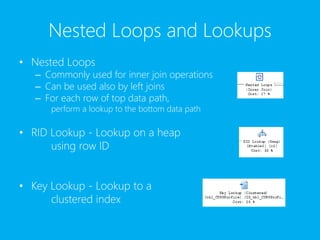
Microsoft SQL Server Performance Query Tuning focuses on execution plans and indexes. Execution plans detail how queries will be processed, including index usage and join methods. Common elements include scans, seeks, lookups, nested loops, hash and merge joins, and aggregations. Indexes provide efficient access paths between users and data. Clustered indexes store data in sorted order while nonclustered indexes reference data locations. Tips include limiting indexes, avoiding updates in indexes, and creating indexes for query predicates.