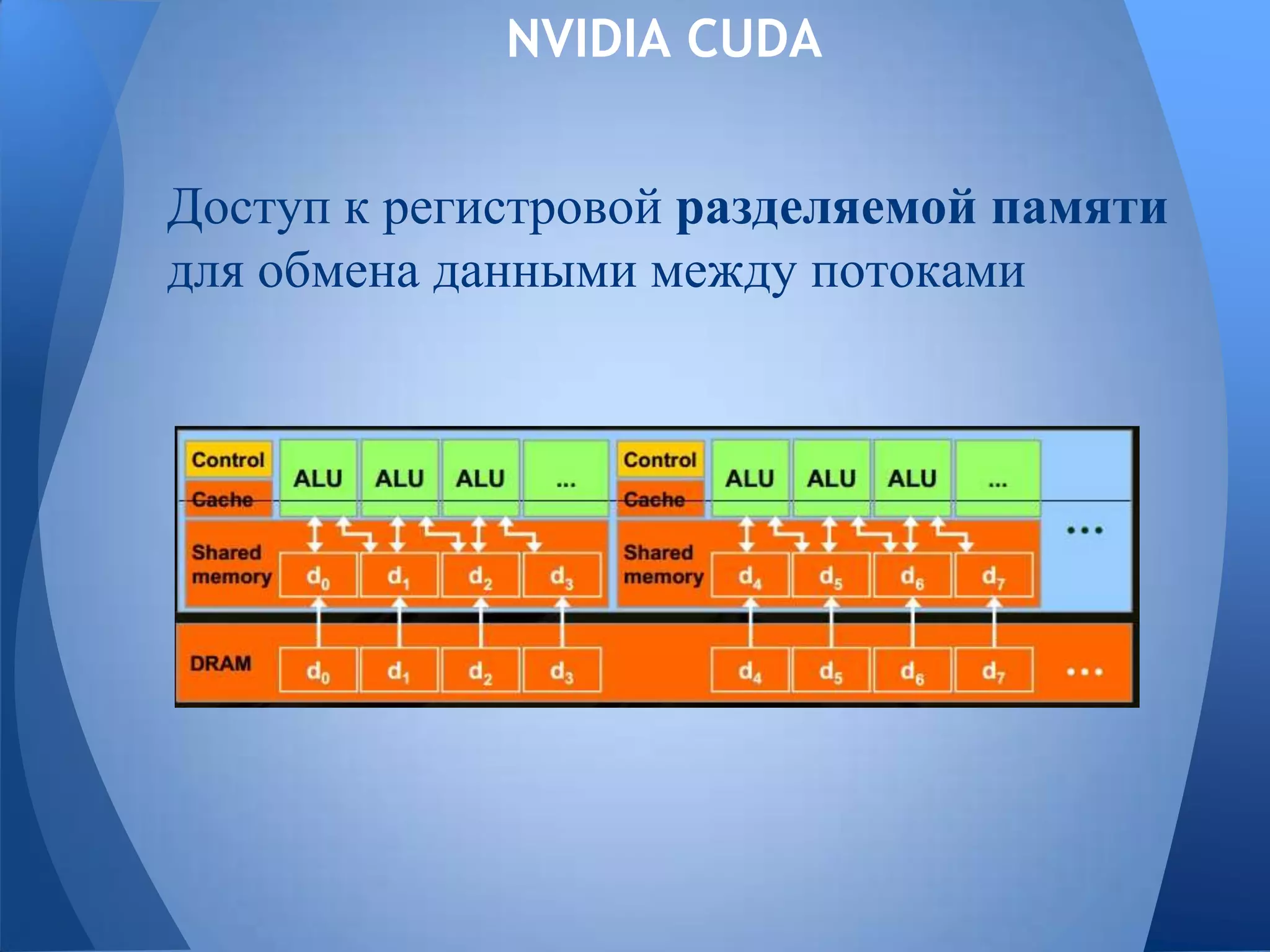
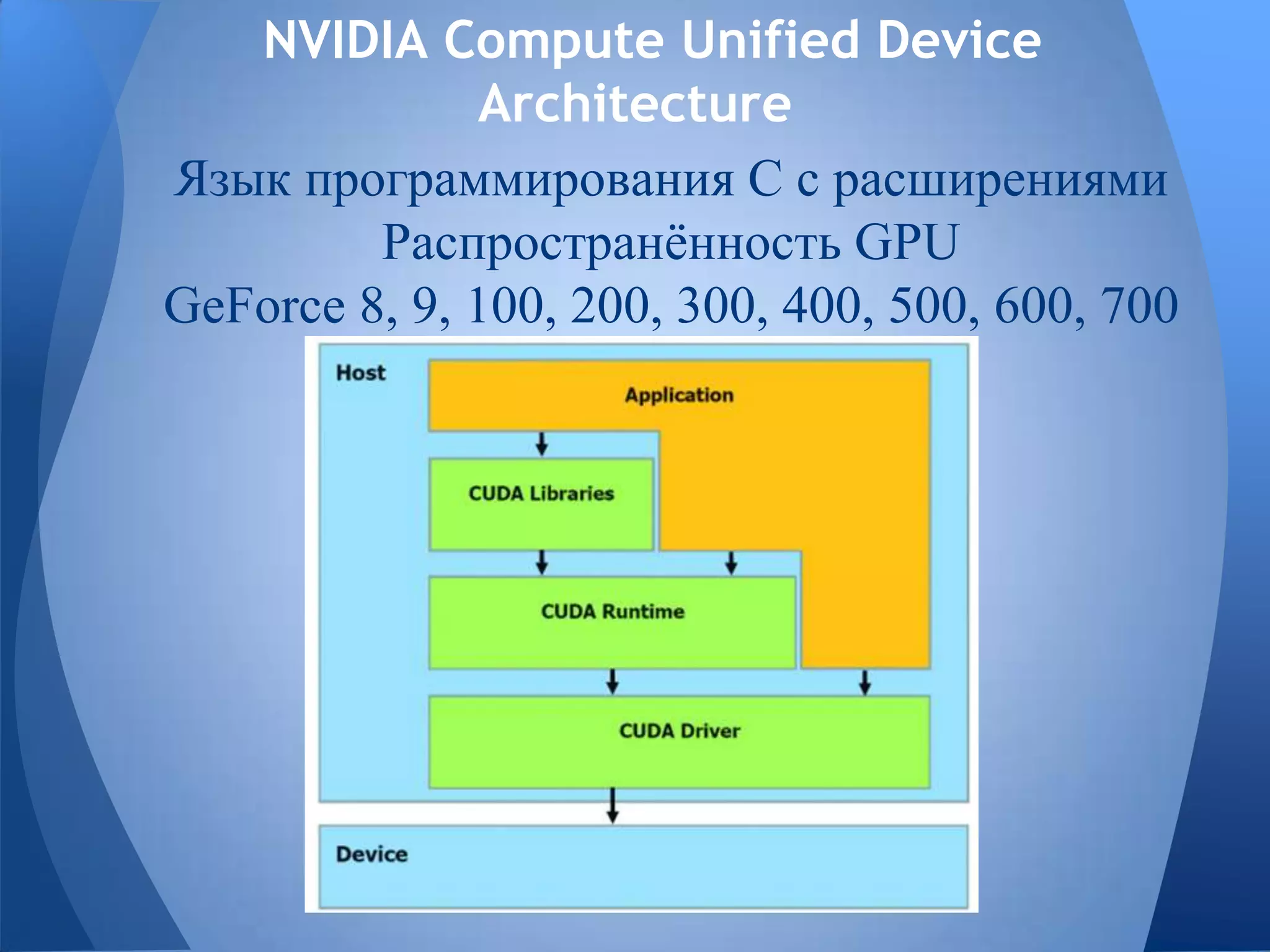

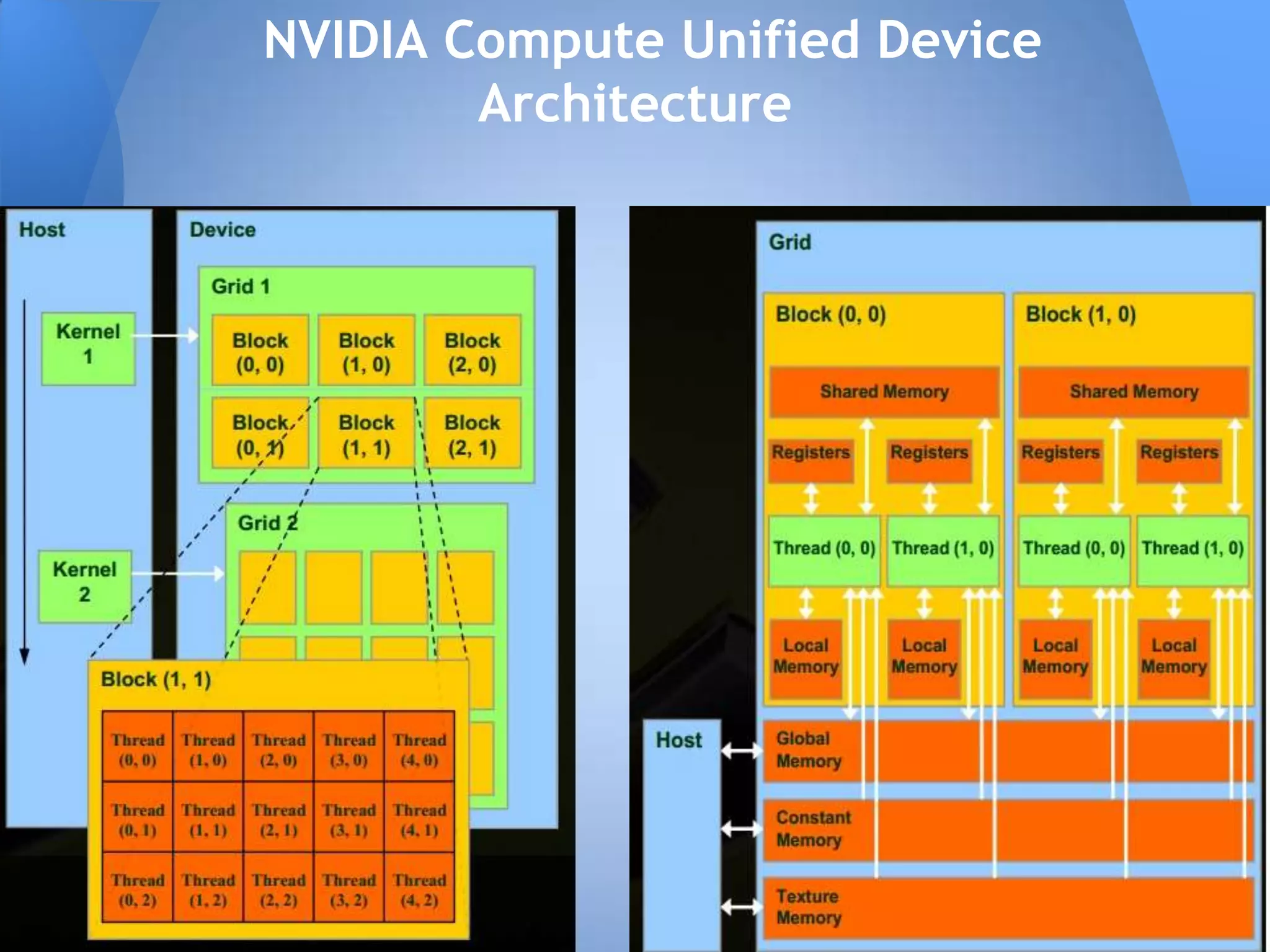
