Download as PDF, PPTX







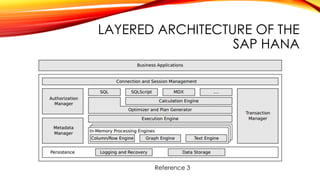














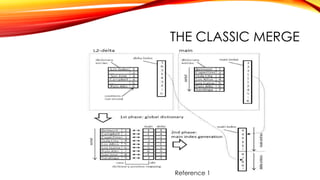



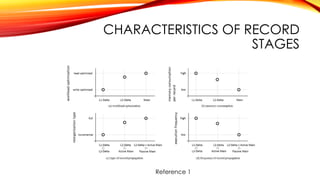



This document provides an overview of efficient transaction processing in SAP HANA. SAP HANA is an in-memory database that aims to provide both transactional and analytical query capabilities on the same data. It uses a layered architecture with data stored in L1, L2, and main stores that represent different levels of processing. Data is merged from L1 to L2 to main stores asynchronously in the background. This allows for efficient transaction processing and analytics by storing data in different optimized formats throughout this lifecycle.










































































