Downloaded 10 times









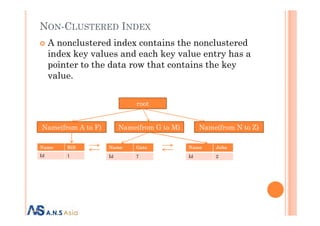







![SQLServer tools to improve performance.
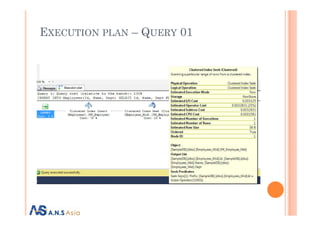
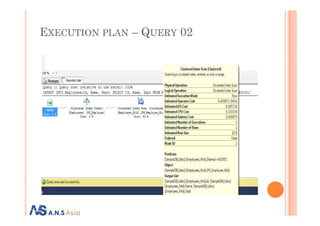
Execution plan
CREATE TABLE Employees
(
Id BIGINT NOT NULL,
Name VARCHAR(20) NOT NULL,
Dept VARCHAR(10),
CONSTRAINT [PK_Employee] PRIMARY KEY
CLUSTERED
(Id ASC)
)
CREATE TABLE Employees_Mid
(
Id BIGINT NOT NULL,
Name VARCHAR(20) NOT NULL,
Dept VARCHAR(10),
CONSTRAINT [PK_Employee_Mid] PRIMARY KEY
CLUSTERED
(Id ASC)
)
Query 01
INSERT INTO Employees(Id, Name, Dept)
SELECT Id, Name, Dept FROM Employees_Mid
WHERE Employees_Mid.Id = 1000
Query 02
INSERT INTO Employees(Id, Name, Dept)
SELECT Id, Name, Dept FROM Employees_Mid
WHERE Employees_Mid.Name = ‘A00001’](https://image.slidesharecdn.com/anssqlserverperformancetuning-final-140403053822-phpapp01/85/SQA-server-performance-tuning-17-320.jpg)
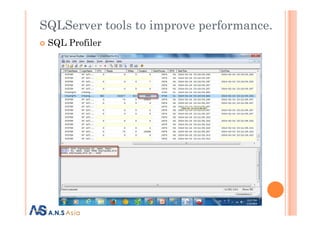



This document discusses SQL Server performance tuning. It covers indexing to improve query performance by creating indexes on frequently searched columns. It also discusses rewriting queries to use appropriate operators like = instead of intrinsic functions, and to rewrite subqueries as joins. SQL Server tools like execution plans and SQL Profiler can analyze queries and identify bottlenecks. The presenter is from ANS-ASIA, a software development company in Vietnam, and has 6 years of experience with SQL Server, .NET and other technologies.

























































































