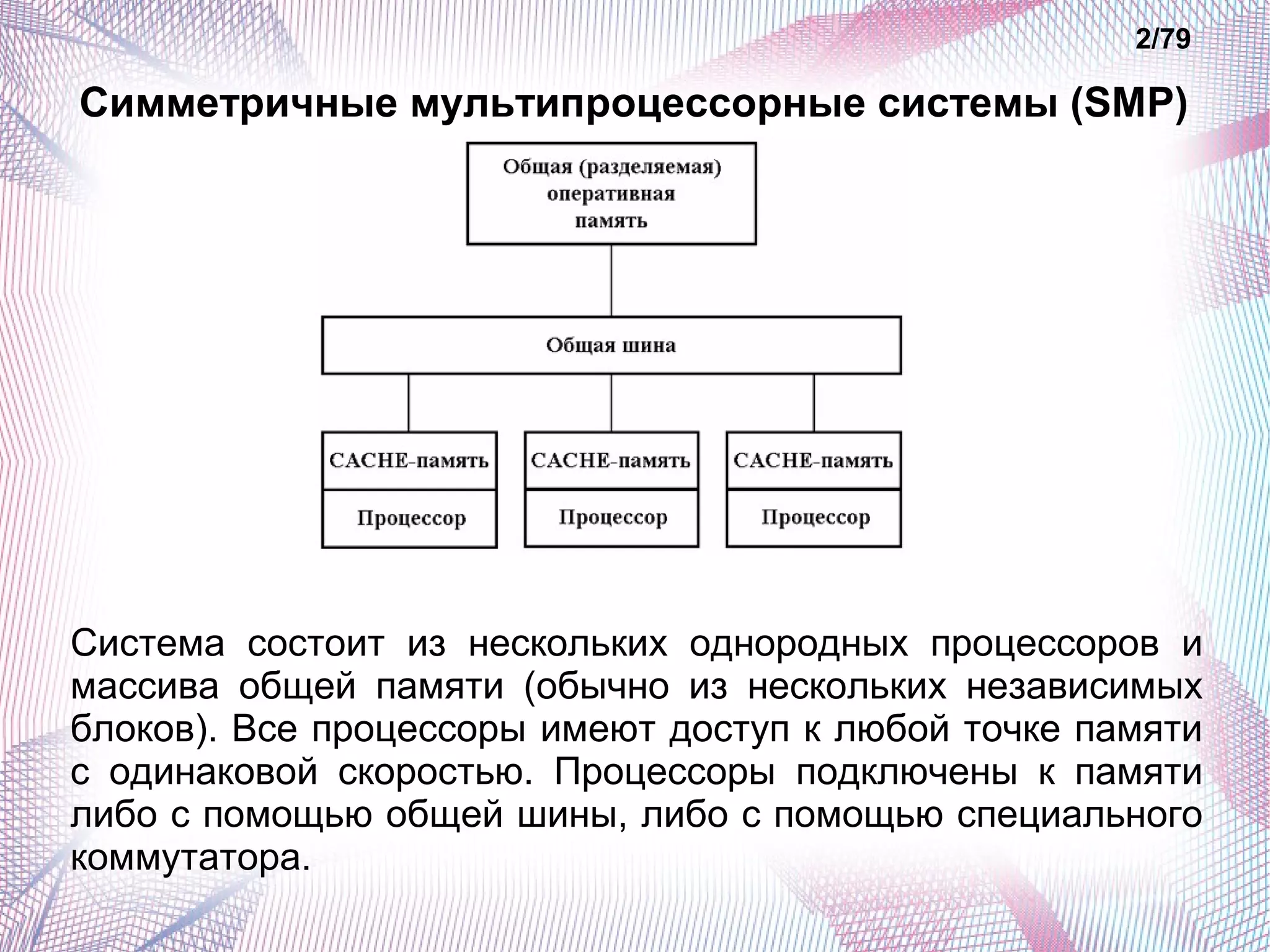
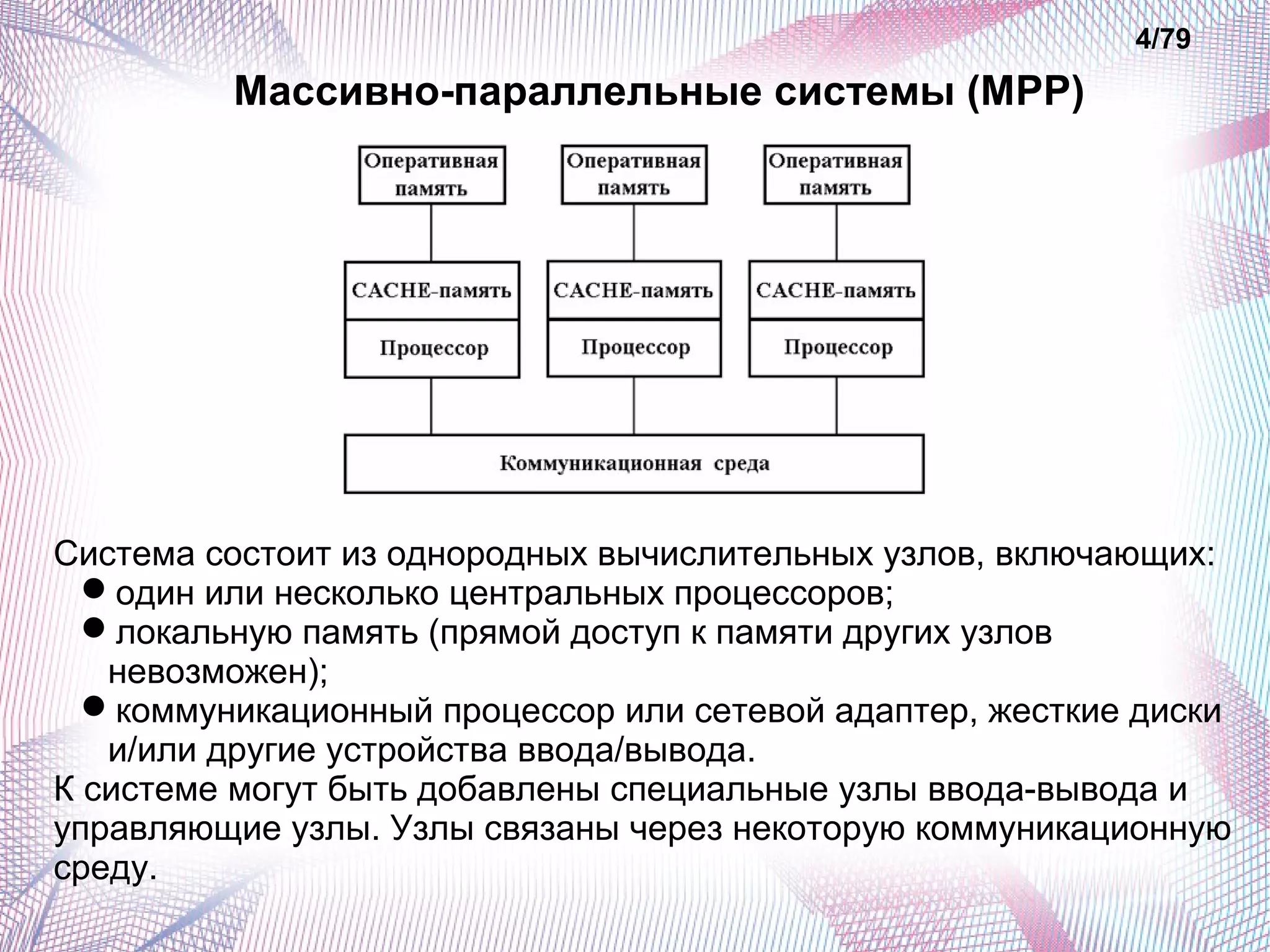
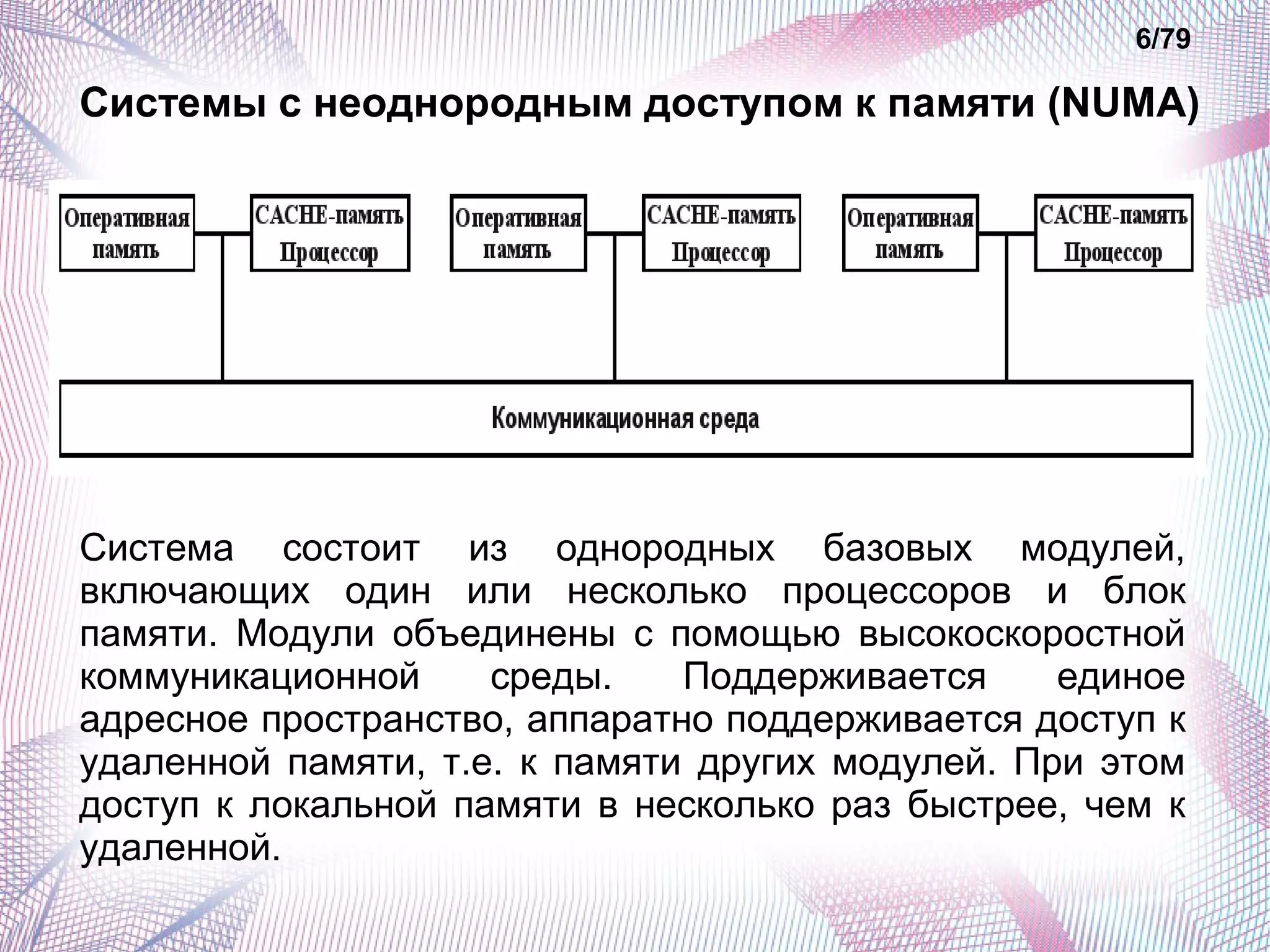
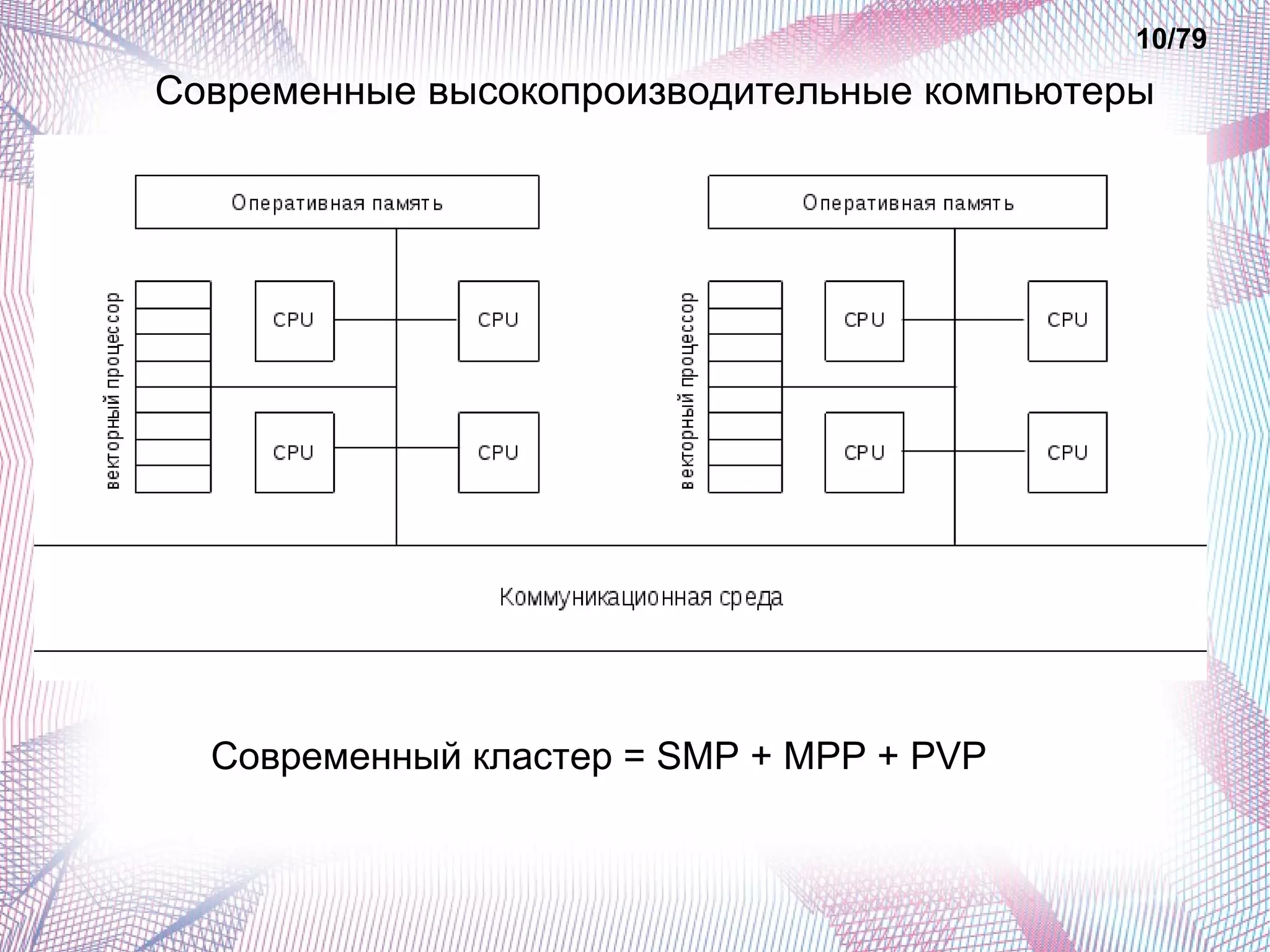
Документ описывает основные классы современных параллельных суперкомпьютеров, включая симметричные мультипроцессорные системы (SMP), массивно-параллельные системы (MPP), системы с неоднородным доступом к памяти (NUMA) и параллельно-векторные системы (PVP). Обсуждаются их архитектурные особенности, преимущества и недостатки, а также способы измерения производительности, такие как тесты Whetstone и Dhrystone. Также рассматриваются проблемы, с которыми сталкиваются кластеры суперкомпьютеров, такие как высокая стоимость и трудности с масштабируемостью.









































![[DD] 10. Memory](https://cdn.slidesharecdn.com/ss_thumbnails/10-210616162535-thumbnail.jpg?width=640&height=640&fit=bounds)

