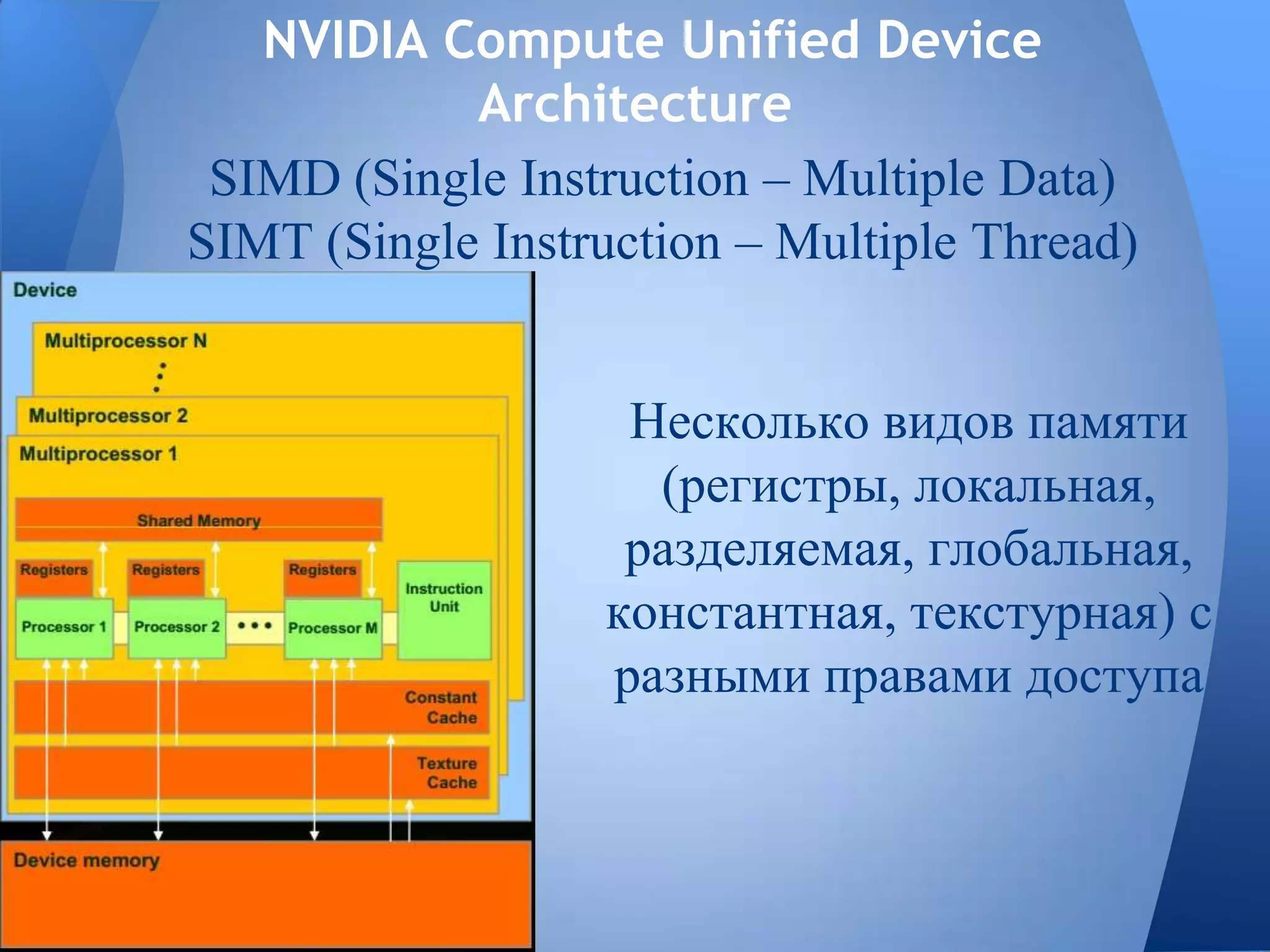


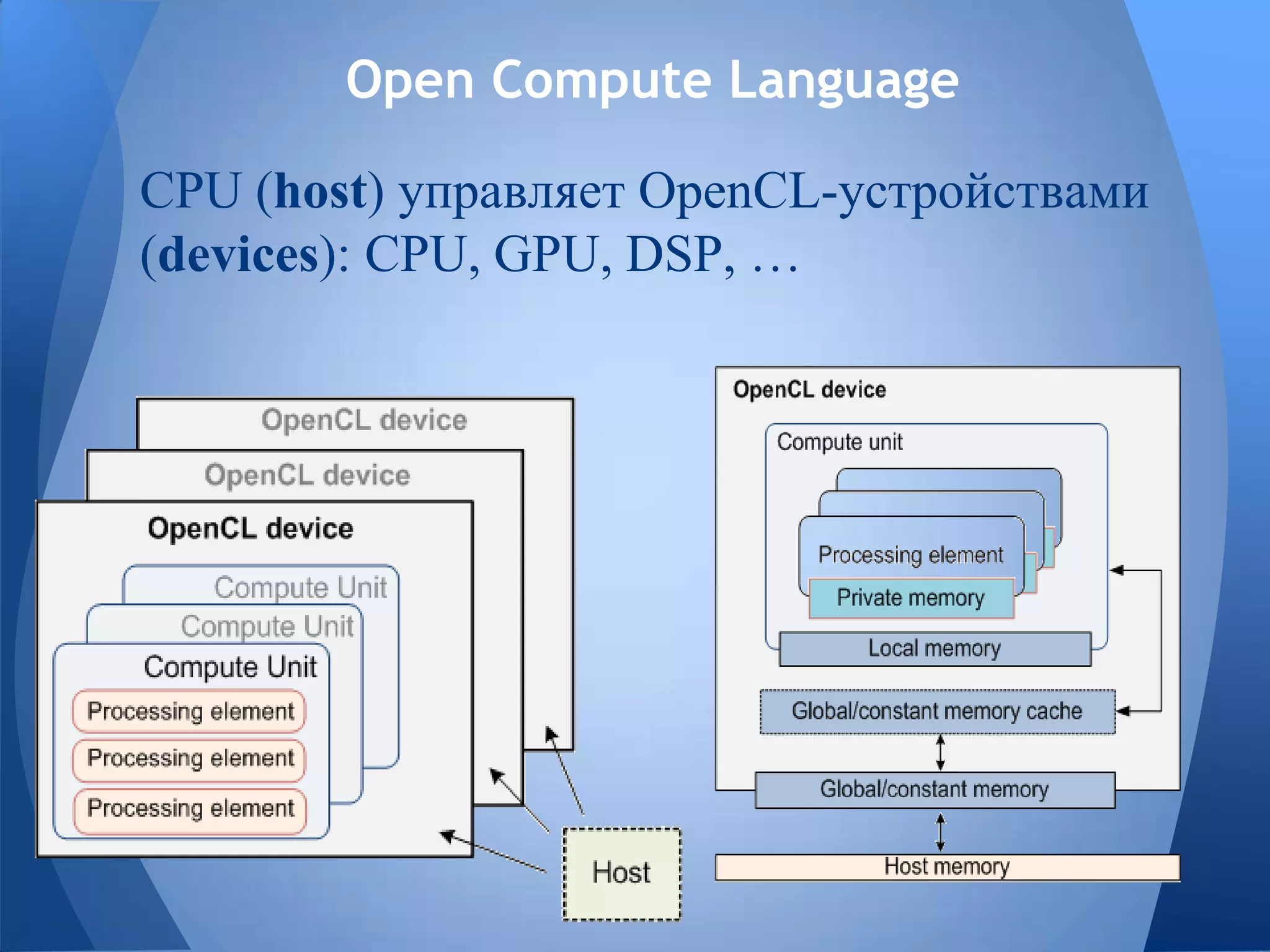










Документ обсуждает технологии графических процессоров (GPU) и их применение в вычислениях общего назначения (GPGPU), включая архитектуру NVIDIA CUDA и OpenCL. В нем представлены сравнительные характеристики различных процессоров и GPU, а также их использование в параллельных вычислениях. Также упоминается взаимодействие NVIDIA с учебными заведениями и ссылки на источники по теме.




































































